SIMD instructions are specific CPU instruction sets for arithmetic calculations that use synthetic parallelization. This approach allows us to perform the same calculations and operations on numerous data points simultaneously. This post describes how SIMD works with typical operation performance and describes additional optimizations we managed to achieve.
What are SIMD operations?
Instead of spreading the work across CPU cores, SIMD performs vector operations on multiple items using a single CPU instruction. In practice, if you were to add 8 numbers together, SIMD does that in 1 operation instead of 8. We get compounded performance improvements by combining SIMD with actual parallelisation and spanning the work across CPUs.
QuestDB 4.2 introduces SIMD instructions, which made our aggregations faster by 100x! QuestDB is available open source (Apache 2.0) . If you like what we do, please consider starring our repo following us on GitHub and starring our project.
As of now, SIMD operations are available for non-keyed aggregation queries, such
as select sum(value) from table. In future releases, we will extend these to
keyed aggregations, for example select key, sum(value) from table (note the
intentional omission of GROUP BY). This will also result in ultrafast
aggregation for time bucketed queries using SAMPLE BY.
How much faster is SIMD?
We ran performance tests using 2 different CPUs: the Intel 8850H and the AMD Ryzen 3900X. Both were running on 4 threads.
| Test | Query |
|---|---|
| sum of 1Bn doubles no nulls | create table zz as (select rnd_double() d from long_sequence(1000000000)); select sum(d) from zz; |
| sum of 1Bn ints | create table zz as (select rnd_int() i from long_sequence(1000000000)); select sum(i) from zz; |
| sum of 1Bn longs | create table zz as (select rnd_long() l from long_sequence(1000000000)); select sum(l) from zz; |
| max of 1Bn doubles | create table zz as (select rnd_double() d from long_sequence(1000000000)); select max(d) from zz; |
| max of 1Bn longs | create table zz as (select rnd_long() l from long_sequence(1000000000)); select max(l) from zz; |


The dataset producing the results shown above does not contain NULL values. Interestingly, when introducing nulls, QuestDB sum() query time is unchanged. This can be tested by creating the table as follows.
| Test | Query |
|---|---|
| sum of 1Bn doubles (nulls) | create table zz as (select rnd_double(5) d from long_sequence(1000000000)); select sum(d) from zz; |
How can we improve upon SIMD performance?
Our approach is currently slightly more complicated as we convert each 32-bit integer to a 64-bit long to avoid overflow. By removing this overhead and more, there is scope left to make our implementation faster in the future.
Benchmarking QuestDB versus Postgres performance
The execution times outlined above become more interesting once put into
context. This is how QuestDB compares to Postgres when doing a sum of 1 billion
numbers from a given table select sum(d) from 1G_double_nonNull.

We found that our performance figures are constrained by the available memory channels. Both the 8850H and the 3900X have 2 memory channels, and throwing more than 4 cores at the query above does not improve the performance. On the other hand, if the CPU has more memory channels, then performance scales almost linearly.
To get an idea of the impact of memory channels, we spun off a m5.metal instance on AWS. This instance has two 24-core Intel 8275CL with 6 memory channels each. Here are the results compared to the 2-channel 3900X:
| cpu cores | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8275CL | 910 | 605 | 380 | 240 | 193 | 176 | 156 | 148 | 140 | 136 | 133 | 141 |
| 3900X | 621 | 502 | 381 | 260 | 260 | 260 | 260 | 260 | 260 | 260 | 260 | 260 |
We plot those results below on the left. On the right-hand side, we normalise the results for each CPU and plot the performance improvement of going from 1 to more cores.
