In this article, I will summarize how and why we've started using Rust in our Java code base. Specifically, I'll cover:
- Our style of Zero-GC Java.
- Circumstances when we pick Rust over Java.
- Rust build integration with Maven.
- A few JNI basics.
- Integrated logging between Rust and Java.
- Developer Workflow.
- Upcoming QuestDB features in Rust.
Hopefully, this blog post will act as a starting point and guide for anyone wishing to embed Rust within their Java code base.
In this article, I assume both Java and Rust basics.
Currently, QuestDB's open-source code base comprises ~90% Java and ~10% C, C++, or Assembly.
The code has been written by wrapping system calls and networking primitives for
Windows, Linux, and MacOS into JNI bindings and then writing the database logic
in Java on top of that layer. Similarly, bulk memory allocation (as used by
network buffers and queries) is typically done off the Java heap by calling the
malloc and free functions via JNI.
Our code aims to avoid garbage collection, as much as possible, and is always free of garbage collection on any performance-critical paths (such as when ingesting data).

Our Java code is not idiomatic: We seldom use the new keyword and objects are
designed to be pooled and reused. Many of our types implement the Closable
interface to manage the lifetime of native code resources (memory, network
sockets, etc).
Over time, we ended up with our internally-developed standard library to handle things like networking, threading, collections, logging, and even text encodings.
When we compile, we bundle everything (Java .class files and native code
artifacts) into a single .jar which relies solely on the JVM as its
dependency.
These techniques are time-intensive, but the results are clear with a product that's easy to compile, deploy and run. The performance is evident from the first time launching the database, which is ready to serve requests within seconds.
Why Rust
However, there is a trade-off. As we evolve our product and integrate it with third-party technologies we face a challenge: Most Java projects do not design their code to minimize garbage collection and we can't use other JAR dependencies without violating our zero-GC performance standards.
We've considered extending our C++ code base, but this has significant tooling overhead and introduces problems of its own. Although these are problems that can be worked around, they are tedious, time-consuming, and full of pitfalls.
Let's take the case of using QuestDB as an embedded database. In this scenario, our compiled symbols share the process space with those of another application. It's thus important to mitigate potential symbol clashes. C++ compilers complicate this issue by dynamically linking to the standard library by default. More generally, resolving linkage and dependency issues in CMake is no walk in the park and to avoid these issues we've resorted to compiling our C++ code without exceptions, RTTI, or the standard library.
We started looking for a more productive alternative.
Rust appeals to us not as a technology to rewrite our database in, but as a technology to extend our database's capabilities. The crates.io repository holds a large collection of dependencies that, due to the language, are GC-free. Additionally, Rust also statically links all dependencies, reducing the risk of symbol collisions.
We started experimenting with Rust and realized that due to the wider surface area of the APIs we would be dealing with, it would mean breaking away from the practice of just writing thin JNI wrappers over native code to developing complete components outside of Java.
The first thing we'd need is good build tool integration and a streamlined developer workflow.
The rust-maven-plugin
Since we use Maven to build our code, we looked around for plugins that could
help but found none that would make it easy to build Rust and Java code
together. As such, we wrote the
rust-maven-plugin which can
invoke cargo commands. Build integration might have been easier were we using
Gradle, but we were not interested in switching our build system.
Without rehashing its whole documentation, we can now dedicate a source directory to a Rust crate, wire up a small amount of config and then let Maven build both our Java and Rust code with a single:
mvn compile
This is how our pom.xml setup integrates the build for our Rust JNI crate
called qdb:
<project ...>
<!-- ... -->
<properties>
<qdb.release>false</qdb-release>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.questdb</groupId>
<artifactId>rust-maven-plugin</artifactId>
<version>1.1.1</version>
<executions>
<execution>
<id>qdb-build</id>
<goals>
<goal>build</goal>
</goals>
<configuration>
<!-- Crate path relative to pom.xml root. -->
<path>rust/qdb</path>
<copyTo>${project.build.directory}/classes/com/questdb/bin</copyTo>
<copyWithPlatformDir>true</copyWithPlatformDir>
<release>${qdb.release}</release>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<profiles>
<profile>
<id>qdb-release</id>
<properties>
<qdb.release>true</qdb.release>
</properties>
</profile>
</profiles>
</project>
The <profile> section allows building release (as opposed to debug) binaries
when calling mvn with -Pqdb-release.
Our Cargo.toml configuration adds a dependency to the jni crate and compiles
the crate to a dynamic library.
[package]
name = "qdb"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
[dependencies]
jni = "0.21.0"
The <copyTo> config instructs the rust-maven-plugin to copy the compiled
Rust dynamic library to the target/classes directory. During the mvn package
phase, Maven bundles the contents of this path into the final .jar.
