Apache Parquet, what it is and why to use it
Apache Parquet is a columnar storage file format designed for efficient data processing and storage. It was developed to handle large-scale data processing and analytics through better performance and more efficient data compression. It was initially created by engineers at Twitter and Cloudera, and was released in March 2013 as an open-source project under the Apache Software Foundation.
We'll unpack what it is and compare its features to other storage formats.
Why Parquet?
The motivation behind Parquet was to address the limitations of existing storage formats, particularly for "big data" processing. Twitter needed a more efficient and performant way to store and process large-scale datasets, especially for analytic queries.
According to the excellent article "The birth of Parquet" by Julien Le Dem, Parquet was born out of the "Red Elm" system. The goal was to find a happy medium between Twitter's Hadoop-based storage system, which scaled well but had high latency, and their "Massively Parallel Processing database" named Vertica, which had low latency but didn't scale well.
After some most excellent open-source collaboration, Parquet was born. And soon after came SparkSQL, which is a distributed SQL query engine built on top of Apache Spark.
What makes Parquet so compelling? Let's dive into the details.
Unpacking Apache Parquet
The strengths of Parquet speak towards the weaknesses of other storage formats.
We'll pick a few key areas:
- Row vs. columnar storage model
- Efficient compression
- Schema evolution
- Support for complex data types
Row vs. columnar storage
Traditional storage formats, such as CSV and JSON, apply row-oriented data storage. This approach is inefficient for analytic queries, which typically require operations on specific columns rather than entire rows. Row-based storage results in reading more data than necessary, leading to increased I/O and slower query performance.
As visualized in the aforementioned article by Julien Le Dem:
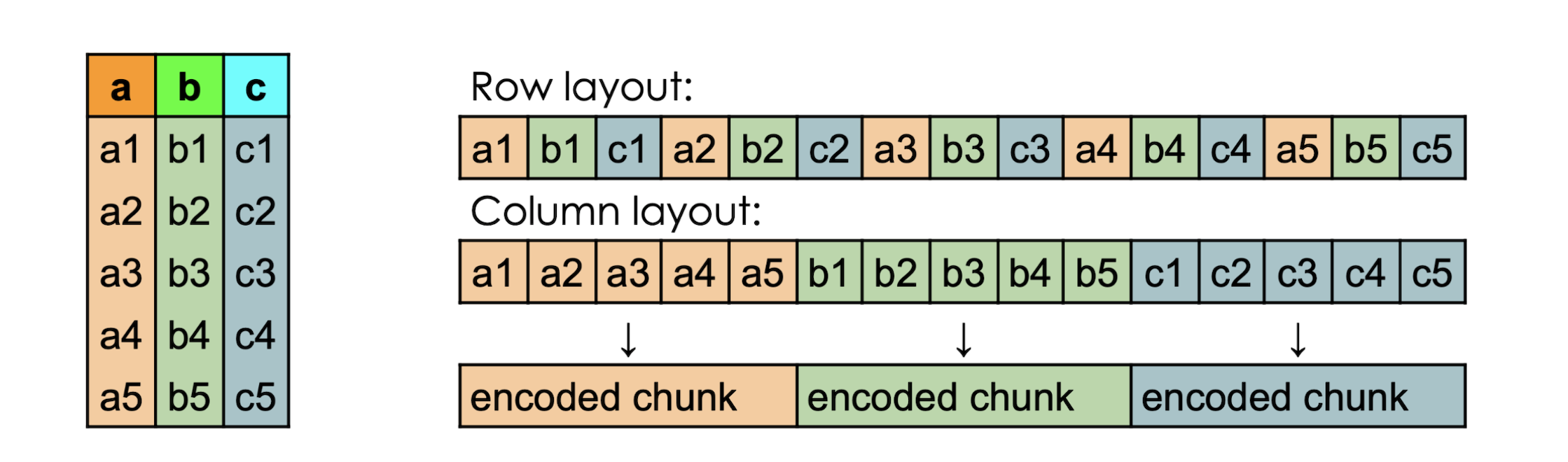
Let's look at a hypothetical query to illustrate the point.
Suppose we want to calculate the average salary of employees in the “Engineering” department.
Consider our employee data storage, in row format:
[[1, "Alice", 30, "Engineering", 100000],[2, "Bob", 35, "Marketing", 80000],[3, "Terry", 40, "Sales", 120000],[4, "Deaner", 45, "HR", 90000],[5, "Eve", 50, "Finance", 110000]]
Now, when we launch the query:
• The query needs to scan each row to check the “Department” column and then retrieve the “Salary” column for employees in “Engineering”.
• Even if only the “Department” and “Salary” columns are needed, every single row is accessed and read. This causes unnecessary I/O operations retrieving data from irrelevant columns. For example, “Name”, “Age” are also read.
Now, let's "columnarize" the data:
{"Employee ID": [1, 2, 3, 4, 5],"Name": ["Alice", "Bob", "Terry", "Deaner", "Eve"],"Age": [30, 35, 40, 45, 50],"Department": ["Engineering", "Marketing", "Sales", "HR", "Finance"],"Salary": [100000, 80000, 120000, 90000, 110000]}
Only the “Department” and “Salary” columns are accessed and read into memory, skipping irrelevant columns.
