Introduction
QuestDB is an Apache 2.0 open source columnar database that specializes in time series.
It offers category-leading ingestion throughput and fast SQL queries with operational simplicity.
Given its effiency, QuestDB reduces operational costs, all while overcoming ingestion bottlenecks.
As a result, QuestDB offers greatly simplified overall ingress infrastructure.
This introduction provides a brief overview on:
Just want to build? Jump to the quick start guide.
Top QuestDB features
QuestDB is applied within cutting edge use cases around the world.
Developers are most enthusiastic about the following key features:
Massive ingestion handling & throughput
If you are running into throughput bottlenecks using an existing storage engine or time series database, QuestDB can help.
High performance deduplication & out-of-order indexing
High data cardinality will not lead to performance degradation.
Hardware efficiency
Strong, cost-saving performance on very mninimal hardware, including sensors and Raspberry Pi.
SQL with time series extensions
Fast, SIMD-optimized SQL extensions to cruise through querying and analysis.
No obscure domain-specific languages required.
Greatest hits include:
SAMPLE BYsummarizes data into chunks based on a specified time interval, from a year to a microsecondWHERE INto compress time ranges into concise intervalsLATEST ONfor latest values within multiple series within a tableASOF JOINto associate timestamps between a series based on proximity; no extra indices required
Benefits of QuestDB
To avoid ingestion bottlenecks, high performance data ingestion is essential.
But performance is only part of the story.
Efficiency measures how well a database performs relative to its available resources.
QuestDB, on maximal hardware, significantly outperforms peers:
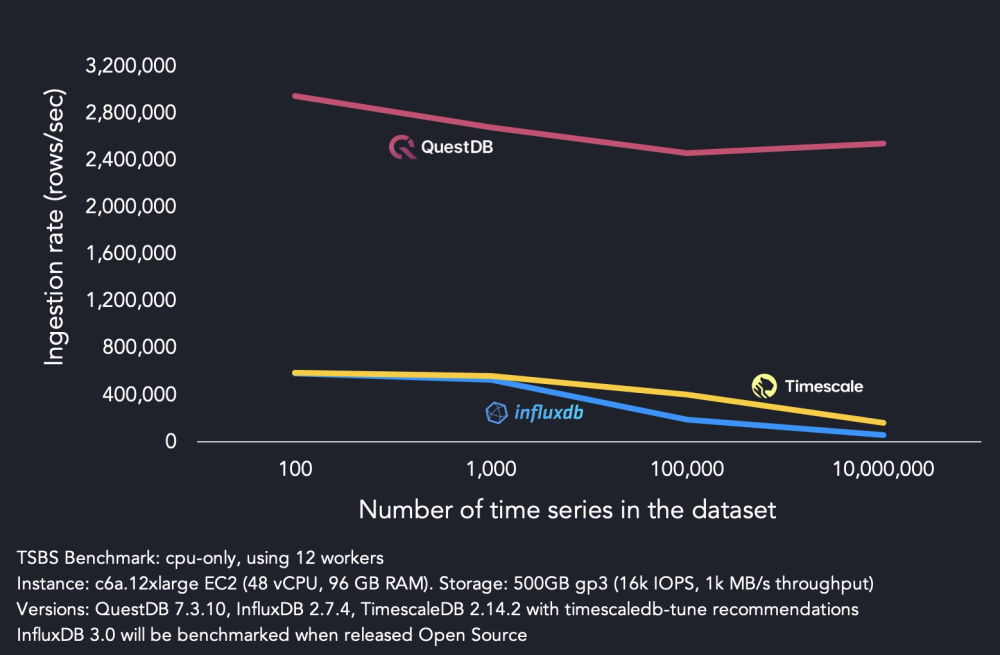
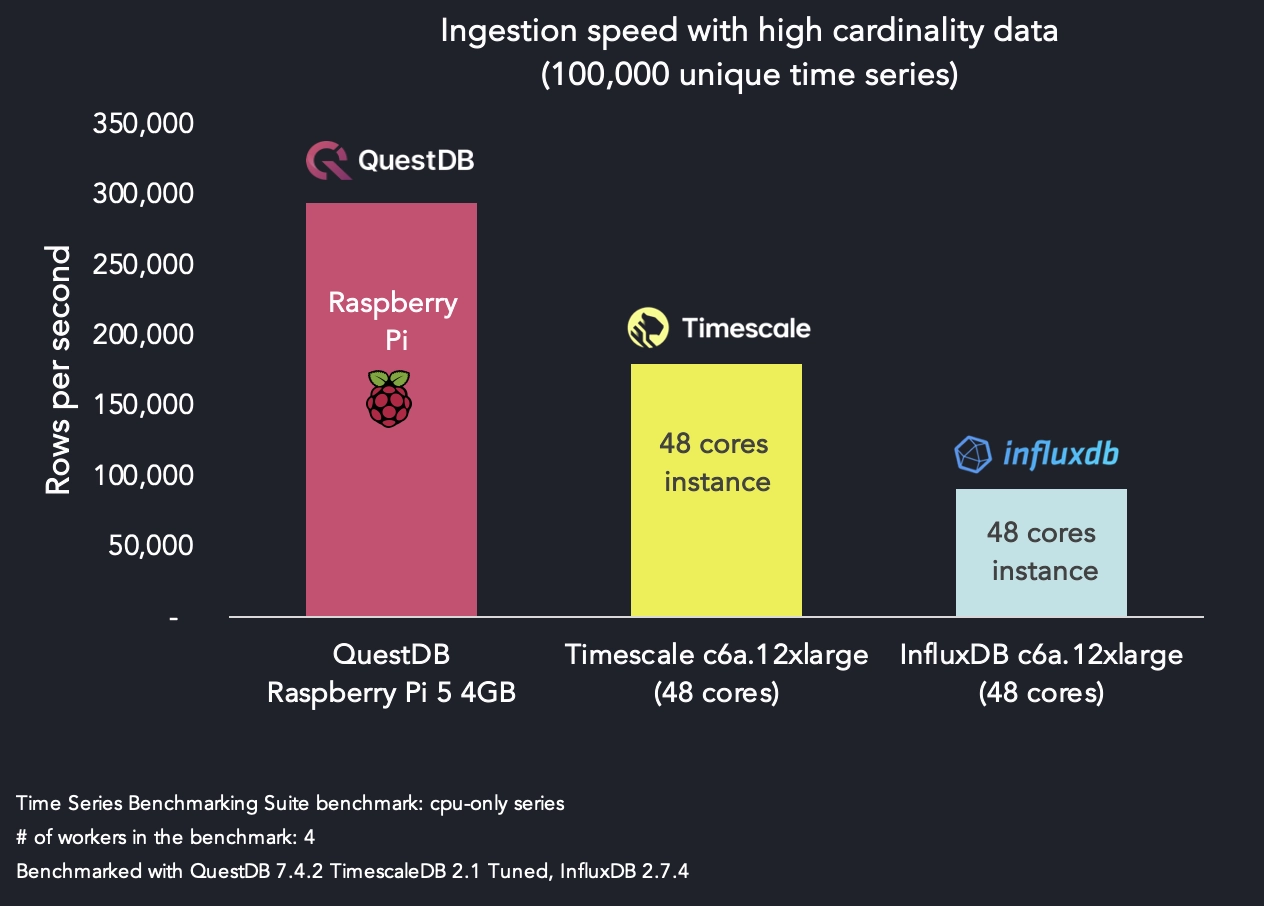
However, on less robust hardware the difference is even more pronounced, as seen in the following benchmark.