Then, at start-up, the auxiliary jar-jni Java library (shipped alongside the
rust-maven-plugin) extracts the compiled binary to a temporary location and
loads the Rust code's dynamic library into memory.
package com.questdb.std;
import com.questdb.log.RustLogging;
import io.questdb.jar.jni.JarJniLoader;
public class Qdb {
public static void init() {}
private static native void libInit();
static {
JarJniLoader.loadLib(
Qdb.class,
"/com/questdb/bin/",
"qdb");
libInit();
}
}
Multi-platform support is enabled by a common subdirectory naming convention
shared by the rust-maven-plugin and associated loading jar-jni libraries
(this is covered later in the article).
In the Java code above you might have noticed that we also do some library initialization.
In Rust, the libInit function allows us to save the JavaVM JNI object in a
global for later use.
We will need this to register Rust threads with the Java VM and allow them to call back into Java code, such as for logging.
// lib.rs
#[no_mangle]
pub extern "system" fn Java_com_questdb_std_QdbEnt_libInit(
mut env: JNIEnv,
_class: JClass,
) {
let vm = unwrap_or_throw!(env, env.get_java_vm());
unsafe {
JAVA_VM = Some(vm);
}
}
Here unwrap_or_throw is a macro that bubbles up any Rust error as a Java
exception.
#[macro_export]
macro_rules! unwrap_or_throw {
($env:expr, $res:expr, $(, $sentinel:literal)?) => {
match $result {
Ok(result) => result,
Err(e) => {
let throwable = $env.exception_occurred().unwrap();
if throwable.is_null() {
$env.throw_new(
"java/lang/RuntimeException",
&format!("{}", e)
)
.expect("failed to throw java exception");
}
return $($sentinel)?;
}
}
};
}
A few notes about JNI
A full explanation of JNI is beyond the scope of this blog post, but I'll touch on a few key points to provide context on the code above.
Earlier, lib.rs registered a JavaVM object as a global. This is the "root"
object that represents the loaded Java runtime and there's one per process. It
doesn't allow us to create or introspect objects, however. That job is delegated
to JNIEnv objects that are associated with individual threads.
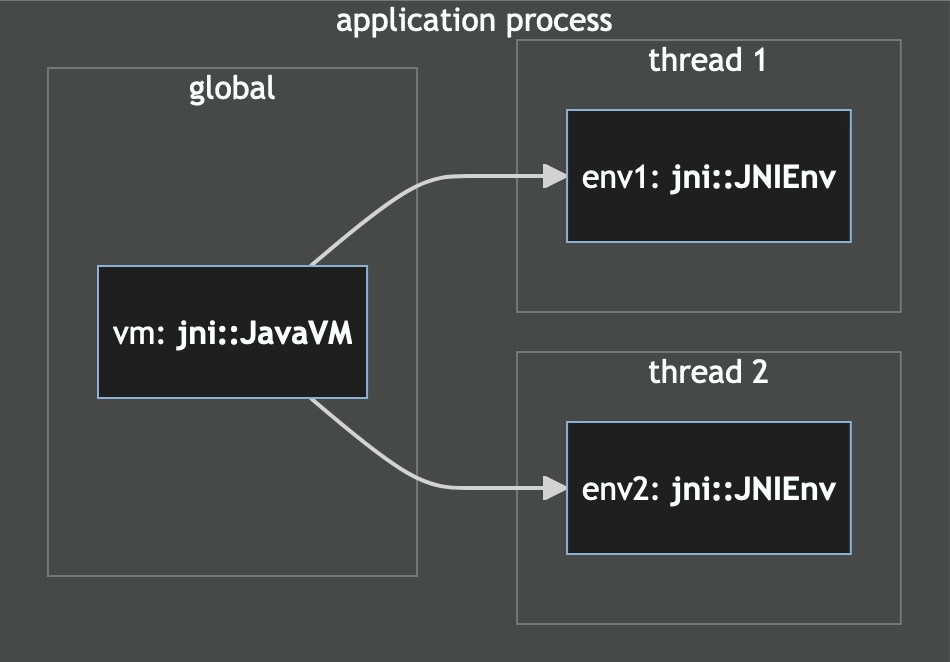
Each time any code is invoked from Java, JNI provides access to the thread's
JNIEnv object for our use through the JNI call. With this, we can read and
create Java strings or call other Java methods. If we wish to call into Java
from a thread that wasn't created from Java, we must first register it via the
JavaVM object. This will give us a handle to a new JNIEnv object for our
non-Java thread.
