Choosing the right database is a careful exercise. We feel the best way to help you cut through the marketing noise is to provide the most rigorous benchmarks available, and then to put the results in context.
To that end, this article contains a deep performance comparison of TimescaleDB and QuestDB.
Introducing TimescaleDB & QuestDB
If you're after a high performance time series database, you've likely come across TimescaleDB. Both Timescale & QuestDB aim to help developers scale time series workloads.
According to DB-Engines, the two breakdown as such:
| Feature | TimescaleDB | QuestDB |
|---|---|---|
| Primary database model | Time Series DBMS | Time Series DBMS |
| Implementation language | C | Java (low latency, zero-GC), C++, Rust |
| SQL? | Yes | Yes |
| APIs and other access methods | ADO.NET, JDBC, native C library, ODBC, streaming API for large objects | InfluxDB Line Protocol, Postgres Wire Protocol, HTTP, JDBC |
TimescaleDB is a time series database built atop PostgreSQL. It's provided under two licences: Apache 2.0 and the proprietary Timescale License. It's an extension of PostgreSQL, rather than a standalone database. For many in the PostgreSQL eco-system, it provides a clean jump into time series, and is more simple than the current incumbent, InfluxDB.
Want to see a comparison vs. InfluxDB? Read the article
On the other side, QuestDB is an open-source time series database licensed under Apache License 2.0. It's built from the ground up for maximum performance and ease-of-use, and has been tempered against the highest throughput, highest cardinality ingestion cases. It also offers very fast querying, accessible via SQL-based extensions.
Performance benchmarks
Before we get into internals, let's compare how QuestDB and TimescaleDB handle both ingestion and querying. As usual, we use the industry standard Time Series Benchmark Suite (TSBS) as the benchmark tool.
