
InfluxDB has long been a leader in time-series. However, for higher performance and scale requirements, such as with high cardinality data and for better developer ergonomics, teams have started looking for a replacement.
But replacing a database can be tricky. They and their unique quirks are often deeply embedded in business logic. The easier the lift, the better.
To that tune, we're pleased to announce that with the newly released InfluxDB Line Protocol (ILP) over HTTP, QuestDB can now act as a drop-in ingestion replacement for InfluxDB use cases.
Let's see it in action!
Why move from InfluxDB?
But first, we should answer the burning question.
Why migrate at all?
Comparisons are tricky due to the broad array of overlapping products offered by Influx. And in the end, it always comes down to your team's specific needs.
But in most cases, time-series data appears in explosive volumes. If as a result, you've run into elevated Cloud or infrastructure costs, hit ingestion bottlenecks due to overall throughput requirements or high data cardinality, then QuestDB can help.
We'll touch on comparative points, but for focused comparisons then see:
- Comparing TimescaleDB and QuestDB performance and architecture blog
- QuestDB vs InfluxDB comparison page
- QuestDB vs InfluxDB internal comparison blog
Introducing ILP over HTTP
Previously, to use the InfluxDB Line Protocol to ingest data into QuestDB, teams had to either use the QuestDB client library or send data to the ILP TCP endpoint. While the TCP receiver was a performant and reliable option for those who wanted to use ILP, onboarding was inconvenient for existing InfluxDB users. They would have to refactor their codebase to use either the QuestDB clients or the TCP endpoint, both for ingest and query.
To significantly ease the friction, QuestDB now supports ILP over HTTP. Teams can update the URL in their existing InfluxDB clients to the QuestDB endpoint to see major gains in performance and cost savings. Minimal codebase refactoring required.
This guide will use the existing Influx clients. Soon the QuestDB clients will have native InflxuDB Line Protocol over HTTP support. Currently, they support TCP. Once updated, we strongly recommend using QuestDB clients over that of Influx.
InfluxDB client into QuestDB
In this demonstration, we will use the official InfluxDB 2 Go client.
You can use any of the supported languages such as Python, Rust or NodeJS.
The code itself is boiler plate from the Influx Go Client README example.
To start, we will create a new go mod.
For QuestDB Enterprise, see the documentation for auth instructions.
Enter: go mod init <mod-name> and create a main.go file:
package main
import (
"context"
"fmt"
"time"
influxdb2 "github.com/influxdata/influxdb-client-go/v2"
)
func main() {
// Create a new client using an InfluxDB server base URL and an authentication token
client := influxdb2.NewClient("http://localhost:9000", "")
// Use blocking write client for writes to desired bucket
writeAPI := client.WriteAPIBlocking("qdb", "test")
// Create point using full params constructor
p := influxdb2.NewPoint("stat",
map[string]string{"unit": "temperature"},
map[string]interface{}{"avg": 24.5, "max": 45.0},
time.Now())
// Write point immediately
writeAPI.WritePoint(context.Background(), p)
// Create point using fluent style
p = influxdb2.NewPointWithMeasurement("stat").
AddTag("unit", "temperature").
AddField("avg", 23.2).
AddField("max", 45.0).
SetTime(time.Now())
err := writeAPI.WritePoint(context.Background(), p)
if err != nil {
panic(err)
}
// Or write directly in line protocol
line := fmt.Sprintf("stat,unit=temperature avg=%f,max=%f", 23.5, 45.0)
err = writeAPI.WriteRecord(context.Background(), line)
if err != nil {
panic(err)
}
client.Close()
}
Key things to note:
- The client points to HTTP port 9000 instead of TCP port 9009
- You can pass in any or empty values for the token, org, and bucket
- Data is written in 3 different ways:
- full params constructor
- fluent style
- direct line protocol
Write data to QuestDB
With the above complete, we now have our client setup.