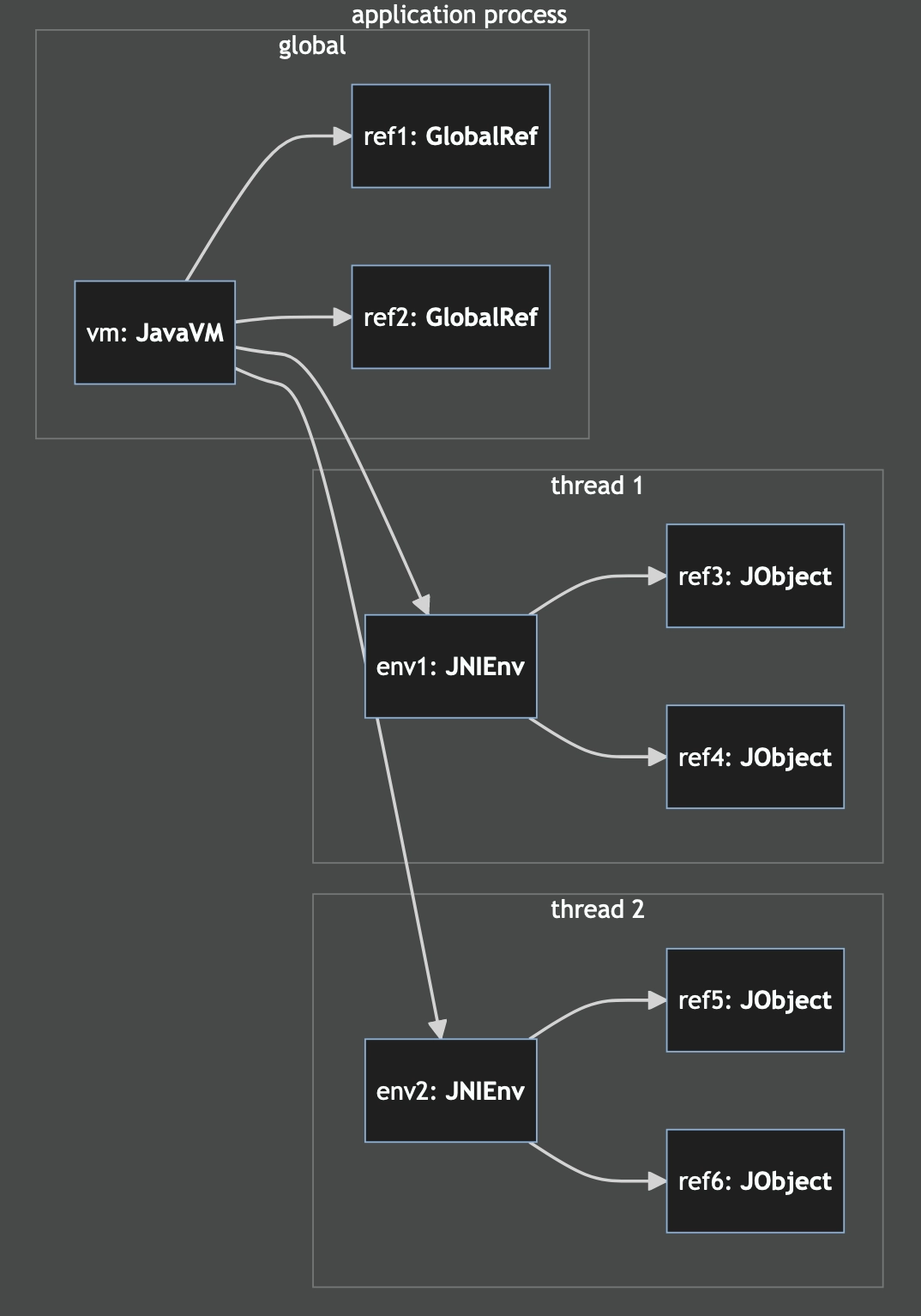
Next is understanding Java object references. These are pointers from the native
code back into objects managed by the JVM. They create a new root and prevent
the object from being garbage collected. These come in two kinds: Local
references (jni::objects::JObject) and global references
(jni::objects::GlobalRef).
When we obtain references, these are - at first - always local ones. If the native call was initiated from Java, the local references live for the duration of the native call. When initiated from Rust they last the duration of the thread unless they are dropped explicitly.
Local references can be converted to global references. This extends their lifetime until the global reference is dropped and also allows the Java object to be passed to other threads.
In the next section, we'll see some of these concepts in use, integrating Java and Rust code.
Integrating Rust and Java logging
The Java logging layer in QuestDB is custom, but we've managed to wire it up to
the ubiquitous rust log crate to send all Rust logging to Java.