Ingestion benchmark results
Starting with ingestion, how do the two compare?
The hardware used is the following:
-
c6a.12xlarge EC2 instance with 48 vCPU and 96 GB RAM
-
500GB gp3 volume configured for the maximum settings (16,000 IOPS and 1,000 MB/s throughput)
And on the software side:
-
Ubuntu 22.04
-
TimescaleDB 2.14.2, tuned. Instead of using the default, we apply the TimescaleDB tuning tool for an optimal comparison.
-
QuestDB 7.3.10 with the out-of-the-box configuration
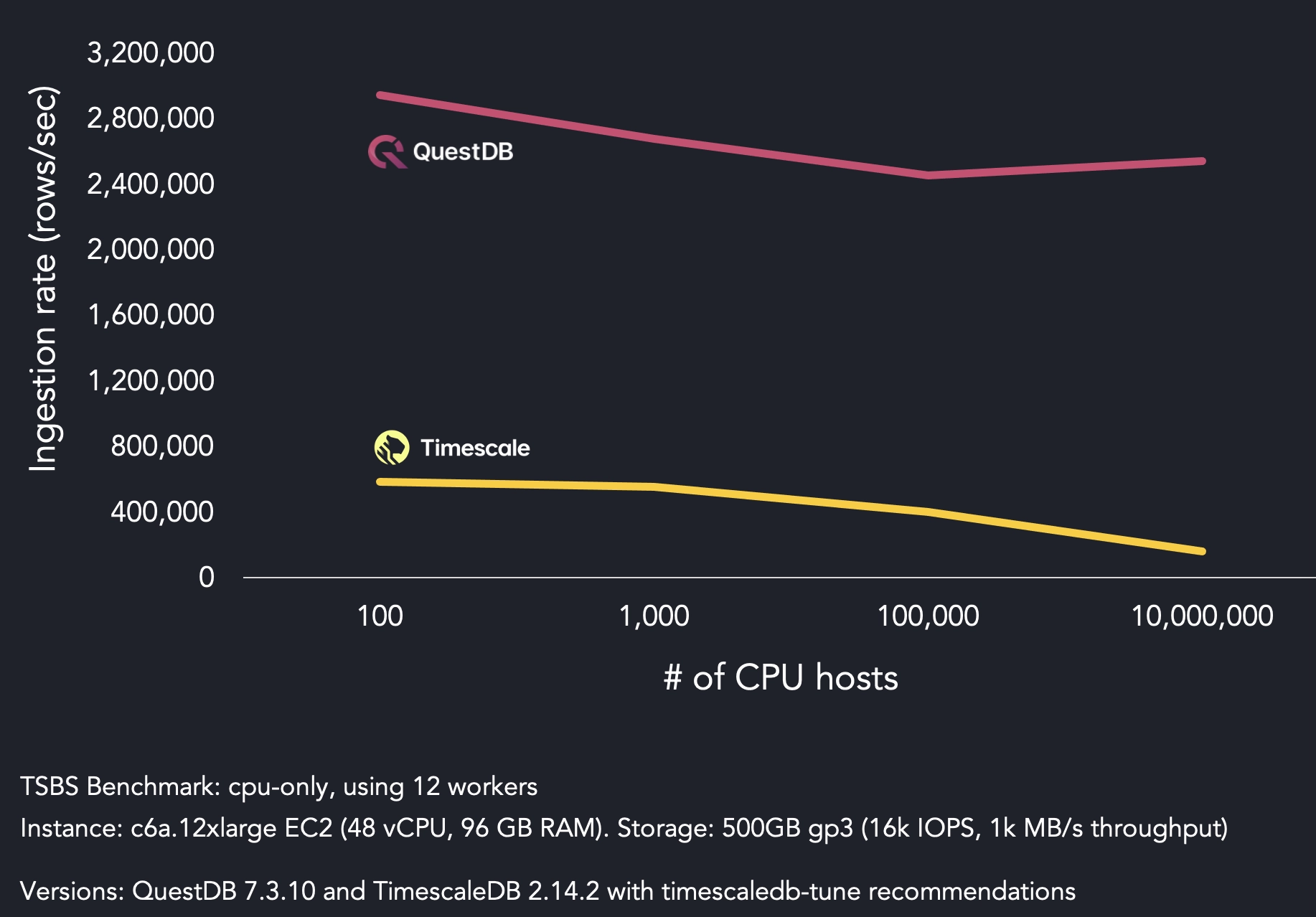
The benchmark compares ingestion speed between QuestDB and TimescaleDB. There are 12 workers sending data with 100 to 10 million unique emulated host IDs. The data is sent concurrently over 12 connections. The higher the number of unique host IDs, the greater the dataset cardinality.
QuestDB sustains an ingestion rate above 2.4 million rows per second throughout the entire benchmark, without seeing a significant drop in ingestion speed as the number of unique host IDs increases beyond 100,000.
On the other hand, Timescale's performance degrades from 1,000 CPU hosts onward. Timescale's ingestion speed reaches 557K rows per second for 1,000 hosts, then starts dropping to 402K rows per second for 100,000 hosts. The worst outcome is 159K rows per second for 10 million hosts.
In most benchmarks in the time series space, high cardinality data is where performance profiles start to really diverge. For high cardinality scenarios such as 10 million CPU hosts, QuestDB's ingestion rate is 16x superior to TimescaleDB.
It should be noted that TimescaleDB's performance degradation at high cardinality is not inherently due to PostgreSQL, but rather the challenges of scaling time-series data in a row-based system.