Even on hardware as light as a Raspberry Pi 5, QuestDB outperforms competitors on stronger hardware:
Beyond performance and efficiency, with a specialized time-series database, you don't need to worry about:
- out-of-order data
- duplicates
- exactly one semantics
- frequency of ingestion
- many other details you will find in demanding real-world scenarios
QuestDB provides simplified, hyper-fast data ingestion with tremendous efficiency and therefore value.
Write blazing-fast queries and create real-time Grafana via familiar SQL:
SELECT
timestamp, symbol,
first(price) AS open,
last(price) AS close,
min(price),
max(price),
sum(amount) AS volume
FROM trades
WHERE timestamp > dateadd('d', -1, now())
SAMPLE BY 15m;
Intrigued? The best way to see whether QuestDB is right for you is to try it out.
Click Demo this query in the snippet above to visit our demo instance and experiment.
To bring your own data and learn more, keep reading!
QuestDB Enterprise
QuestDB Enterprise offers everything from open source, plus additional features for running QuestDB at greater scale or significance.
For a breakdown of Enterprise features, see the QuestDB Enterprise page.
Where to next?
You'll be inserting data and generating valuable queries in little time.
First, the quick start guide will get you running.
Choose from one of our premium ingest-only language clients:
From there, you can learn more about what's to offer.
- Ingestion overview want to see all available ingestion options? Checkout the overview.
- Query & SQL Overview learn how to query QuestDB
- Web Console for quick SQL queries, charting and CSV upload/export functionality
- Grafana guide to visualize your data as beautiful and functional charts.
- Capacity planning to optimize your QuestDB deployment for production workloads.
Support
We are happy to help with any question you may have.
The team loves a good performance optimization challenge!
Feel free to reach out using the following channels: