QuestDB
Open main menu
Product
Enterprise
Market Data
Docs
Blog
8.1.4
Roadmap
Search
Download
Popular topics
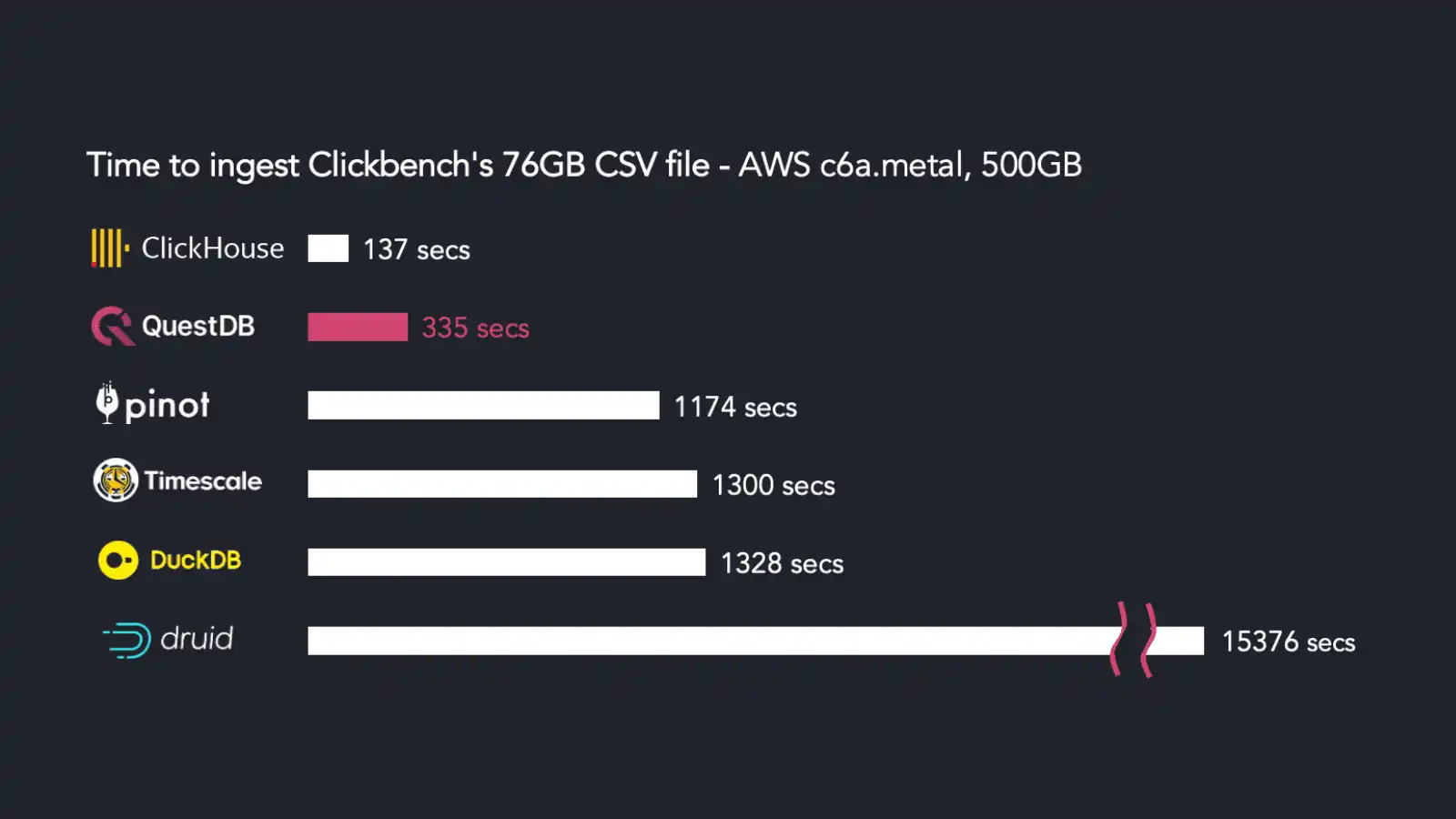
Benchmarks
Tutorials
Demos
User Stories
sql
grafana
market data
python
kafka
iot
telegraf
release
engineering
prometheus
k8s
pandas
All performance posts
PERFORMANCE
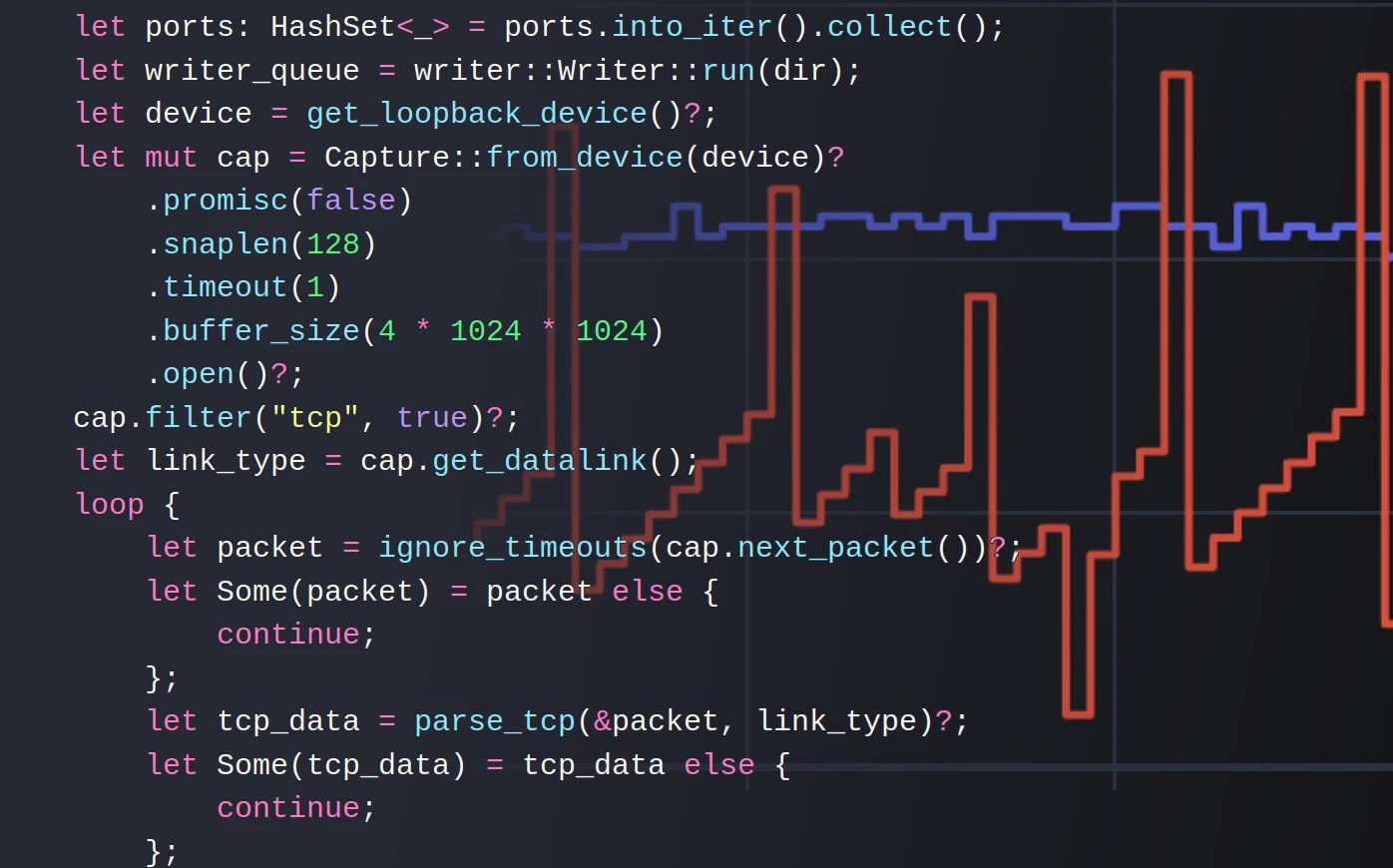
Debugging distributed database mysteries with Rust, packet capture and Polars
by
Adam Cimarosti
on July 29, 2024
PERFORMANCE
ASOF Join — The "Do What I Mean" of the Database World
by
Marko Topolnik
on June 24, 2024
PERFORMANCE
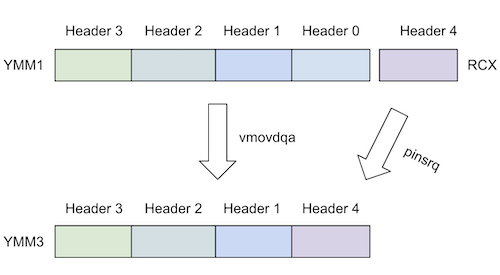
Does "vpmovzxbd" Scare You? Here's Why it Doesn't Have To
by
Marko Topolnik
on April 12, 2024