Integrating logging is valuable: It not only allows us to sprinkle info! and
error! logs throughout our code, but also gives us an insight into other
dependencies we might be working with. QuestDB, for example, uses Rust to read
and write data to AWS S3. Having our database log messages interspersed with
those of the aws_sdk_s3 crate simplifies debugging.
Showing how we bound our logging layer would be too lengthy. Instead here I'll simplify things while still demonstrating the approach. You'll see examples of calling Rust from Java, Java from Rust, and how we can sometimes avoid expensive String copies.
The starting point for the simplified example has a single Log class:
- The
getLogstatic method creates or obtains aLogobject, looked up by a key (a module name in Rust). - The
infoinstance method is designed to be efficiently called from Rust: It logs a message by accepting amsgLenargument holding the number of bytes in the UTF-8 string passed in through themsgPtraddress. We do this because our destination file is already UTF-8 and we want to avoid text encoding conversions and the garbage collection involved in using Java Strings. In our Java code, we then use thesun.misc.Unsafeclass to deal with raw buffer. - The class's static initialization block invokes
Qdb.init()to ensure that the Rust dynamic library is loaded and then calls the static native methodsetup.
package com.questdb.log;
public class Log {
public static Log getLog(String key) { ... }
public void info(int msgLen, long msgPtr) { ... }
private static native void setup();
static {
Qdb.init();
setup();
}
}
Here is the Rust code called during initialization:
struct CallState {
/// Map a Rust module name to a Java `Log` object.
logs: DashMap<Box<str>, GlobalRef>,
log_class: GlobalRef,
log_get_log_meth: JStaticMethodID,
log_info_meth: JMethodID,
}
static mut CALL_STATE: Option<CallState> = None;
#[no_mangle]
pub extern "system" fn Java_com_questdb_log_Log_setup(
mut env: JNIEnv,
_class: JClass,
) {
let call_state = unwrap_or_throw!(env, CallState::new(&mut env));
unsafe {
CALL_STATE = Some(call_state);
}
unwrap_or_throw!(env, setup_logger());
}
The call state is what we need to keep the logger working. Along with the method
ID JNI objects, we also initialize an empty concurrent hashmap
(logs: DashMap<..>) which will associate one Java Log object per Rust module
name (as provided by the Rust log crate — more on this later).
Creating the call state is pretty straightforward and revolves around a few lookups. These lookups are always best done during start-up where they can fail early, increasing the likelihood of catching any potential JNI binding bugs during the development process.
impl CallState {
fn new(env: &mut JNIEnv) -> jni::errors::Result<Self> {
let logs = DashMap::new();
let class_name = "com/questdb/log/Log";
let log_class = env.find_class(class_name)?;
let log_class = env.new_global_ref(log_class)?;
let log_get_log_meth = env.get_static_method_id(
class_name, "getLog", "(Ljava/lang/String;)Lcom/questdb/log/Log;")?;
let log_info_meth = env.get_method_id(class_name, "info", "(IJ)V")?;
Ok(Self { logs, log_class, log_get_log_meth, log_info_meth })
}
// ...
}
Next, we need a "trampoline" logger: The Rust log crate funnels all calls to a
single object. One of the arguments we receive for each log line is the
target, a &str holding the name of the module we're logging for.
The trampoline logger is an empty struct that implements the log::Log trait.
struct TrampolineLogger;
impl Log for TrampolineLogger {
fn enabled(&self, metadata: &log::Metadata) -> {
// Discard JNI log messages to avoid infinite loops.
!metadata.target().starts_with("jni");
}
fn log(&self, record: &log::Record) {
if !self.enabled(record.metadata()) {
return;
}
let mut env = crate::JAVA_VM
.expect("JavaVM init").
.attach_current_thread_permanently()
.expect("failed to attach jni env");
let call_state = unsafe {
CALL_STATE.as_ref().expect("Log call state init")
};
let msg = format_msg(record.line(), record.args());
call_state.with_log(env, record.target(), |env, log| {
let msg_len = JValue::Int(msg.len() as jint);
let msg_ptr = JValue::Long(msg.as_ptr() as jlong);
let res = unsafe {
env.call_method_unchecked(
log,
call_state.log_info_meth,
ReturnType::Primitive(Primitive::Void),
&[msg_len.as_jni(), msg_ptr.as_jni()])
};
match res {
Ok(_) => {}
Err(jni::errors::Error::JavaException) => {
env.exception_describe().expect("describe");
eprintln!("Failed to log {msg}");
}
}
});
}
fn flush(&self) {}
}
In the code above, the format_msg function uses a thread-local and returns a
&str:
thread_local! {
static BUF: UnsafeCell<String> = UnsafeCell::new(String::with_capacity(64));
}
fn get_formatted_msg<'a>(
line_num: Option<u32>,
args: &fmt::Arguments,
) -> &'a str {
BUF.with(|msg: &UnsafeCell<String>| {
let msg: &mut String = unsafe { &mut *msg.get() };
msg.clear();
if let Some(line_num) = line_num {
write!(msg, "ℓ{} ", line_num).unwrap();
}
msg.write_fmt(*args).unwrap();
msg.as_str()
})
}
The call_state.with_log method performs a hashmap lookup returning a cached
Java Log object (GlobalRef in Rust) or constructs a new one if needed.