Query benchmark results
As part of the standard TSBS benchmark, we test several types of popular time series queries:

To run the benchmark, we apply TSDB like so:
$ ./tsbs_generate_queries --use-case="cpu-only" --seed=123 --scale=4000 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --queries=1000 --query-type="single-groupby-1-1-1" --format="timescaledb" /tmp/timescaledb_query_single-groupby-1-1-1
$ ./tsbs_run_queries_timescaledb --file=/tmp/timescaledb_query_single-groupby-1-1-1 --workers=1 —pass=<password>
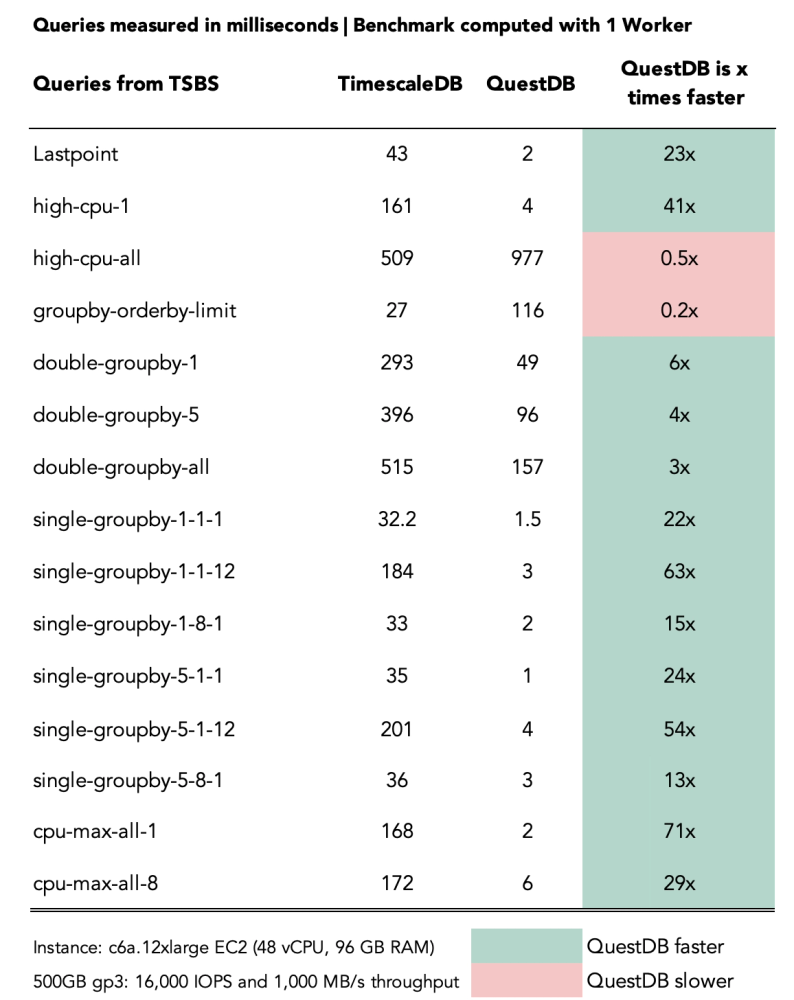
For most queries, QuestDB significantly outperforms TimescaleDB by factors ranging from 3x up to 71x.
TimescaleDB outperforms QuestDB on two queries:
-
groupby-orderby-limit: QuestDB is missing an optimization, which is being addressed. -
high-cpu-all: this query returns a large result set (over 380K rows) - improvements also pending!
"OLAP" query benchmarks
Although time series databases are optimized for time-based queries, established benchmarks cast a net wider. They include a range of "Online Analytical Processing (OLAP)" queries and several time-based queries. This holds true for the Clickbench benchmark.
Want to know more? Checkout OLAP vs Time Series Databases: The SQL Perspective
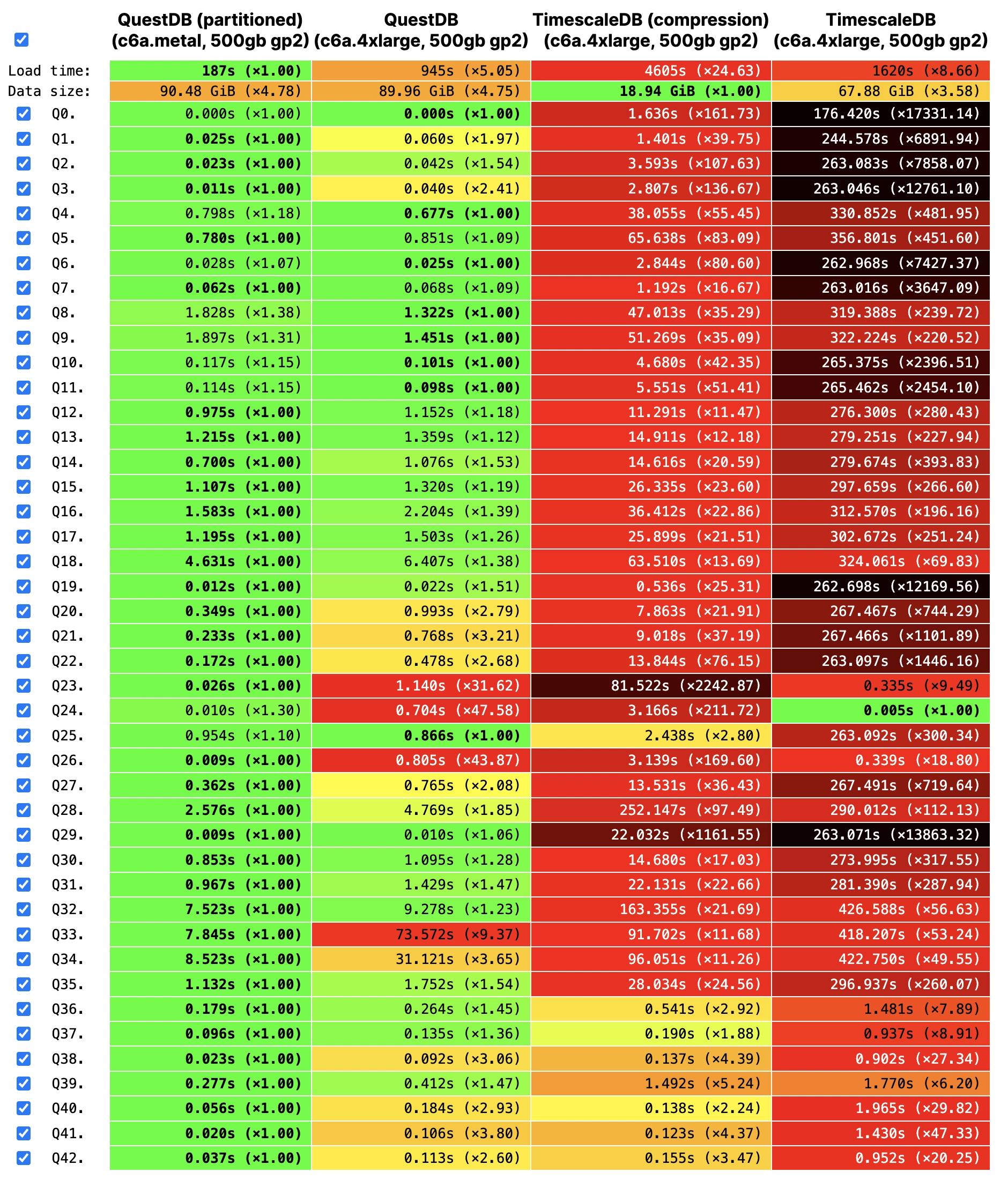
The most recent benchmark includes both QuestDB partitioned and non-partitioned.
Time-based partitions are necessary for performant time-based queries such as
query n.24 and n.26, ordered by EventTime. Regarding Timescale, there is the
open-source implementation without compression and the version with compression
under the Timescale License.
