Re-examining our approach to memory mapping
How does QuestDB get the kind of performance it does, and how are we continuing to squeeze another 50-60% out of it? This post will look at a code change we thought would create a negative performance impact, which actually brought a substantial boost in the system's overall performance and demonstrates that we are constantly learning more about performance improvements.
If you like this content, show it with a star on GitHub or come say hi in our community forums.
How to improve time series performance
QuestDB started out with a single-threaded approach to queries and such. But one obvious way to improve performance in a Java application like this is to parallelize as much as you can by using multiple threads of execution.
I've written multi-threaded applications, and they are not easy to do. It's hard to coordinate the work between multiple threads, and to make sure that there are no race conditions, collisions, etc.
How to store time series data more efficiently
So first it's important to understand that QuestDB stores it's data in columnar format. We store each column of data in a file. So for every column of data, there is a file.
We then split those columns up into data frames that are independent and can be computed completely independently of each other.
The problem we encountered with this framing scheme was that it was impossible to frame variable length data. Data spilled out of the frame, making it difficult to manage.
You see, we store fixed length fields with fixed length values, such that aligning frames to 8 bytes would ensure that all our fixed length data does not straddle frames. Hence all the columns are the same frame width. But strings and blobs can't be forced into 8 bytes without making them useless.
So we could extract extreme performance out of all the fixed-length values, but these variable-length values dragged the performance back down.
Which brings us to pages and how data is referenced in memory.
Can memory-mapped pages be more efficient?
QuestDB uses memory-mapped pages to reference data in order to make it really fast. If you're dividing up your data into pages, and all data has a fixed length, then it's relatively easy to ensure that you don't have data that spans multiple pages. You just break pages at multiples of 8-bytes and everything will fit within page boundaries.
When you add variable-length data, suddenly you cannot ensure that everything will line up along page boundaries and you will have the very real possibility -- actually a certainty -- that you may have to jump from one page to another just to get all the data contained in a frame.
This, it turns out, is hugely inefficient. If (data is in frame) then (process that data) else (figure out where the rest of the data is, get that, then process it all). This kind of if-then-else sprinkled throughout the code is a) hard to debug and b) leads to lots of branching, which slows down execution.
In order to prevent variable length data from straddling frames we would need to have different frame lengths per column. Furthermore, calculating aligned frame lengths for variable length data is non trivial and requires scanning the entire data set which would reversing any performance gains from parallelization.
One page to rule them all
(Yes, I just made a The Highlander reference)
What if, in order to get around data being on multiple pages, we simply used one page for all of the data? Of course my first question was "Don't you at some point reach a limit on the page size?" but Vlad and Patrick assured me there is, indeed, no limit on a page size.
If your page size is bigger than the available memory, the kernel will handle swapping pages in and out for you as you try to access different parts of the page. So of course I asked "well then, why didn't you do this from the beginning?"
Vlad, in his typically self-deprecating style, just said "We didn't know. We thought we should keep them to a certain size to keep them from growing out of control" which, quite frankly, seems like the right answer.
We'd just resize those smaller pages as needed. But as Vlad explained, if you do that then you need to copy the data over to the new, resized page and "copying can take over your life." Databases aren't built to maximize the efficiency of data copying. They are built to maximize the ability to extract value from data. Copying data from one page to another isn't extracting value.
So they tried just allocating a new page, and jumping from one page to the next as needed to find the required data. This cut down on the copying of data, but it lead to the problems outlined in the previous section. You never knew which page your data was going to be on, and jumping from one page to another was hugely inefficient.
So they tried having just the one page. One massive page (that you can grow as needed, without copying data around). Vlad, again in his style, said the performance turned out to be "not bad" with this approach. And by "not bad" he of course meant about a 60% performance improvement.
When you get into using one single page, of course the total available address space comes into play. But since QuestDB only runs on 64-bit architectures, we have 2^64 address space, which is more than enough.
This is where Patrick jumped in to explain that when you have an area of memory mapped from a file, when the file grows you remap the new size into memory. The operating system does not need to copy anything; the virtual memory model allows the OS to just remap the already mapped pages into the newly mapped memory region. In many cases, the OS may have already reserved the entire address space for you so your new mapping is in the same region as the old, just bigger.
How kernels handle pages efficiently
The kernel allocates a full sized address space for your file when you requested the memory-mapped file. And apparently this is true across Linux, macOS and Windows. So from that point on, there's really no further copying that needs to happen.
Furthermore, the kernel is going to handle paging parts of that file in and out of memory as needed. Now, I'm old-school Unix, and page-swapping which lead to thrashing was always something we worried about back in the olden days. So I asked about it. According to Patrick, this could only happen really if you have a massive file that you are reading basically randomly at high speed. Other than that, the kernel will handle reading ahead and pre-loading pages as needed in order to be as efficient as possible.
Kernels, it turns out, are smart. In fact, kernels are basically smarter than you or I will ever hope to be. They've been developed across decades to be hugely efficient at doing these things. It's what they do. The kernel will memory map the file into the file cache and even if it needs to move stuff around, it can move the logical address and it's still the same underlying physical memory pages.
If you think that you can take over caching the data from the OS and do a better job of managing the memory space, and the allocation and re-allocation of the memory, you're wrong. Again, this is what the Kernel does, and at some level, even if you try to take this job away from the kernel, it is still doing some amount of it anyway. So your attempts to take this memory management and allocation away from the kernel has done little more than just add another layer on top of what the kernel is doing anyway. Another layer on top of something is basically never more efficient than the original thing.
When you read an offset into a file, you send a buffer to read into, the address to start reading at, and the offset into the file. Now, the kernel is going to cache all of that for you as you do it, because that's the kernel's job, really. But many database developers then take that, and cache it themselves, with their own caching scheme.