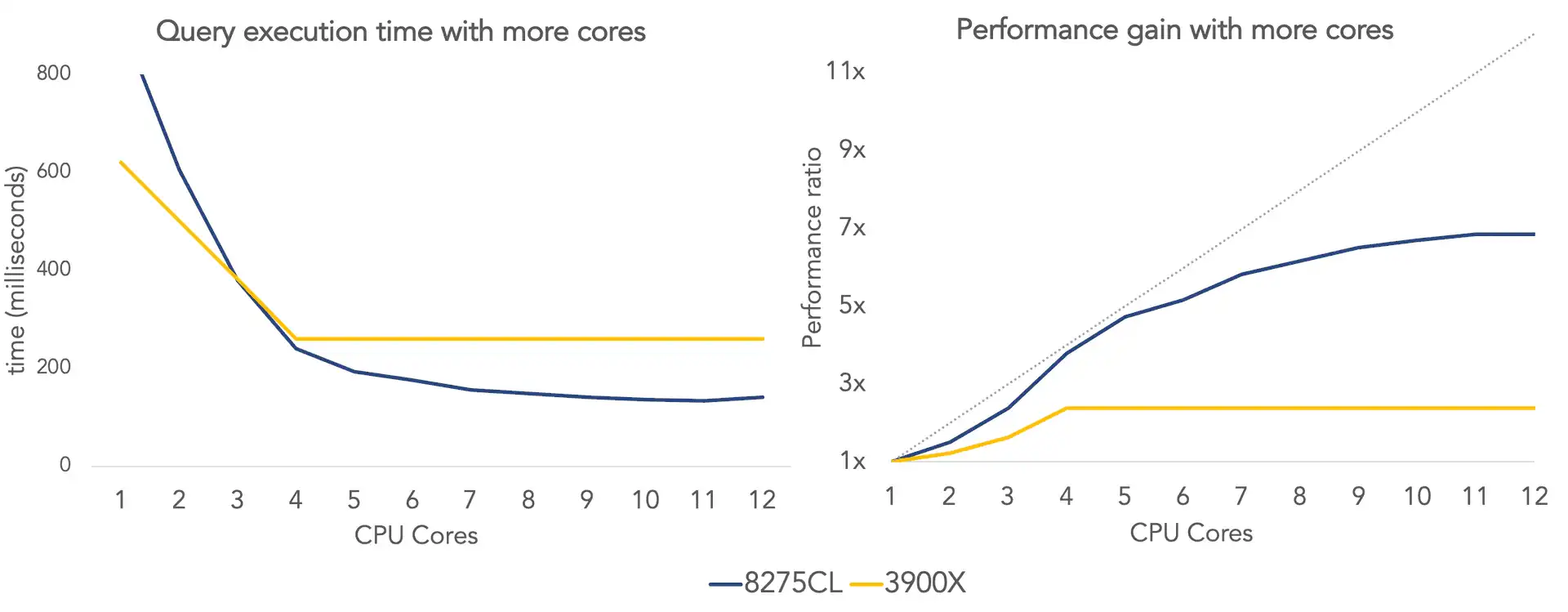
Interestingly, the 2-channel 3900X, is much faster on 1 core than the 8275CL. But it does not scale well and hits a performance ceiling at 4 cores. This is because it only has 2 memory channels that are already saturated. The 6-channel 8275CL allows QuestDB to scale almost linearly as we add more CPU cores and hits a performance ceiling at around 12 cores.
Unfortunately AWS CPUs are hyperthreaded. We could unpack even more performance if CPU were fully isolated to run the computations.
We did not get our hands on CPUs with more memory channels for this test, but if you have easy access to 8 or 12-channel servers and would like to benchmark QuestDB, we'd love to hear the results. You can download QuestDB and leave a comment on github.
How we will improve time series data performance
In further releases, we will roll out this functionality to other parts of our SQL implementation. QuestDB implements SIMD in a generic fashion, which will allow us to continue adding SIMD to about everything our SQL engine does, such as keyed aggregations, indexing etc. We will also keep improving QuestDB's performance. Through some further work on assembly, we estimate that we can gain another 15% speed on these operations. In the meantime, if you want to know exactly how we have achieved this, all of our code is open source!
About the release: QuestDB 4.2
We have implemented SIMD-based vector execution of queries, such as
select sum(value) from table. This is ~100x faster than non-vector based
execution. This is just the beginning as we will introduce vectors to more
operations going forward. Try our first implementation in this release - stay
tuned for more features in the upcoming releases!
Important
Metadata file format has been changed to include a new flag for columns of type
symbol. It is necessary to convert existing tables to new format. Running the
following SQL: repair table myTable will update the table metadata.
What is new?
- Java: vectorized sum(), avg(), min(), max() for DOUBLE, LONG, INT
- Java: select distinct symbol optimisation
- Automatically restore data consistency and recover from partial data loss.
What we fixed
- SQL: NPE when parsing SQL text with malformed table name expression , for example ')', or ', blah'
- SQL: parsing 'fill' clause in sub-query context was causing unexpected syntax error (#115)
- SQL: possible internal error when ordering result of group-by or sample-by
- Data Import: Ignore byte order marks (BOM) in table names created from an imported CSV (#114)
- SQL: 'timestamp' propagation thru group-by code had issues. sum() was tripping over null values. Added last() aggregate function. (#113)
- LOG: make service log names consistent on windows (#106)
- SQL: deal with the following syntax 'select * from select ( select a from ....)'
- SQL: allow the following syntax 'case cast(x as int) when 1 then ...'
- fix(griffin): syntax check for "case"-')' overlap, e.g. "a + (case when .. ) end"