Across most queries, QuestDB outperforms Timescale by a factor of 10x up to 150x:
Architecture overview
The results tell a story.
But what's under-the-hood that leads to these outcomes?
TimescaleDB overview
TimescaleDB extends PostgreSQL's row-based architecture, incorporating a columnar format for compressed, historical data. This contrasts with the purely columnar architectures of DuckDB, InfluxDB 3.0, and QuestDB, which generally offer better performance for analytical workloads.
It leverages SQL's capabilities, including joins, secondary and partial indexes, and integrates with other extensions like PostGIS, enhancing PostgreSQL's performance for time series data. However, its performance comparisons are relative to PostgreSQL rather than a specialized time series databases. As such, TimescaleDB's PostgreSQL compatibility is a double-edged sword.
TimescaleDB uses "hypertables" to manage large datasets, automatically partitioning them into "chunks" based on time intervals and - optionally - space. These chunks, essentially smaller tables, store data within specific time frames, facilitating efficient data management.
Timescale's own best practices recommend sizing chunks to balance memory efficiency with query performance, avoiding overly small chunks that can degrade query planning and compression.

A key aspect of hypertables are unique indexes that include all partitioning keys. This ensures global data uniqueness, but it also introduces additional complexity and performance overhead. Managing unique indexes can become challenging when repartitioning data or altering partition keys. These operations may require heavy operations to drop and recreate indexes.