How fast can you go with database speed?
When I asked Vlad about this, and how it relates to query speed, he was quite explicit in saying that thinking you (a database developer) can beat the kernel is pure folly. Postgres tries this and, according to Vlad, an aggregation over a large (really large!) dataset can take 5 minutes, whereas the same aggregation on QuestDB takes only 60ms. Those aren't typos.
To both Patrick and Vlad (and me, for what that's worth), the idea that we, as developers, can be better at these operations than the kernel (when really we're doing them on top of the kernel anyway) is simply ridiculous. If I take an army of researchers and spend a decade of development, then maybe I can do it better than the kernel, but during that time guess what? The army of people working on the kernel will have found further improvements and left me behind anyway.
It comes down to letting the kernel do its job, and us doing ours. And our job is to exploit the kernel for every ounce of performance we can get out of it without trying to do it's job for it.
Performance benchmark results
When it comes to performance claims, we always try to back them up with actual numbers that can be replicated. You can run these tests yourself, and you can always go and look at the source code for these tests to see how they are implemented.
We think these numbers speak for themselves.
These first results are for the primitives and represent 10,000 reads/writes:
32-bit Read
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| VirtualMemoryReadBenchmark.testIntContiguous | avgt | 5 | 4601.940 | ns/op |
| VirtualMemoryReadBenchmark.testIntLegacy | avgt | 5 | 7064.822 | ns/op |
32-Bit Write
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| VirtualMemoryBenchmark.testPutIntContiguous | avgt | 5 | 5270.264 | ns/op |
| VirtualMemoryBenchmark.testPutIntLegacy | avgt | 5 | 5692.148 | ns/op |
64-bit Read
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| VirtualMemoryLongReadBenchmark.testLongContiguous | avgt | 5 | 4088.338 | ns/op |
| VirtualMemoryLongReadBenchmark.testLongLegacy | avgt | 5 | 5022.875 | ns/op |
64-bit Write
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| VirtualMemoryLongWriteBenchmark.testPutLongContiguous | avgt | 5 | 4413.181 | ns/op |
| VirtualMemoryLongWriteBenchmark.testPutLongLegacy | avgt | 5 | 6976.593 | ns/op |
And here are the results for strings, which represent 100 reads/writes:
String Read
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| VirtualMemoryStrReadBenchmark.testGetStrContiguous | avgt | 5 | 300.346 | ns/op |
| VirtualMemoryStrReadBenchmark.testGetStrLegacy | avgt | 5 | 525.775 | ns/op |
| VirtualMemoryStrWriteBenchmark.testPutStrContiguous | avgt | 5 | 2.019 | ns/op |
| VirtualMemoryStrWriteBenchmark.testPutStrLegacy | avgt | 5 | 3.646 | ns/op |
For those of you that are more graphicly-inclined:
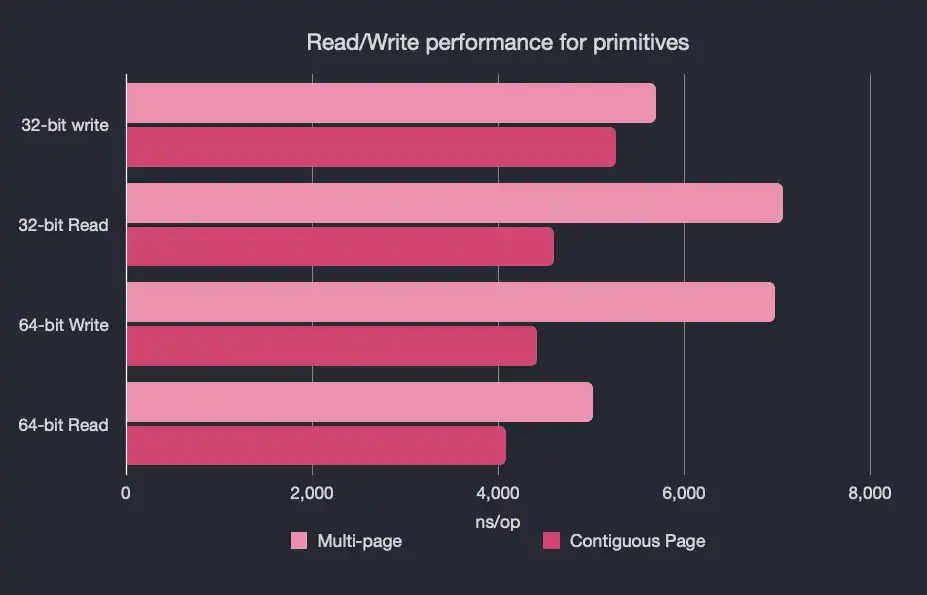
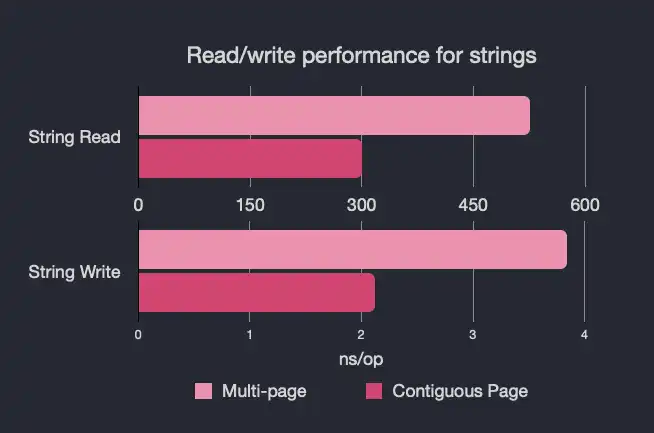
Again, we think these numbers speak for themselves, but we're always happy to hear from you, our users and community, about what you think.