The concurrent map lookup-or-insert code does some "gymnastics" to allow looking
up by &str and avoids allocating a new Box<str> as would otherwise be
required by the more commonly used DashMap::entry API.
impl CallState {
// ...
fn with_log<F, R>(&self, env: &mut JNIEnv, name: &str, f: F) -> R
where
F: FnOnce(&mut JNIEnv, &GlobalRef) ->R,
{
let shard_index = self.logs.determine_map(name);
let mut shard_guard = unsafe {
self.impls.shards().get_unchecked(shard_index)
}.write();
let shard = shard_guard.deref_mut();
let (_, shared_log_wrapper) = shard.raw_entry_mut().from_key(name)
.or_insert_with(|| {
let boxed_name = name.to_string().into_boxed_str();
let log_wrapper = JavaLog::new(self, jenv, name);
let shared_log_wrapper = SharedValue::new(log_wrapper);
(boxed_name, shared_log_wrapper)
});
let log_wrapper = shared_log_wrapper.get();
f(env, log_wrapper)
}
}
Finally, all that's left is to register the trampoline logger in the
setup_logger function:
const TRAMPOLINE_LOGGER: TrampolineLogger = TrampolineLogger;
static INSTALL_JNI_LOGGER_ONCE: Once = Once::new();
fn setup_logger() -> jni::errors::Result<()> {
let mut result = Ok(());
INSTALL_JNI_LOGGER_ONCE.call_once(|| {
result = lookup_and_set_java_call_info(env)
.and_then(|_| {
log::set_logger(&TRAMPOLINE_LOGGER).map_err(|e| {
env.throw_new(
"java/lang/RuntimeException",
&format!("Could not set Rust logger: {}", e),
)
.unwrap();
jni::errors::Error::JavaException
})
})
.map(|_| {
log::set_max_level(LevelFilter::Debug);
});
});
result
}
Developer Workflow
With JNI covered, we can proceed to the more mundane — but often overlooked — aspects of cross-language development: IDE setup and continuous integration.
IntelliJ
We use IntelliJ for all of our Java development. The IDE also provides an excellent Rust plugin allowing us to edit all our code from one single tool.
When IntelliJ loads up a Maven project it parses it and uses its own Java
compiler instead of invoking mvn commands. This means that by default
rebuilding from the IDE will compile the Java code, but not the Rust code.
To work around this limitation: While IntelliJ can't run custom commands before a build, it can invoke Ant targets.
As such we wrote a little Ant glue to call Maven. The idea of bringing in Ant
may sound painful at first, but it's reassuringly simple. The Ant file gets
committed in git and shared with the team.
With this setup, the development workflow is seamless and allows us to edit some Rust code and immediately then run one of the Java test cases: The Rust crate is rebuilt automatically.
Our intellij-triggers.xml buildfile determines the right Maven executable,
then calls the configured rust-maven-plugin execution by its ID.
mvn org.questdb:rust-maven-plugin:build@qdb-build
The reason to build the Rust code via the rust-maven-plugin instead of
invoking cargo build directly is that the plugin additionally copies the
generated dynamic lib to its final target/classes destination, ready to be
loaded by the Java code.
<project name="qdb" default="qdb-build" basedir="..">
<description>
IntelliJ integration to trigger maven steps to build "qdb" via Ant.
</description>
<condition property="isWindows">
<os family="windows"/>
</condition>
<condition property="isUnix">
<os family="unix"/>
</condition>
<target name="set-mvn-path-windows" if="isWindows">
<property name="maven.executable" value="mvn.cmd"/>
</target>
<target name="set-mvn-path-unix" if="isUnix">
<property name="maven.executable" value="mvn"/>
</target>
<target name="qdb-build" depends="set-mvn-path-windows, set-mvn-path-unix">
<exec executable="${maven.executable}">
<arg value="org.questdb:rust-maven-plugin:build@qdb-build"/>
</exec>
</target>
<target name="qdb-build-release" depends="set-mvn-path-windows, set-mvn-path-unix">
<exec executable="${maven.executable}">
<arg value="org.questdb:rust-maven-plugin:build@qdb-build"/>
<arg value="-Pqdb-release"/>
</exec>
</target>
</project>
There's also a config file for IntelliJ that just tells the IDE what to do. Its
location is .idea/ant.xml. This file is also checked into git.