{"Employee ID": [1, 2, 3, 4, 5],"Name": ["Alice", "Bob", "Terry", "Deaner", "Eve"],"Age": [30, 35, 40, 45, 50],"Department": ["Engineering", "Marketing", "Sales", "HR", "Finance"],"Salary": [100000, 80000, 120000, 90000, 110000]}
Since only the required columns are read, I/O operations are significantly reduced, leading to faster query performance and lower resource usage.
Flexible compression
Row-based formats do not compress as efficiently as columnar formats because they store heterogeneous data types together. Columnar formats, on the other hand, store homogeneous data types together, allowing for more effective compression algorithms that reduce storage costs and improve read performance.
Though there isn't just one "compression" algo under-the-hood. There are many which can be applied, depending on the use case, data type and the data itself.
| Codec | Description | Authoritative Source | Use Case |
|---|---|---|---|
| UNCOMPRESSED | No compression is applied. Data is stored as-is. | N/A | Suitable for scenarios where data retrieval speed is more critical than storage space. Even the best compression adds some overhead. |
| SNAPPY | Based on the Snappy compression format developed by Google. It aims to provide fast compression and decompression speeds with reasonable compression ratios. | Google Snappy library | Ideal for applications where fast processing speed is crucial, and the compression ratio is of secondary importance. |
| GZIP | Based on the GZIP format defined by RFC 1952. It offers higher compression ratios at the cost of slower compression and decompression speeds. | zlib compression library | Suitable for scenarios where storage efficiency is more important than compression/decompression speed. |
| LZO | Based on or compatible with the LZO compression library, known for very fast compression and decompression. | N/A | Useful in scenarios where the speed of data processing is critical and some compression is needed, but perhaps not as widely used or supported as other codecs. |
| BROTLI | Based on the Brotli format defined by RFC 7932. It provides a good balance between compression ratio and speed, often achieving better compression ratios than GZIP with similar or faster speeds. | Brotli compression library | Ideal for web applications and other scenarios where both efficient compression and reasonable speed are needed. |
| ZSTD | Based on the Zstandard format defined by RFC 8478. It offers high compression ratios and fast speeds, making it highly efficient. | Zstandard compression library | Highly suitable for scenarios demanding both high compression efficiency and speed, such as large-scale data storage and analytics. |
| LZ4_RAW | Based on the LZ4 block format without additional framing. It provides very fast compression and decompression speeds. | LZ4 compression library | Best for applications where compression/decompression speed is a priority, replacing the deprecated LZ4 codec. |
That's a lot of choices!
Surely, if you need to compress data, Parquet supports an appropriate option.
Schema evolution
Schema evolution is very tricky. Within many data storage contexts, it is often difficult to add or modify columns in a dataset without rewriting the entire file.
We'll unpack CSV, JSON and row-based relational databases.
CSV, schema evolution
For CSV, a basic customer table:
customer_id,customer_name,customer_age
1,John Doe,28
2,Jane Smith,34
3,Bob Johnson,45
Consider that we need to add a new column for an email.
The steps are:
- Read the entire CSV file.
- Modify the header to include the new column.
- Add the email data for each row.
- Write the updated data to a new CSV file.
This is expensive, error-prone and slow!
JSON, schema evolution
JSON paints a similar picture.
[{ "product_id": 1, "product_name": "Laptop", "price": 999.99 },{ "product_id": 2, "product_name": "Smartphone", "price": 499.99 },{ "product_id": 3, "product_name": "Tablet", "price": 299.99 }]
We want to add a new field for product categories.
So we:
- Read the entire JSON file into memory.
- Modify each JSON object to include the new field.
- Write the updated JSON objects back to the file.
Again, this is an intensive operation.
Row-based relational, schema evolution
In a typical relational, row-based database, we create a table:
CREATE TABLE employees (employee_id INT,employee_name VARCHAR(100),department VARCHAR(50));
Now, we want a new column for employee_salary:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);- Update application logic.
This looks simple. It's the same for columnar databases!
But the devil is in the details.
Altering large tables to add or modify columns often requires the database to lock the entire table during the schema change. This prevents read/write on the table during the alteration. Depending on the size of the table and the complexity of the schema change, this locking can lead to significant downtime.
Frequent schema changes can also degrade database performance. Each schema change might trigger index rebuilding, data reorganization, and other resource-intensive operations that strain the database's performance.
Parquet, schema evolution
With Parquet, add and modify columns without a re-write of the dataset. New columns are appended, and existing data remains compatible with older schema versions.
