QuestDB
Compare
Enterprise
Docs
Blog
Community
Search
8.1.0
Roadmap
Login
Download QuestDB
Popular topics
Benchmarks
Tutorials
Demos
User Stories
sql
grafana
market data
python
kafka
iot
telegraf
release
engineering
prometheus
k8s
pandas
All benchmark posts
BENCHMARK
QuestDB and Raspberry Pi 5 benchmark, a pocket-sized powerhouse
by
Nic Hourcard
on May 8, 2024
BENCHMARK
TimescaleDB vs. QuestDB: Performance benchmarks and overview
by
Nic Hourcard
on March 27, 2024
BENCHMARK
Benchmark and comparison: QuestDB vs. InfluxDB
by
Andrey Pechkurov
on February 26, 2024
BENCHMARK
Solving duplicate data with performant deduplication
by
Javier Ramirez
on November 16, 2023
BENCHMARK
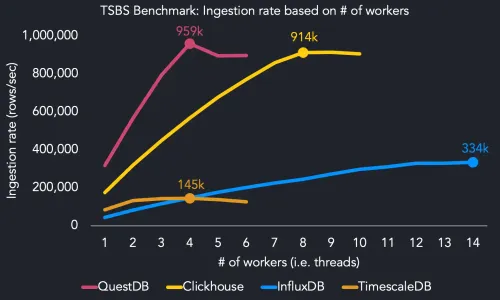
Optimizing the Optimizer: the Time-Series Benchmark Suite
by
Andrey Pechkurov
on May 18, 2023
BENCHMARK
MongoDB Time Series Benchmark and Review
by
QuestDB
on March 20, 2023
BENCHMARK
Importing 300k rows/sec with io_uring
by
Andrey Pechkurov
on September 12, 2022
BENCHMARK
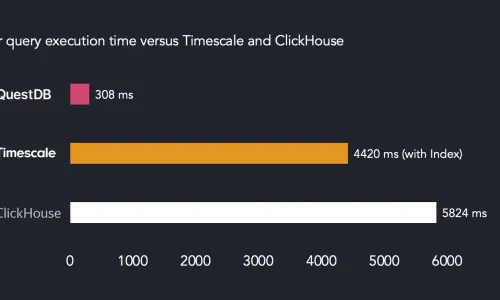
4Bn rows/sec query benchmark: Clickhouse vs QuestDB vs Timescale
by
Andrey Pechkurov
on May 26, 2022
BENCHMARK
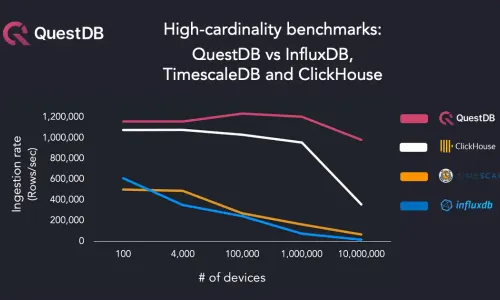
How databases handle 10 million devices in high-cardinality benchmarks
by
Vlad Ilyushchenko
on June 16, 2021
BENCHMARK
How we achieved write speeds of 1.4 million rows per second
by
Vlad Ilyushchenko
on May 10, 2021
BENCHMARK
Things we learned about sums
by
Tancrede Collard
on May 12, 2020
BENCHMARK
Aggregating billions of rows per second with SIMD
by
Tancrede Collard
on April 2, 2020

 Star us on GitHub
Star us on GitHub