
Introduction
In this tutorial, we’ll take a look at three different ways to ingest crypto market data into QuestDB for further analysis:
- Using the Cryptofeed library
- Writing a custom data pipeline
- Via Change Data Capture (CDC)
Prerequisites
We will be using QuestDB to ingest and store crypto market data. Create a new directory and from the directory, run the following to start a local instance of QuestDB:
mkdir cryptofeed-questdb
cd cryptofeed-questdb
docker run \
-p 9000:9000 -p 9009:9009 -p 8812:8812 -p 9003:9003 \
-v "$(pwd):/var/lib/questdb" \
questdb/questdb:7.0.1
Method 1: ingesting data using the Cryptofeed library
One of the easiest ways to ingest market data is to use an open-source tool called Cryptofeed. The Python library establishes websocket connections to various exchanges including Binance, Coinbase, Gemini, and Kraken and returns trade, market, and book update data in a standardized format. Cryptofeed also has native integration with QuestDB, making it a great choice to ingest data rapidly.
To get started, create a virtual environment with Python 3.8+. We will use venv but you can use conda, poetry, or virtualenv as well. We will create a venv for cryptofeed:
$ python3 -m venv cryptofeed
$ source cryptofeed/bin/activate
Then install cryptofeed: pip install cryptofeed
Navigate into the cryptofeed directory and create a new file questdb.py. We
will then paste the following to ingest trade data for BTC-USD pair from
Coinbase and Gemini:
from cryptofeed import FeedHandler
from cryptofeed.backends.quest import TradeQuest
from cryptofeed.defines import TRADES
from cryptofeed.exchanges import Coinbase, Gemini
QUEST_HOST = '127.0.0.1'
QUEST_PORT = 9009
def main():
f = FeedHandler()
f.add_feed(Coinbase(channels=[TRADES], symbols=['BTC-USD'], callbacks={TRADES: TradeQuest(host=QUEST_HOST, port=QUEST_PORT)}))
f.add_feed(Gemini(channels=[TRADES], symbols=['BTC-USD'], callbacks={TRADES: TradeQuest(host=QUEST_HOST, port=QUEST_PORT)}))
f.run()
if __name__ == '__main__':
main()
When you run this code, it will automatically create a socket connection with Coinbase and Gemini API and push data to QuestDB. Note that it may take a while to see data populated (especially from Gemini).