There's also an inherent performance cost to maintaining a unique index. The database must check for uniqueness each time a row is inserted or updated. This overhead is exacerbated when the unique index includes additional partitioning columns.
Furthermore, writing data in row-based format organized around native Postgres format (B-Tree + heap file) is not as efficient in general as a strictly column-based format.
All told, when compared to Postgres itself, Timescale adds a powerful time series dimension. However, when down in the "deep end" of time series, the core limitations become more clear.
QuestDB architecture
QuestDB is positioned as a high-performance, open-source time series database (TSDB) developed using Java, C++, and Rust. It combines the convenience of the InfluxDB Line Protocol with SQL's familiarity, ensuring users enjoy both flexibility and ease when querying and a tried-and-true protocol for high-volume ingestion.
At its core, QuestDB employs a robust column-based storage model, designed to handle data in time-sorted partitions. These partitions are append-only and versioned, ensuring efficient memory use and query speed by loading only the latest data version relevant to the query's time constraints.
In developing QuestDB from the ground-up for intensive workloads, the team focused on:
-
Performance: QuestDB is built for high-throughput. It performs well even with the highest cardinality datasets. Query speeds are accelerated using SIMD instructions for row aggregation, a custom JIT compiler for parallelizing query filters, and time-partitioned data storage to minimize in-memory data during reads.
-
Flexibility: QuestDB provides schema-less ingestion, allowing for the dynamic addition of new columns without pre-defined schemas. In addition, when handling multiple data-streams, users benefit from concurrent schema changes without compromising writes.
-
Compatibility: As an alternative to InfluxDB, QuestDB supports the InfluxDB line protocol, alongside PGwire, REST API, and CSV uploads, ensuring broad interoperability. It also offers high performance client libraries in various programming languages.
-
Enhanced SQL Querying: Beyond standard SQL, QuestDB incorporates time series-specific SQL extensions, making it easier to manage and query time series data effectively.
All together, QuestDB is purpose built both for performance and to leverage proven patterns learned from those developing against the most demanding time series use cases.
TimescaleDB limitations
Both databases have their strengths.
And so too, each has their own limitations.
We'll start with TimescaleDB.
Temporal JOINs and missing time-based extensions
Timescale does not support joining tables based on the nearest timestamp, also known as ASOF JOIN. These joins are heavily used and relied upon in financial markets.
TimescaleDB also lacks some easy ways to manipulate time series data. For example, retrieving the latest data for a given attribute/channel in the data (such as currency pair or sensor type) involves computing expensive lateral joins.
Checkout the difference:
- QuestDB
- PostgreSQL and Timescale
-- QuestDB provides ASOF JOIN. Since table definition includes
-- the designated timestamp column, no time condition is needed
SELECT t.*, n*
FROM trades ASOF JOIN news ON (symbol);
-- Postgresql and timescale offer no ASOF JOIN support,
-- but we can use a LEFT JOIN LATERAL and filter by time using DISTINCT
SELECT t.*, n.*
FROM trades t LEFT JOIN LATERAL (
SELECT DISTINCT ON (news.symbol) *
FROM news n1
WHERE n1.symbol = t.symbol
AND n1.timestamp <= news.timestamp
ORDER BY n1.symbol, n1.timestamp DESC) n
-- DuckDB provides the ASOF JOIN extension
SELECT t.*, n*
FROM trades t ASOF JOIN news n
ON t.symbol = n.symbol;
Additionally, there are no built-in functions to deal with periodic intervals. Timescale does however offer continuous aggregate views. These views pre-aggregate data into summary tables, optimizing queries that compute statistics over fixed time intervals.
Schema change overhead
Schema adjustments in TimescaleDB, though possible through
ALTER TABLE ADD COLUMN operations, are not without their drawbacks. These
modifications increase in pain with the scale of the database, primarily due to
the extensive re-indexing required by PostgreSQL for both old and new rows.