<?xml version="1.0" encoding="UTF-8"?>
<project version="4">
<component name="AntConfiguration">
<buildFile url="file://$PROJECT_DIR$/rust/intellij_triggers.xml">
<executeOn event="beforeCompilation" target="qdb-build" />
</buildFile>
</component>
</project>
Once set up, this integration can be seen in the Ant tool window (View → Tool Windows → Ant) in IntelliJ.
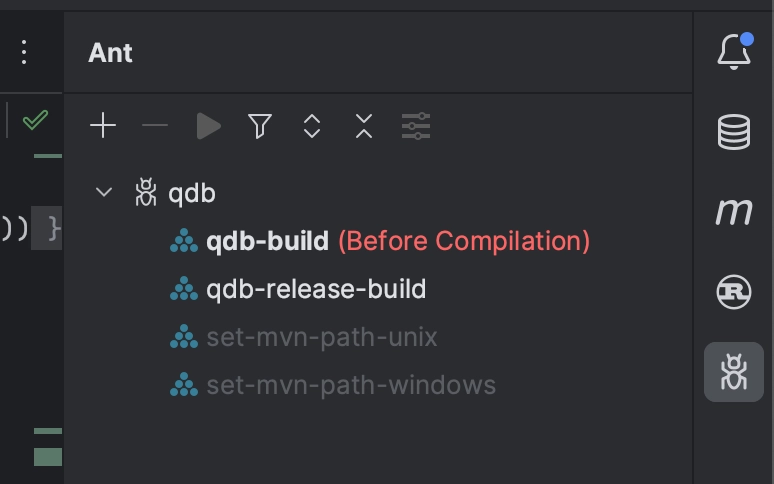
Now each time IntelliJ builds the Java code, it will also build the Rust code. The Ant tool window also allows switching over to building the release binaries instead (Right-click → Execute on → Before compilation).
Building release for multiple platforms
Building for multiple platforms is still quite manual for us, but are in the process of fully automating it in CI.
For now, locally on Apple M1 (because we don't have Apple Silicon cloud compute yet):
mvn compile -Pqdb-release
This step builds both Java class files and Rust binaries.
Then for each other platform:
mvn org.questdb:rust-maven-plugin:build@qdb-build -Pqdb-release
Remotely, this generates binaries in platform-specific directories, so we copy them back to our Apple Silicon dev machine.
Back on our local dev box, we end up with the following structure:
target/classes/com/questdb/bin
darwin-aarch64/libqdb.dylib
darwin-x86-64/libqdb.dylib
linux-x86-64/libqdb.so
linux-aarch64/libqdb.so
win32-x86-64/qdb.dll
Finally, we package a complete JAR.
mvn package
Running Rust tests from Maven
In our pom.xml, we create a test execution that invokes cargo test via the
rust-maven-plugin when running mvn test.
<plugin>
<groupId>org.questdb</groupId>
<artifactId>rust-maven-plugin</artifactId>
<version>1.1.1</version>
<executions>
<execution>
<id>qdb-build</id>
<!--
... as before ...
-->
</execution>
<execution>
<id>qdb-test</id>
<goals>
<goal>test</goal>
</goals>
<configuration>
<path>rust/qdb</path>
<release>${qdb.release}</release>
</configuration>
</execution>
</executions>
</plugin>
Upcoming QuestDB features in Rust
Our first use of Rust is in our "enterprise" source code repository. In addition to our open-source database releases, the QuestDB Enterprise edition offers enhanced features, catering specifically to enterprise customers. This advanced version is available in QuestDB Enterprise.
Rust, along with some of the features mentioned below, will eventually be integrated into our open-source GitHub repository.
Here is the pipeline of features we're currently building in Rust:
- Replication
- Cold Storage
- Native SSL/TLS
- Authentication Cryptography
Replication
QuestDB will offer primary-replica replication with eventual consistency by using an object store (S3, HDFS, etc) as a replication conduit.
Replication will work by electing a single "primary" database that uploads a copy of each table's WAL files onto a remote object store so these can be downloaded and applied (at a later time or continuously) by zero or more separate "replica" QuestDB instances.
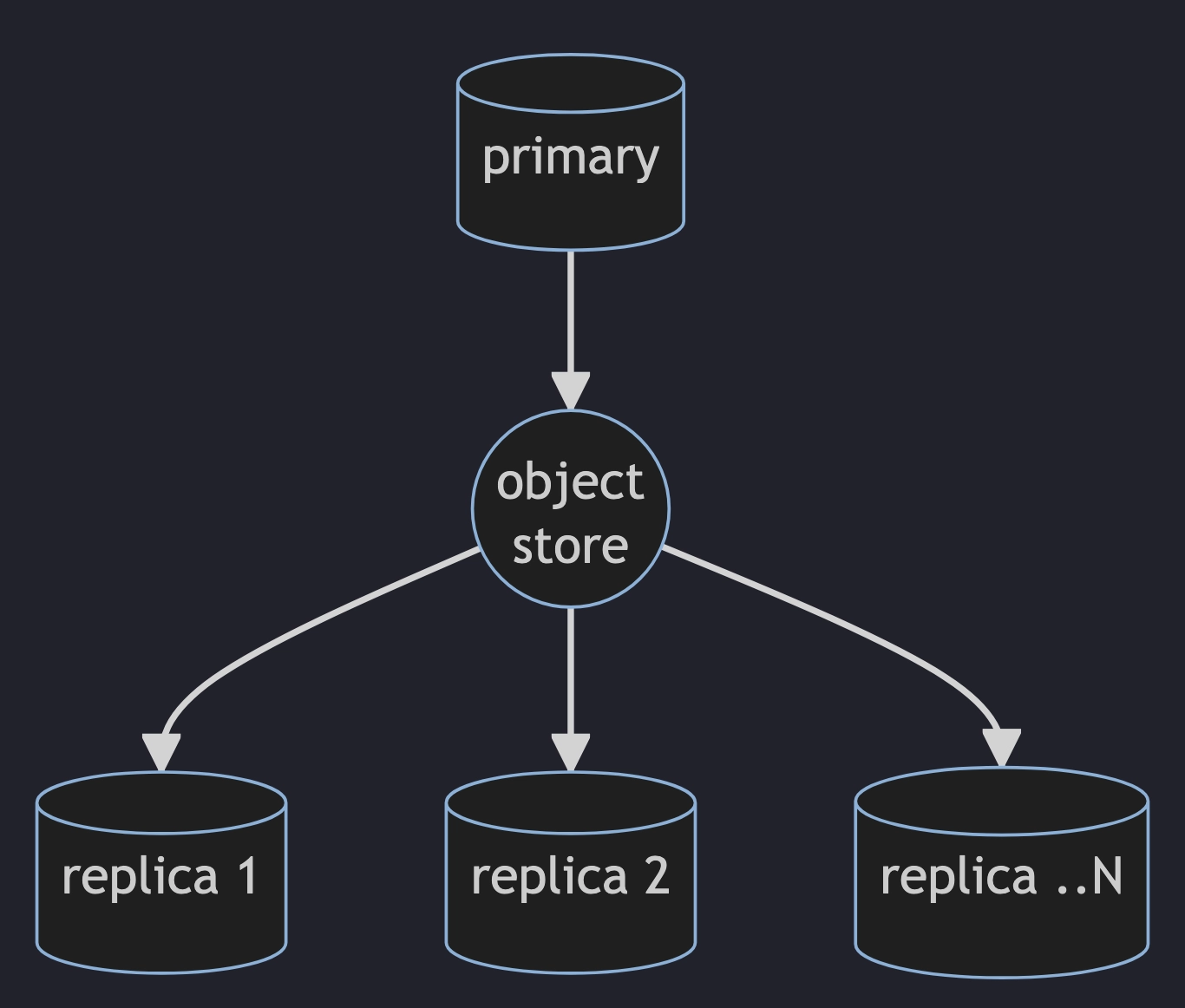
We are using Rust to compress, upload, download, and recreate the WAL data. We
are currently using the aws-sdk-s3 crate directly, but are in the process of
transitioning over to the opendal crate. We've also managed to integrate
tokio into our setup.
Cold Storage in Parquet
Tables in QuestDB are columnar, but written in partitions (usually daily). Our cold storage feature will transparently relocate partitions over a certain age threshold onto an object store (S3, HDFS). The data will be stored as Apache Parquet.
These remotely stored Parquet partitions will not only remain queriable within QuestDB (which will fetch them just-in-time dynamically) but also be accessible from big-data tools like Apache Spark, Impala, etc.
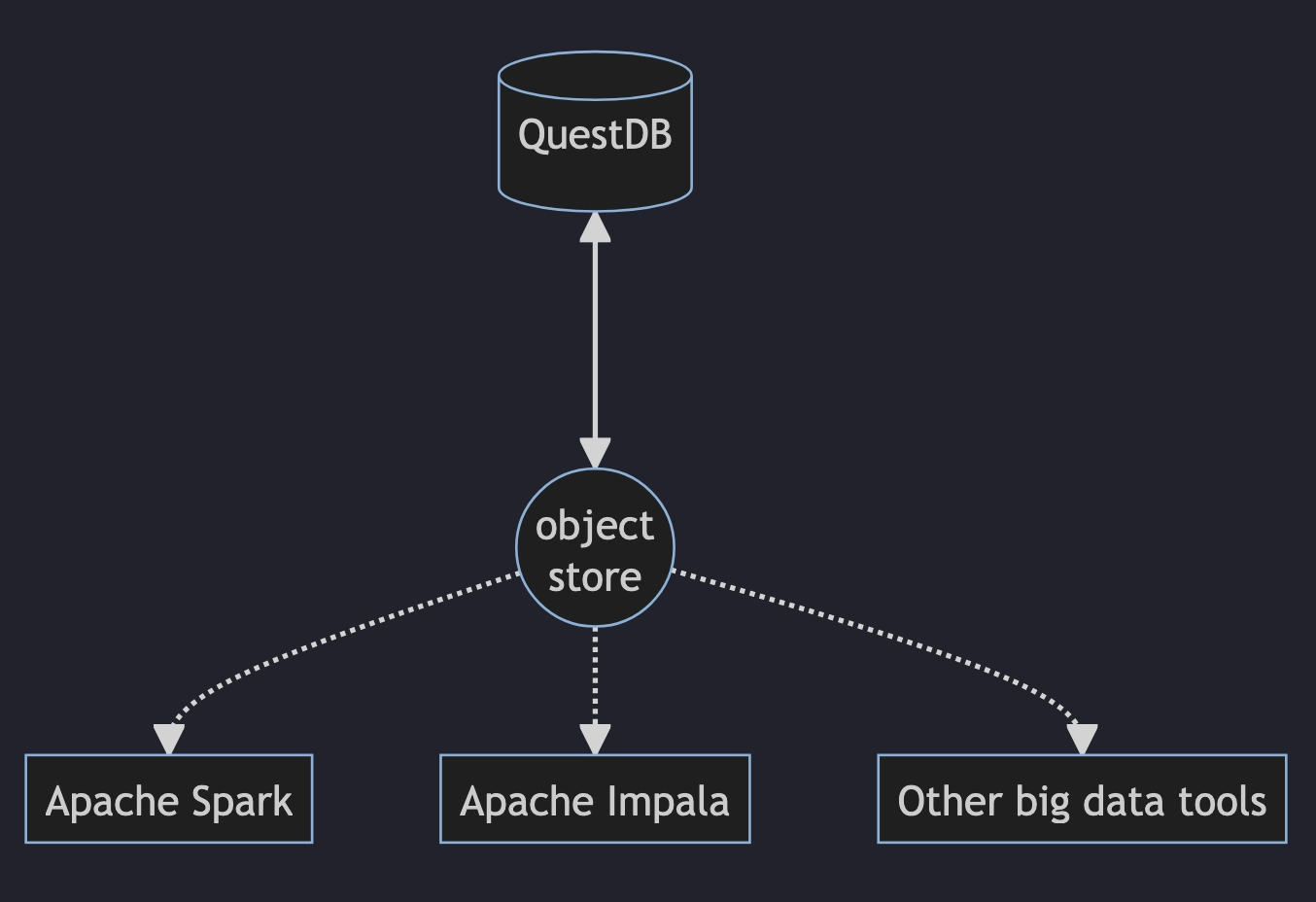
Even discounting the ability to use external tools, cold storage will allow using cheaper, slower storage for less frequently accessed data.
Rust is playing a major role here where we're using the
arrow and
parquet crates.
Native SSL/TLS
At the moment QuestDB relies on an external proxy process to serve secure HTTPS. The extra network hop complicates deployment and can cause bottlenecks in certain high-throughput scenarios. Our attempts using the Java libraries for TLS resulted in poor performance.
Instead, we're looking to integrate with the
rustls crate. Since all our network
operations are already implemented in JNI we can do this without crossing the
JNI layer any more often than we are already doing.
Authentication Cryptography
Our enterprise product has access control lists (ACL) and as part of that feature, we're improving authentication across all our network endpoints (ILP fast streaming data ingestion, PostgreSQL query interface, HTTP Rest query interface).
These improvements are being written using the
rustls and
ring Rust crates.
We're seeing orders of magnitute performance improvements in hash verification.
A final thought
Writing as the person having introduced Rust to QuestDB, it's been reassuring to see other developers in the team learning the language enthusiastically. This enthusiasm is the best confirmation that the language is a good fit for us.
There are many other exciting challenges that we want to solve with Rust, especially with open-source features!
For us, Rust is here to stay.