Navigate to localhost:9000 to access the web console. We can query data from
Coinbase via SELECT * FROM trades-COINBASE:
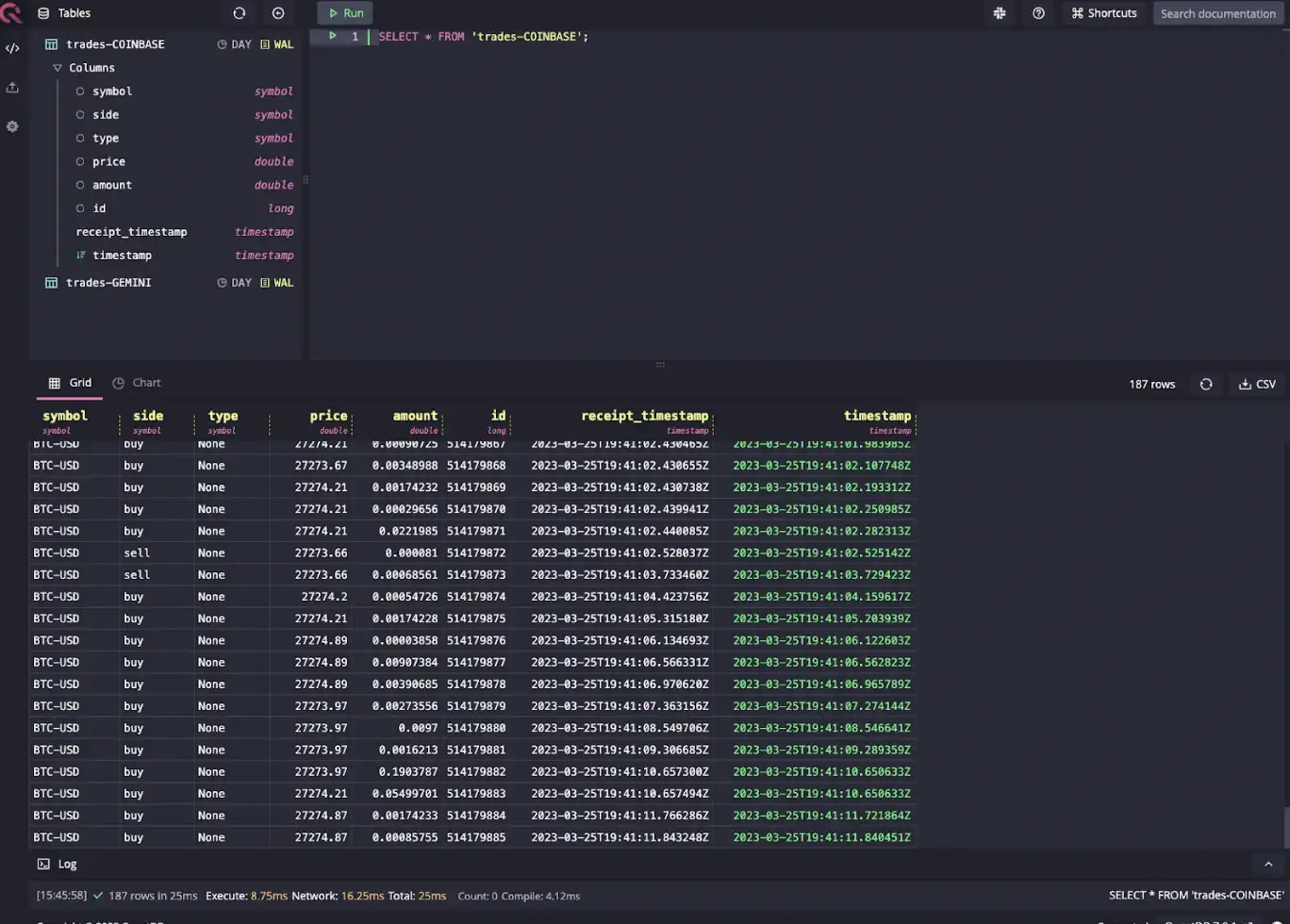
You can see all the supported exchanges and supported channels (e.g., L1/L2/L3 books, trades, ticket, candles, open interest, etc) on the Cryptofeed GitHub page.
If you want to modify the structure of the data ingested into QuestDB, you can
override the callback handler. For example, if you want to change the name of
the table it writes to or the columns, you can specify the write function. In
fact, the QuestDB demo site implements
cryptofeed to ingest data to the trades table with the following custom
callback function:
from cryptofeed import FeedHandler
from cryptofeed.backends.backend import BackendCallback
from cryptofeed.backends.socket import SocketCallback
from cryptofeed.defines import TRADES
from cryptofeed.exchanges import Coinbase
QUEST_HOST = '127.0.0.1'
QUEST_PORT = 9009
class QuestCallback(SocketCallback):
def __init__(self, host='127.0.0.1', port=9009, **kwargs):
super().__init__(f"tcp://{host}", port=port, **kwargs)
self.numeric_type = float
self.none_to = None
async def writer(self):
while True:
try:
await self.connect()
except:
exit(-1)
async with self.read_queue() as update:
update = "\n".join(update) + "\n"
try:
self.conn.write(update.encode())
except:
exit(-2)
class TradeQuest(QuestCallback, BackendCallback):
default_key = 'trades'
async def write(self, data):
update = f'{self.key},symbol={data["symbol"]},side={data["side"]} price={data["price"]},amount={data["amount"]} {int(data["timestamp"] * 1_000_000_000)}'
await self.queue.put(update)
def main():
handler = FeedHandler()
handler.add_feed(Coinbase(channels=[TRADES], symbols=['BTC-USD', 'ETH-USD'],
callbacks={TRADES: TradeQuest(host=QUEST_HOST, port=QUEST_PORT)}))
handler.run()
if __name__ == '__main__':
main()
Underneath the hood, cryptofeed library utilizes plain socket connections via Influx Line Protocol (ILP) to push data to QuestDB. As such, it is important to provide the raw ILP string in the write callback function.