Next start up QuestDB:
docker run -d \
-p 9000:9000 -p 9009:9009 -p 8812:8812 -p 9003:9003 \
questdb/questdb:7.3.9
Once the database is ready to go, run our fake data client to send in data:
go run main.go
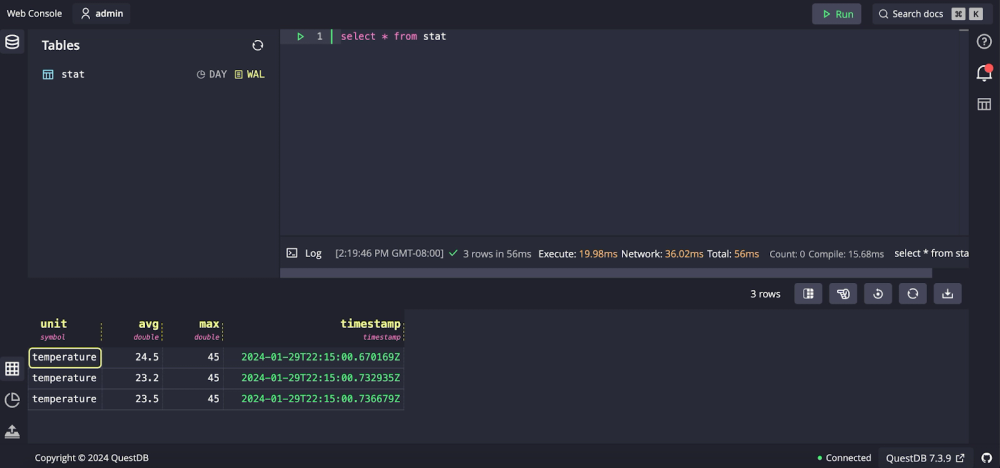
Navigate to the QuestDB console on: http://localhost:9000`
Our table is already created (stat).
We can then query the table to see that our data points ingested as expected:
We love feedback
The HTTP client will supply meaningful error messages.
To invoke one, change the type that we are sending into a string:
p = influxdb2.NewPointWithMeasurement("stat").
AddTag("unit", "temperature").
AddField("avg", "23.2").
AddField("max", "45.0").
SetTime(time.Now())
err := writeAPI.WritePoint(context.Background(), p)
if err != nil {
panic(err)
}
The expected behaviour is the receipt of a double, as per:
...
AddField("avg", 23.2).
AddField("max", 45.0).
...
However, now they are strings:
...
AddField("avg", "23.2").
AddField("max", "45.0").
...
When we run the app again, we see helpful error feedback:
panic: invalid: failed to parse line protocol:errors encountered on line(s):
error in line 1: table: stat, column: avg; cast error from protocol type: STRING to column type: DOUBLE
Compare vs. prior QuestDB ILP client
It's neat to see how easily the InfluxDB client can now connect to QuestDB.
Compared to before, what does our new endpoint get us?
Anything else beyond simplicity? Yes!
To demonstrate, we will replicate the scenario using the QuestDB Go client:
package main
import (
"context"
"log"
qdb "github.com/questdb/go-questdb-client/v2"
)
func main() {
ctx := context.TODO()
// Connect to QuestDB running on 127.0.0.1:9009
sender, err := qdb.NewLineSender(ctx)
if err != nil {
log.Fatal(err)
}
// Make sure to close the sender on exit to release resources.
defer sender.Close()
// Send a few ILP messages.
err = sender.
Table("stat").
Symbol("unit", "temperature").
Float64Column("avg", 24.1).
Float64Column("max", 46.7).
AtNow(ctx)
if err != nil {
log.Fatal(err)
}
// Make sure that the messages are sent over the network.
err = sender.Flush(ctx)
if err != nil {
log.Fatal(err)
}
}
While the code is simple in both cases, the QuestDB Go client necessitated a few code level changes. The client needs to be aware of QuestDB syntax, such as table, symbol and float64column.
While the prior method performs well, there is very little feedback offered.
This is in large part due to TCP. For example, if we updated our program to
include invalid columns - changing Float64Column to StringColumn - we will
not return errors. They are unfortunately swallowed on the receiving end. This
is not ideal, especially for streaming cases where reliability is paramount.
For teams already heavily invested in InfluxDB, it was clear that a more streamlined approach to QuestDB adoption would be helpful. Now, migration requires only updating the URL in the existing InfluxDB ILP clients to one that belongs to QuestDB.
There's more!
The baseline change to HTTP also comes with other new features, in addition to error handling.
Precision
Pass precision parameters in the query request string:
curl -i -XPOST 'http://localhost:9000/write?db=mydb&precision=s' \
--data-binary 'weather,location=us-midwest temperature=82 1465839830100400200'
Precision parameters include n or ns for nanoseconds, u or us for
microseconds, ms for milliseconds, s for seconds, m for minutes and h
for hours. Otherwise, it will default to nanoseconds.
Ping!
Is your server running? Well then you'd better... catch it!
In all seriousness, a health check endpoint is always of high usefulness.
curl -I http://localhost:9000/ping
Returns (pong!):
HTTP/1.1 204 OK
Server: questDB/1.0
Date: Fri, 2 Feb 2024 17:09:38 GMT
Transfer-Encoding: chunked
Content-Type: text/plain; charset=utf-8
X-Influxdb-Version: v2.7.4
Chunking & multi-part requests
Included in our above ping response is Transfer-Encoding:chunked.
The size of each chunk is sent right before the chunk itself. Chunking allows the server to send responses in chunks of data, so that it may start sending data before it has finished generating the entire response. When you're after high-performance streaming, chunking - along with clear errors and health checks - help ensure your streams stay alive and at their peak.
Comparing database storage architecture
New features are interesting. But back to InfluxDB and QuestDB. If one is faster, why? What are the tradeoffs? To start, there are major differences in storage architecture.
InfluxDB storage architecture
InfluxDB uses Time-Structured Merge (TSM) Trees. This means it stores data in a columnar format and records the differences (or deltas) between values in a series. InfluxDB also employs a time-series index to maintain fast query speeds, even as the number of data points (cardinality) increases. However, there are efficiency limits in this method and cardinality in particular can quickly degrade performance.
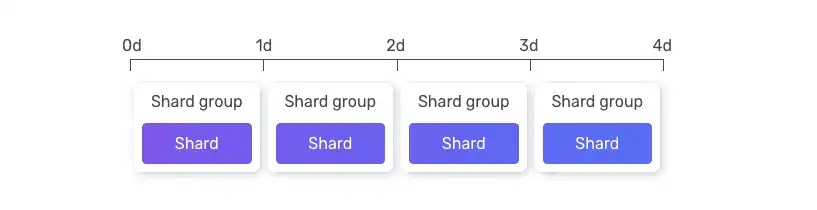
For partitioning, InfluxDB uses the concept of 'shard groups'. Operators set a 'shard group duration' to determine the size of each shard. This is useful for managing data, like setting retention periods to, say, automatically delete data older than a certain time.
QuestDB storage architecture
QuestDB also uses a columnar data structure. However, it indexes data in vector-based append-only column files. Out-of-order data is initially sorted in memory, and then sorted data is merged with persisted data. This method is designed to optimize both read and write operations.
This allows operators to partition tables by time, similar to InfluxDB. However, in QuestDB, when a table is partitioned by time, the metadata is set once per table and the data files are then organized into different directories for each time partition.