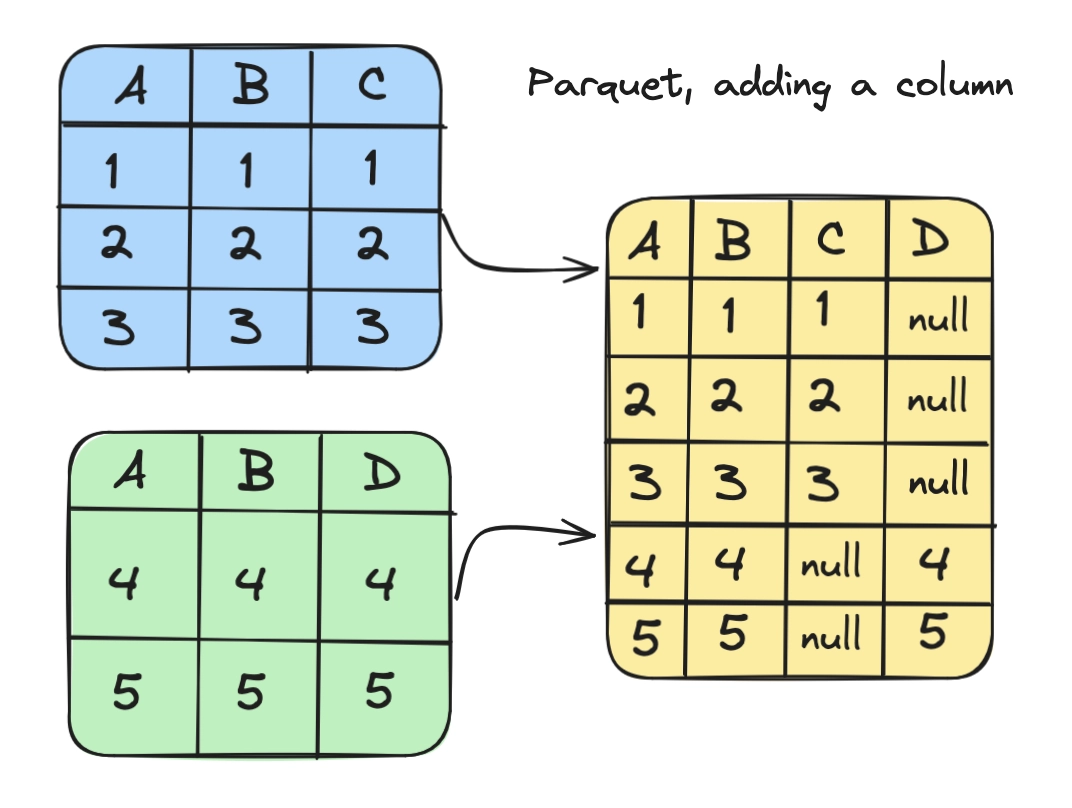
While cleaner than the alternative, schema evolution remains a very expensive operation. And how it works will depend on how it is implemented. For example, Apache Spark only allows additions:
Like Protocol Buffer, Avro, and Thrift, Parquet also supports schema evolution. Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. The Parquet data source is now able to automatically detect this case and merge schemas of all these files.
Support for complex data types
Many traditional formats did not natively support complex data types and nested structures, which are commonly used in modern data applications. This limitation made it challenging to store and process structured and semi-structured data efficiently.
Parquet natively supports complex data types such as arrays, maps, and nested structures. This makes it suitable for storing hierarchical data without flattening or redundant data representation. The Apache Arrow team has a clear blog on the topic, for further diving into complex data types.
Should I use Parquet?
Whether or not you use Parquet may be more of a decision for the tools which you apply. If you're managing large-volumes of data at scale, then using a tool with Parquet under-the-hood is a strong choice.
In short, it's a columnar storage format that is optimized for efficient data storage and processing. It is widely used in big data processing frameworks like Apache Spark, Apache Hive, and Apache Impala, as well as cloud-based data processing services like Amazon Athena, Google BigQuery, and Azure Data Lake Analytics.
Although, that said, you may be working with Parquet directly if you're applying pandas in Python.
Parquet and pandas (Python)
Pandas is a popular Python library for data manipulation and analysis. As we've reviewed, traditional file formats like CSV or JSON can be suboptimal due to their limitations, such as applying row-based storage and lacking appropriate compression. Pandas can apply Parquet as the file format, supporting both reading and writing from the pandas DataFrame context.
A Pandas DataFrame is a two-dimensional, size-mutable, and potentially heterogeneous tabular data structure in the Python programming language, which is part of the Pandas library. It is similar to a database table or an Excel spreadsheet, with rows and columns.
Advantages of using Parquet with Pandas
Reading data from Parquet files into pandas DataFrames can be significantly faster compared to row-based formats, especially with large datasets. Due to Parquet's compression and encoding techniques result in reduced memory usage, enhancing data processing efficiency.
Parquet’s schema evolution feature aligns well with pandas’ flexibility, allowing easy handling of data with varying column structures or adding new columns to existing DataFrames without much overhead.
import pandas as pd# Query the Parquet and measure the time%%timeresult = pd.read_parquet(parquet_file_path).query("id == 123456")print(result)
For more information on Pandas and Parquet, there's a helpful Medium blog from munchy-byte.
Parquet and QuestDB
Parquet files can be read and thus queried by QuestDB.
To do so, first set a directory where the Parquet file lives.
This can be done one of two ways:
- Set the environment variable
QDB_CAIRO_SQL_COPY_ROOT - Set the
cairo.sql.copy.rootkey inserver.conf
After that, apply the function like so:
parquet_read(parquet_file_path)
For more information, see the Parquet documentation.