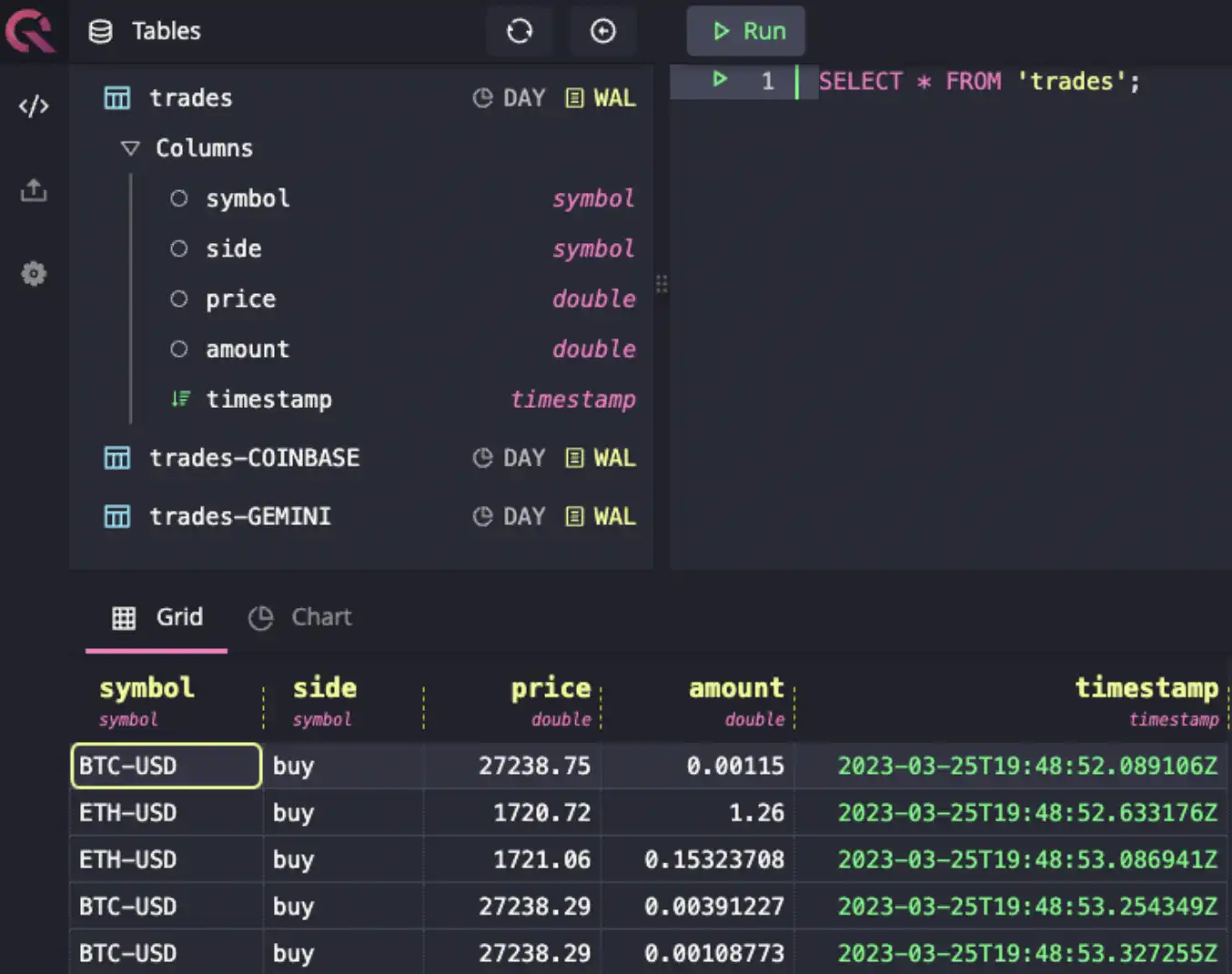
The biggest advantage of using Cryptofeed is the large number of preconfigured integrations with various exchanges. The library does the heavy lifting of normalizing the data so ingesting it into QuestDB is very simple. However, if you need more control over the type or format of the data, you may need to call the exchange API directly.