PERFORMANCE
1BRC merykitty’s Magic SWAR: 8 Lines of Code Explained in 3,000 Words
by
Marko Topolnik
on March 7, 2024
PERFORMANCE
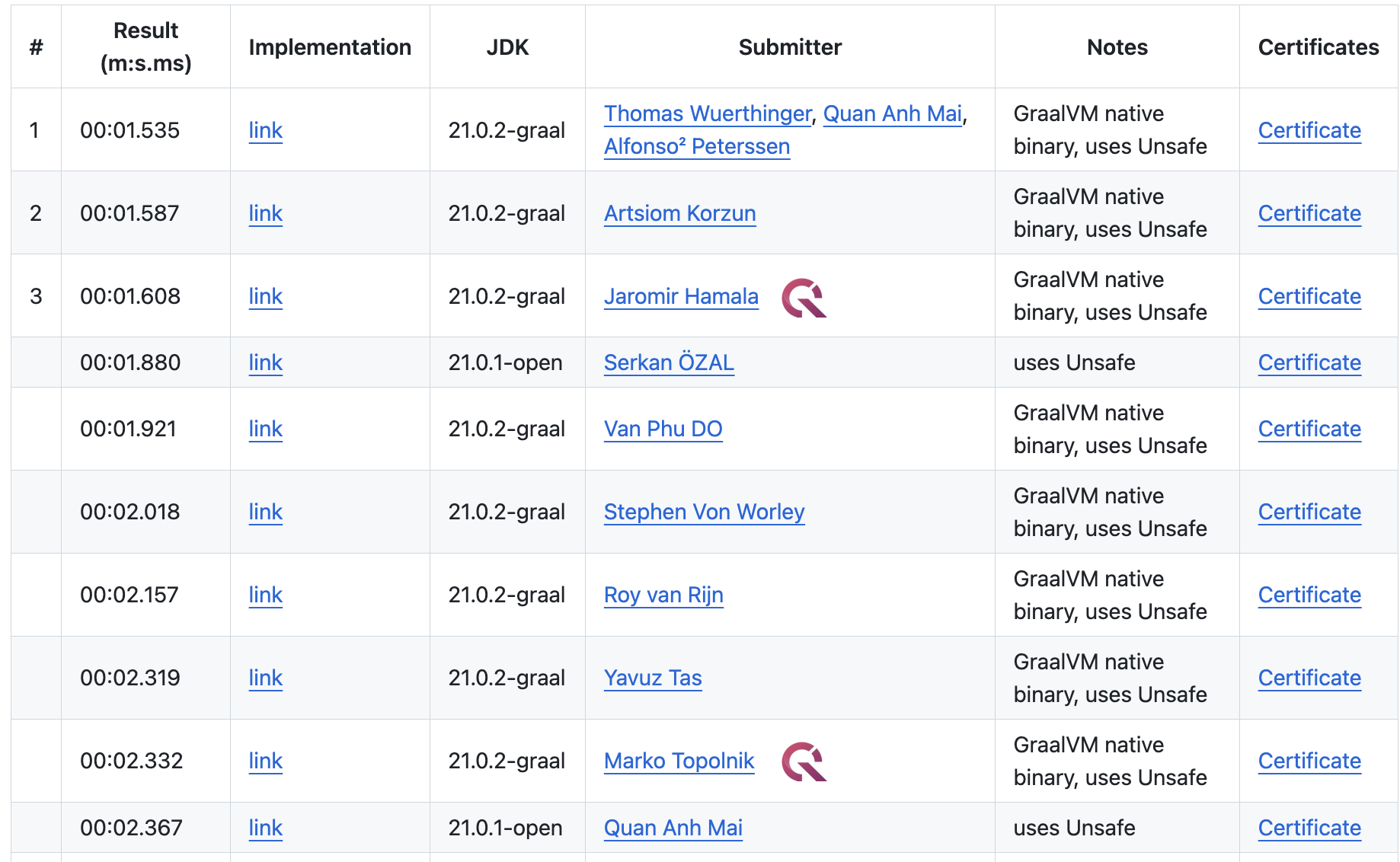
The Billion Row Challenge (1BRC) - Step-by-step from 71s to 1.7s
by
Marko Topolnik
on February 20, 2024
PERFORMANCE
Building a faster hash table for high performance SQL joins
by
Andrey Pechkurov
on November 23, 2023
PERFORMANCE
Leveraging Rust in our high-performance Java database
by
Adam Cimarosti
on August 29, 2023
PERFORMANCE
Optimizing the Optimizer: the Time-Series Benchmark Suite
by
Andrey Pechkurov
on May 18, 2023
PERFORMANCE
Listen to Your CPU - Full-table Scans Are Fast
by
Jaromir Hamala
on November 30, 2022
PERFORMANCE
Importing 300k rows/sec with io_uring
