What Is a Columnar Database?
Columnar databases are a type of database management system (DBMS) that stores and manages data in columns. This is in contrast to traditional relational databases that store and retrieve data by rows. The difference in the design is driven by data access patterns for transactional vs. analytical workloads.
Historically, relational databases have been used for transactional systems where you insert a whole row of data in a table. These tables typically have a fewer number of columns, and most of the columns in a row are not empty. When reading the data, one or more rows are commonly retrieved with all–or a majority–of the columns. This pattern works well for transactional systems with a dense dataset but does not scale well for analytical workloads.
In analytics, it is common to have very wide tables with many columns that are sparsely populated. When working with analytical workloads, we are also less interested in individual rows, but on the aggregates of data over large slices of the dataset.
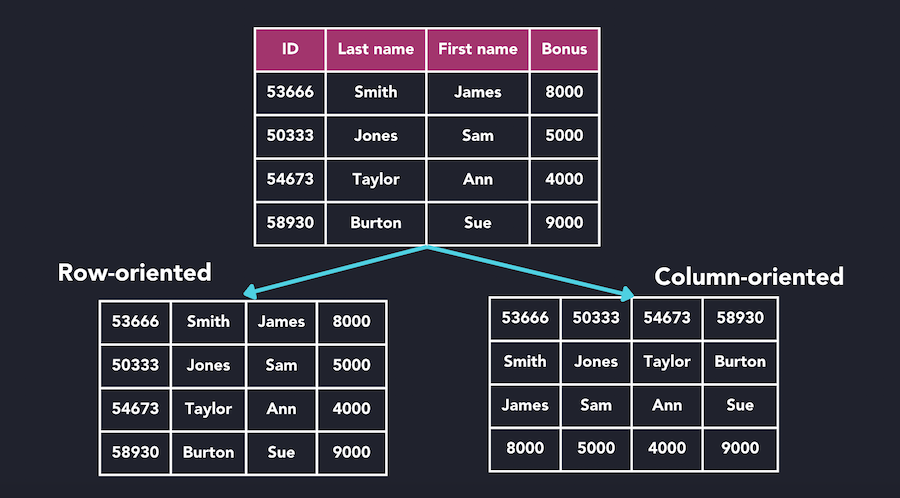
For example, we might have a large, denormalized table storing information for a global, e-commerce website. This table may store information about the orders, SKUs, warehouses, and ad-campaign records for the company in different columns. A typical analytical query might be: “Calculate the average and total price for an order in the last month grouped by a specific ad-campaign.” In this scenario, we need to access many rows in the table, but only a few relevant columns. If we were using a relational database to access entire rows, we would need to scan a lot of information from columns that are eventually thrown out. At scale, this would incur a big I/O overhead, resulting in poor performance. On the other hand, columnar databases can only scan for data in relevant columns and avoid expensive I/O times from disk.
Benefits of columnar databases
Some key advantages of columnar databases include:
- Compression: Because data stored in columns tends to exhibit more degrees of similarity over row-oriented datasets, columns can be compressed more efficiently, leading to reduced storage requirements.
- Reduced disk I/O: If a query deals with a specific subset of columns, columnar databases can avoid unnecessary reads from columns on disk. This results in reduced disk I/O, leading to increased performance and reduced cost. This also applies to writes where columnar databases can ignore empty columns in sparse datasets and only access relevant columns in storage.
- Performance: Another benefit of compressed data is that aggregation functions such as calculating the min, max, sum, count, or average perform significantly better. Also, columnar databases are efficient with join operations.
These qualities of columnar databases make them ideal solutions for analytical workloads involving data warehousing or big data processing.
Limitations of columnar databases
While columnar databases are great for online analytical processing (OLAP) workloads, they are not suitable for online transaction processing (OLTP) applications. Columnar databases are not as efficient with transactional workloads with frequent insert, update, or delete operations. If concurrent processing or isolation guarantees are required, it is better to consider row-oriented databases that can handle those requests.
Popular columnar databases
There are many open-source and commercial columnar databases widely used in the industry. These often integrate well into the big data ecosystem (e.g., Apache HBase with Hadoop).