Method 2: Build a custom market data pipeline
If Cryptofeed does not support the exchange you are interested in or if you need more control over the type or format of the data, you can opt to write your own data ingestion function. With QuestDB, you have the option to use PostgreSQL wire or ILP. Since the ILP is faster and supports schemaless ingestion, we will show an example of using the InfluxDB Line Protocol via QuestDB Python SDK to ingest price data from Binance and Gemini:
import requests
import time
from questdb.ingress import Sender, TimestampNanos
conf = f'http::addr=localhost:9000;'
def get_binance_data():
url = 'https://api.binance.us/api/v3/ticker/price'
params = {'symbol': 'BTCUSDT'}
response = requests.get(url, params=params)
data = response.json()
btc_price = data['price']
print(f"BTC Price on Binance: {btc_price}")
publish_to_questdb('Binance', btc_price)
def get_gemini_data():
url = 'https://api.gemini.com/v1/pubticker/btcusdt'
response = requests.get(url)
data = response.json()
btc_price = data['last']
print(f"BTC Price on Gemini: {btc_price}")
publish_to_questdb('Gemini', btc_price)
def publish_to_questdb(exchange, price):
print("Publishing BTC price to QuestDB...")
with Sender.from_conf(conf) as sender:
sender.row(
'prices',
symbols={'pair': 'BTCUSDT'},
columns={'exchange': exchange, 'bid': price},
at=TimestampNanos.now())
sender.flush()
def job():
print("Fetching BTC price...")
get_binance_data()
get_gemini_data()
while True:
job()
time.sleep(5)