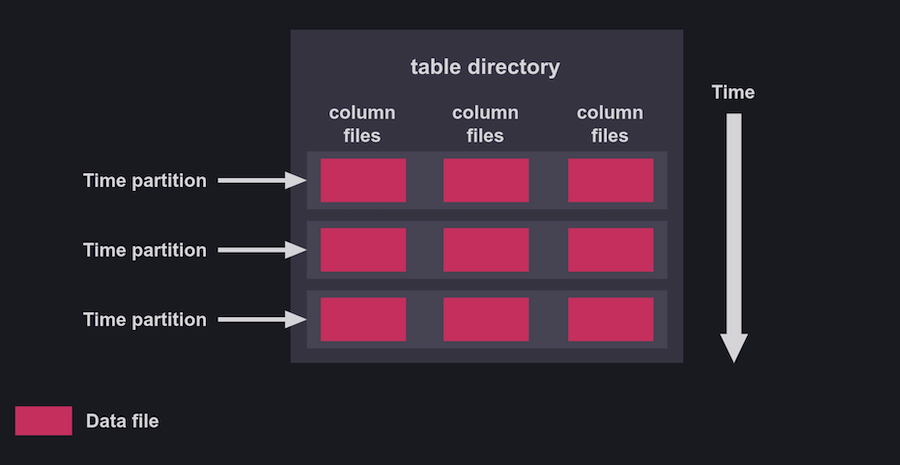
Thus both databases partition data by time and support data retention strategies. However, the main difference lies in how they handle these partitions.
InfluxDB creates separate TSM files for each partition, while QuestDB partitions data at the filesystem level, without needing separate files for each partition.
This approach focuses on the storage of deltas between series values, whereas QuestDB's append-only model emphasizes performance in both reading and writing operations by handling out-of-order data in memory first.
To continue the deep dive, see our thorough architecture comparison article.
Practical consequences
Apart from "one thing is faster", what are the consequences of differing storage models? If you want to migrate, what is the fundamental difference in data-in?
InfluxDB exports only one metric for each line. If we store more than one metric
for the same series, one row will create multiple ILP lines with one valid
metric value. The other metrics then show as NULL. Therefore once data arrives
into QuestDB, we recommend you transform it.
For example, if you query a table with several metrics:
SELECT * FROM diagnostics WHERE timestamp = '2016-01-01T00:00:00.000000Z' AND driver='Andy' AND name='truck_150')
Your result may be something like this:
| device_version | driver | fleet | model | current_load | timestamp | fuel_capacity | fuel_state | load_capacity | nominal_fuel_consumption | status | name |
|---|---|---|---|---|---|---|---|---|---|---|---|
| v1.0 | Andy | West | H-2 | null | 2016-01-01T00:00:00.000000Z | null | null | 150 | null | null | truck_150 |
| v1.0 | Andy | West | H-2 | null | 2016-01-01T00:00:00.000000Z | null | null | 150 | 12 | null | truck_150 |
| v1.0 | Andy | West | H-2 | null | 2016-01-01T00:00:00.000000Z | null | null | 150 | null | null | truck_150 |
| v1.0 | Andy | West | H-2 | 0 | 2016-01-01T00:00:00.000000Z | null | null | 150 | null | null | truck_150 |
| v1.0 | Andy | West | H-2 | null | 2016-01-01T00:00:00.000000Z | 150 | null | 150 | null | null | truck_150 |
| v1.0 | Andy | West | H-2 | null | 2016-01-01T00:00:00.000000Z | null | 1 | 150 | null | null | truck_150 |
Very null-y!
To solve this:
- Apply a SQL query to group data by all dimensions
- Select the maximum values for all the metrics
As shown in the following:
SELECT
timestamp,
device_version,
driver,
fleet,
model,
name,
max(current_load) AS current_load,
max(fuel_capacity) AS fuel_capacity,
max(fuel_state) AS fuel_state,
max(load_capacity) AS load_capacity,
max(nominal_fuel_consumption) AS nominal_fuel_consumption,
max(status) AS status
FROM
diagnostics;
This produces aggregated rows containing all the metrics for each dimension group:
| timestamp | device_version | driver | fleet | model | name | current_load | fuel_capacity | fuel_state | load_capacity | nominal_fuel_consumption | status |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016-01-01T00:00:00.000000Z | v1.0 | Derek | East | G-2000 | truck_3248 | 0 | 300 | 1 | null | null | null |
| 2016-01-01T00:00:00.000000Z | v1.0 | Derek | East | G-2000 | truck_2222 | 0 | 300 | 1 | 5000 | 19 | 0 |
| 2016-01-01T00:00:00.000000Z | v1.0 | Derek | East | G-2000 | truck_1886 | 0 | 300 | 1 | 5000 | 19 | 0 |
| 2016-01-01T00:00:00.000000Z | v1.0 | Derek | East | G-2000 | truck_1540 | 0 | 300 | 1 | 5000 | 19 | 0 |
| ... (rows continue) ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2016-01-01T00:00:00.000000Z | v1.0 | Andy | West | H-2 | truck_583 | 0 | 150 | 1 | 1500 | 12 | 0 |
| 2016-01-01T00:00:00.000000Z | v1.0 | Andy | West | H-2 | truck_3546 | 0 | 150 | 1 | 1500 | 12 | 0 |
| 2016-01-01T00:00:00.000000Z | v1.0 | Andy | West | H-2 | truck_3247 | 0 | 150 | 1 | 1500 | 12 | 0 |
You can then use the INSERT keyword to output the processed result into a new table. Nice and clean!