Ingestion performance
TimescaleDB's performance guidance splits into general PostgreSQL enhancements and specific TimescaleDB optimizations. The advice spans from judicious index use to maintain query performance without sacrificing insert speed, to reconsidering the necessity and impact of foreign key constraints on ingestion rates. Unique keys, while valuable for data integrity, introduce significant overhead if used too often.
In essence, while TimescaleDB inherits the robustness and reliability of PostgreSQL, it requires a nuanced approach to database management and optimization to fully leverage its capabilities against time series data.
High cardinality data
The ingestion rate of TimescaleDB suffers with high cardinality datasets, characterized by a significant number of unique time series. The platform's row-based ingestion mechanism and heavy reliance on indexing for query execution contribute to this inefficiency.
TimescaleDB's approach to mitigating this involves a counterintuitive recommendation to minimize the use of indices, foreign keys, and unique keys—elements traditionally considered strengths of PostgreSQL.
PostgreSQL Extension?
Finally, installing TimescaleDB has layers. First, install PostgreSQL. Then, install the TimescaleDB extension. Finally configure/fine tune TimescaleDB for time series workloads. In comparison, QuestDB is ready to be used out of the box and is dependency-free.
When abstracted away via a Cloud platform, it's less of an issue. But when self-hosting, it's another layer of maintenance.
QuestDB limitations
Next, for QuestDB.
Type of workload & use case
Row-based databases such as Timescale's PostgreSQL foundation, excel in Online Transaction Processing (OLTP) scenarios characterized by frequent, transactional data modifications.
Columnar databases, on the other hand, are optimized for Online Analytical Processing (OLAP) workloads, which involve high-volume data ingestion and complex queries typical in data analysis tasks.
TimescaleDB supports typical OLTP operations such as INSERT, UPSERT, UPDATE,
DELETE, and triggers. QuestDB is not an OLTP database, designed to process
transactional workloads. Therefore, you won't see DELETE or triggers.
QuestDB instead excels at OLAP & time series use cases which require high ingest throughput, fast availability for querying data, and snappy time-based queries. These use cases appear often in financial services (market data related use cases), IoT (sensor data use cases), and Ad-Tech.
As a by-product, QuestDB is not a strong fit for OTLP cases, nor a strong fit for observability workloads or log monitoring.
Weaker PostgreSQL compatibility
In most cases, QuestDB can utilize existing PostgreSQL libraries and tools, given its support for PGWire. However, there are limitations. One such example is in QuestDB's handling of cursor commands.
QuestDB does not support scrollable cursors that require explicit creation and
management through DECLARE CURSOR and subsequent operations like FETCH.
Instead, QuestDB supports non-scrollable, or "forward-only", cursors.
This distinction means that while you can iterate over query results sequentially, you cannot navigate backwards or access result positions as you might with scrollable cursors in PostgreSQL.
As a result, some PostgreSQL drivers and libraries that rely on scrollable cursors may not be fully compatible with QuestDB. For instance, psycopg2 — a popular PostgreSQL driver for Python — utilizes scrollable cursors extensively.
Emerging ecosystem
QuestDB released toward the end of 2019. Compared to Timescale, which has been released since 2016, QuestDB is in an earlier stage of its overall ecosystem. Timescale has made the most of their head start, and as such has a wider array of features.

Consequently, QuestDB offers fewer integrations with known developer tools and lacks features such as continuous queries and compression in open source. These are roadmapped features, however they are currently not available or are available in the closed-source edition.
Which leads into..
Closed source features
Several additional QuestDB features are closed-source under a proprietary license. These include replication, role-based access control, TLS and compression. This is also true for Timescale.
Conclusion
As with all databases, choosing the "perfect" one depends on your business requirements, data model, and use case.
TimescaleDB is a natural fit for existing PostgreSQL users. However, being built on top of PostgreSQL it is at its core less optimized for time series and analytical workloads. Simply put, it is crushed in many common performance metrics.
QuestDB is less mature as an overall ecosystem. But if performance is of any concern, then it's available as an attractive, developer-friendly database for demanding workloads. The community is active, enthusiastic and growing rapidly.
Many marketing pages make grand performance claims. But until your prospective database contains your own data and is hosted in your own infrastructure, you just won't know.
To that end, give QuestDB a try or consider a contribution.