The code above polls the REST endpoints of Binance and Gemini API and writes the
data to a table called prices:
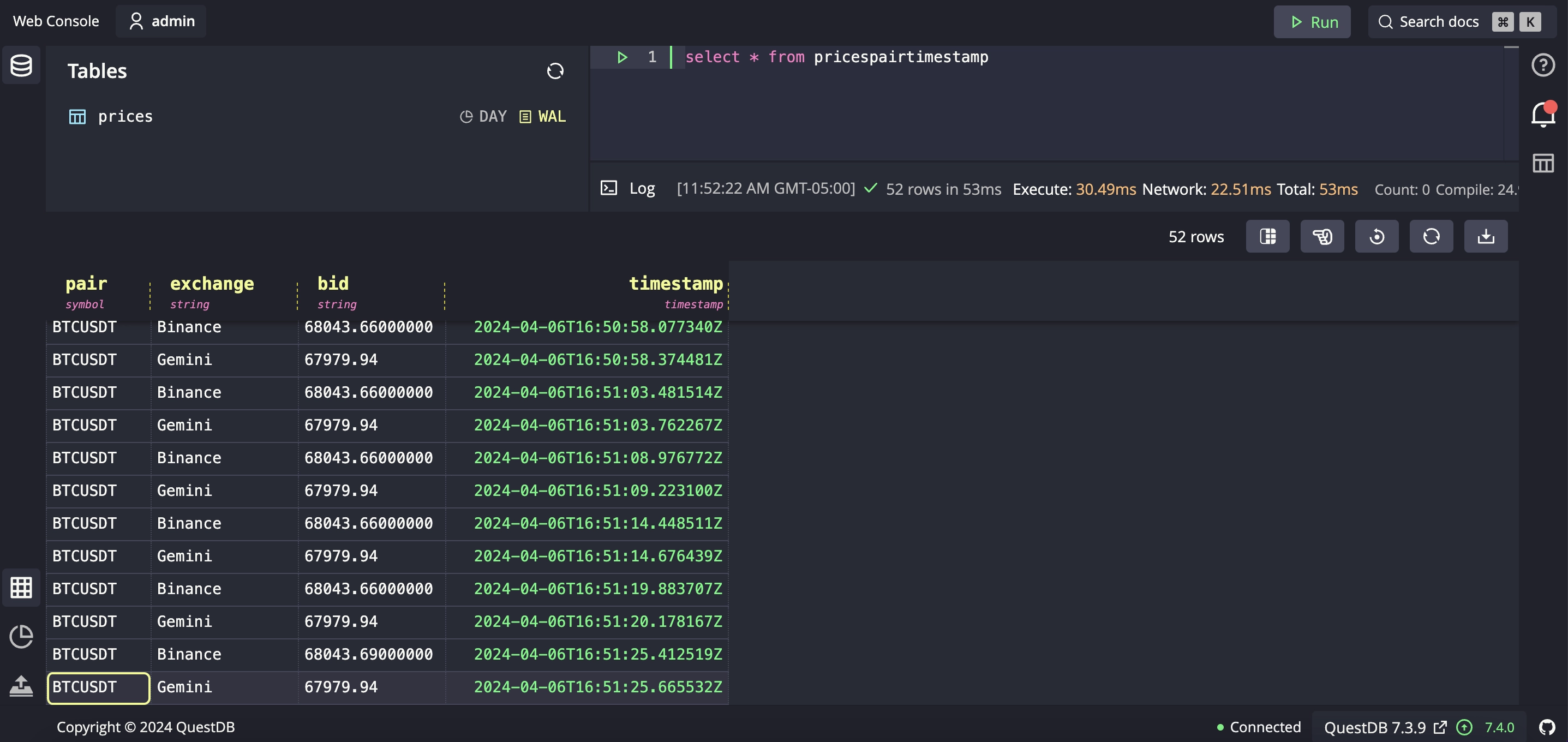
While writing a custom data ingestion function is more work than simply using Cryptofeed, it can be a great option if you need to customize the fields or run some preprocessing logic prior to sending it to QuestDB.
Method 3: Ingest market data using Change Data Capture (CDC)
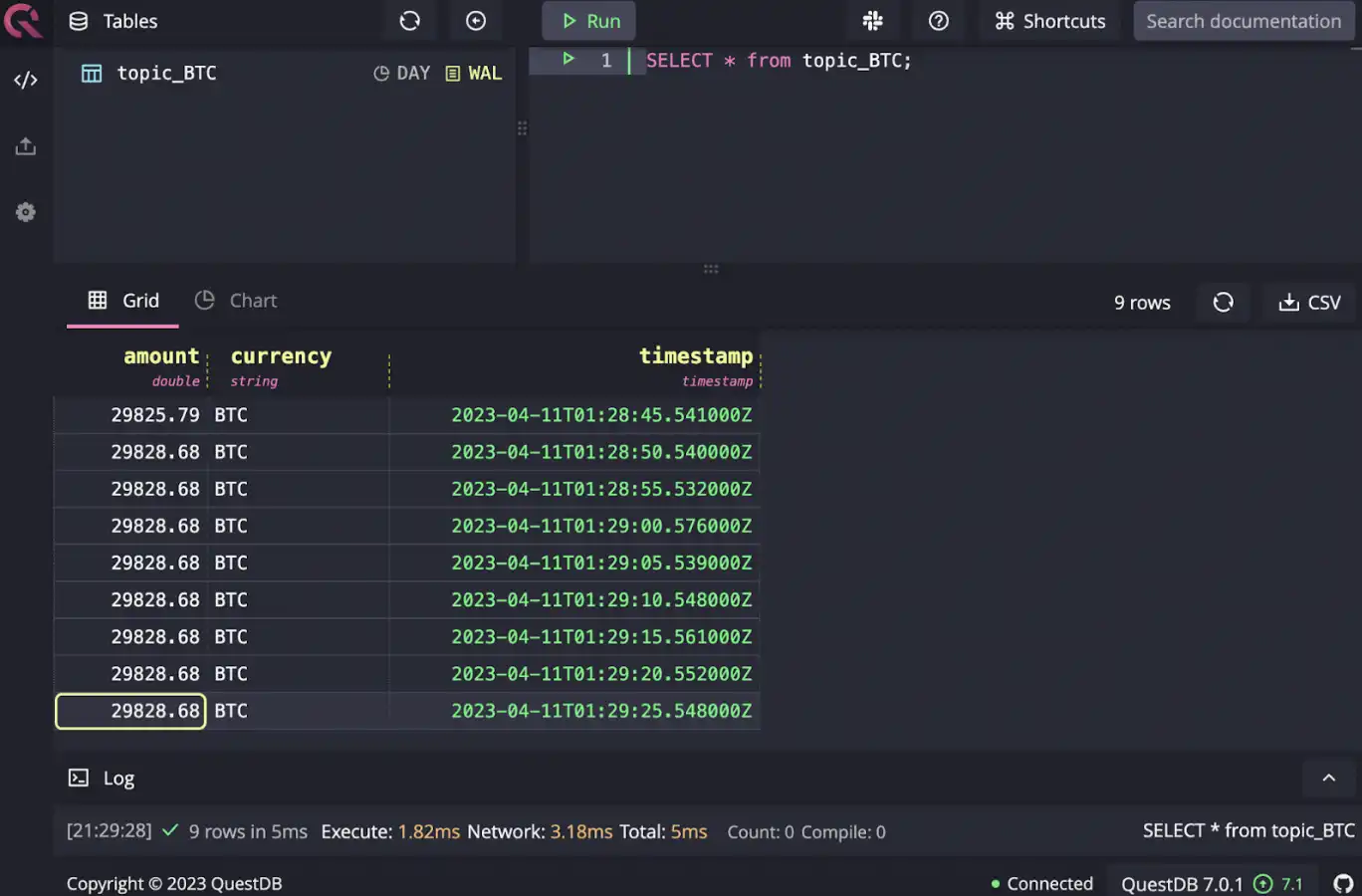
Finally, you can ingest data via Change Data Capture (CDC) if you have an external data stream or database that you can listen on. For example, an external data market team might publish price data on Kafka or push updates to a relational database. Instead of polling this data directly, you could opt to leverage CDC patterns to stream changes to QuestDB instead.
An example of this architecture is detailed in Realtime crypto tracker with QuestDB Kafka Connector. This reference architecture has a function that polls Coinbase API for latest price data and publishes it to Kafka topics. QuestDB Kafka Connector in turn publishes that data to QuestDB.
Wrapping up
Wrapping up QuestDB offers various ways to ingest crypto market data quickly. For a starting point, utilize the Cryptofeed library to connect to various exchanges that are already supported, and optionally modify the ingestion by implementing your own callback. If you need to integrate with a data feed not supported by Cryptofeed, you can write a custom data ingestor and publish data over InfluxDB line protocol to QuestDB. Finally, if there’s an existing data feed that Debezium supports (e.g., Kafka, PostgreSQL) then using CDC can be a great choice to minimize the infrastructure burden.
Additional resources
FAQs
-
What is level 1, Level 2, Level 3 market data?
Level 1 market data provides basic market data including current bid and ask prices, last traded price, and the size on each buy/sell side. Level 2 market data provides market depth data (e.g., 5-10 bid/ask prices). Level 3 adds additional information on market depth data typically up to 20 best bid/ask prices along with custom orders.
-
What is an order book?
An order book is a collection of buy and sell orders for a security or commodity being traded. It organizes current bids and asks by price, updating it constantly as orders are being executed.
-
What are Candlestick charts?
Candlestick charts are a popular form of financial chart uses to show the price movement. The candle comprises of opening, closing, high, and low prices for the financial instrument of note.
-
What is an exchange API?
Exchange API is the application programming interface that exposes data (e.g., market depth, latest price, etc) provided by exchanges.
-
What is Change Data Capture (CDC)?
Change Data Capture (CDC) is a design pattern used with databases to track changes to the underlying dataset. CDC enables near real-time data replication and integration.
-
What is Kafka?
Kafka is a distributed streaming platform that is used for data pipelines, streaming analytics, and data integration.