What about queries?
Full ILP support in QuestDB eases migration friction and provides significant improvement when we consider ingestion. But data-in is half the battle. What about data-out?
To handle time-series data, InfluxDB has deployed two iterations of a query language: InfluxQL & Flux. QuestDB supports SQL analytics.
SQL is widely known. It is clean, powerful and readable. When supplemented with powerful time-series analytics, it remains the defacto standard for data-out, even in time-based cases.
A common example is the ASOF JOIN.
As per the syntax, we JOIN two columns together "AS OF" a time period.
Within Flux, an ASOF JOIN would be written as such:
f1 = from(bucket: "example-bucket-1")
|> range(start: "-1h")
|> filter(fn: (r) => r._field == "f1")
|> drop(columns: "_measurement")
f2 = from(bucket: "example-bucket-2")
|> range(start: "-1h")
|> filter(fn: (r) => r._field == "f2")
|> drop(columns: "_measurement")
union(tables: [f1, f2])
|> pivot(
rowKey: ["_time"],
columnKey: ["_field"],
valueColumn: "_value"
)
Within QuestDB, the same query is written as:
SELECT a.timestamp, f1, b.timestamp, f2
FROM 'example-table-1' a
ASOF JOIN 'example-table-2' b;
Adapting your existing application to a different query pattern is - naturally - additional overhead. However, it is a worthwhile price to pay if in addition to the ease of SQL and the power of its simple extensions, there are also performance improvements and cost savings on the other side.
More to come
Our goal is to be balanced. We believe QuestDB is worthy alternative to InfluxDB in time-series workloads. However, as QuestDB is an emerging database there are aspects that are slated for near-term improvement.
Depending on your configuration, migration may require more application changes due to what is currently less overall tooling support in the emerging QuestDB ecosystem. As a mature product, InfluxDB provides a robust tooling ecosystem.
For example, if you use InfluxDB for infrastructure monitoring and use third party tools that read data, you will also need to migrate your queries. If you were to use, say Telegraf, then QuestDB is indeed a drop in replacement for ingestion. But it can be more involved.
As of writing, ILP over HTTP requires WAL enabled tables and does not provide full transactionality in all cases. Specifically:
-
If an HTTP request contains data for two tables and the final commit fails for the second table, the data for the first table will still be committed. This is a deviation from full transactionality, where a failure in any part of the transaction would result in the entire transaction being rolled back.
-
When using the InfluxDB Line Protocol (ILP) to add new columns to a table, an implicit commit occurs each time a new column is added. If the request is aborted or has parse errors, this commit cannot be rolled back.
In addition, authentication is not yet supported - hence why we passed arbitrary
values for the token, org, and bucket in our example. Neither can db
parameters be included to alter the underlying QuestDB instance.
However, even with the temporary caveats it has never been easier to jump from the Influx ecosystem into something new... and very, very fast.
Summary
This guide introduces support for InfluxDB Line Protocol over HTTP. It will soon become the default client mechanism for bringing data to QuestDB. We provided and example and also dug a little into queries and storage internals. And we admitted to fair caveats.
For more information on the jump over to QuestDB, checkout our migration guide. If you need a hand, we'd love to help. Just drop by our public Slack and say hello!