by
Andrey Pechkurov
on September 12, 2022
PERFORMANCE
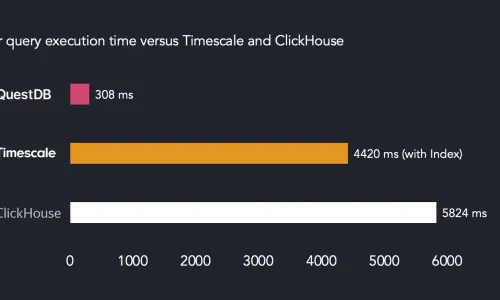
4Bn rows/sec query benchmark: Clickhouse vs QuestDB vs Timescale
by
Andrey Pechkurov
on May 26, 2022
PERFORMANCE
How we built a SIMD JIT compiler for SQL in QuestDB
by
Andrey Pechkurov
on January 12, 2022
PERFORMANCE
Why performance matters in time-series data
by
Nicolas Hourcard
on September 24, 2020
PERFORMANCE
Re-examining our approach to memory mapping
by
David G. Simmons
on August 19, 2020
PERFORMANCE
Things we learned about sums
by
Tancrede Collard
on May 12, 2020
PERFORMANCE
Aggregating billions of rows per second with SIMD
by
Tancrede Collard
on April 2, 2020

 Star us on GitHub
Star us on GitHub