DevStories is our brand-new series. We interview developers in our community to understand how they build applications with QuestDB. For the first post of this series, we are thrilled to interview Kevin Kamto, Co-founder at AthleteX.
Hi Kevin, could you tell us more about yourself?
My name is Kevin Kamto. I'm one of the core contributors and co-founders of AthleteX. That means that on a day to day basis, I operate as the head of sales and point of coordination for the team.
How did you get to know time series databases in the first place?
I've been working in the IoT space as a developer for many years. For a cool project I worked on, we needed to create a device that measured the WiFi usage in the company to observe the day to day patterns. That's when I got introduced to InfluxDB, one of the time series database pioneers at that time.
Tell us more about AthleteX, what is this project about?
This is the backstory: during the middle of COVID-19, there were a lot of markets seeing red. So we asked ourselves, what is an investor to do during this time? As someone who loves sports like soccer and basketball, I thought that if I could put my money towards an athlete, I could keep it safe.
This blog post is not investment advice. 😇
The idea of AthleteX is that you can invest in the performance of your favorite athletes. Essentially, we created a fantasy sports prediction market. You can go to the platform to either long or short the performance of an athlete by trading the Athlete Performance Tokens (APTs). The price of an APT is based on an athlete's in-game statistics. Taking baseball as an example, we determine price using the Wins Above Replacement (WAR) formula, and the price is updated in real-time.
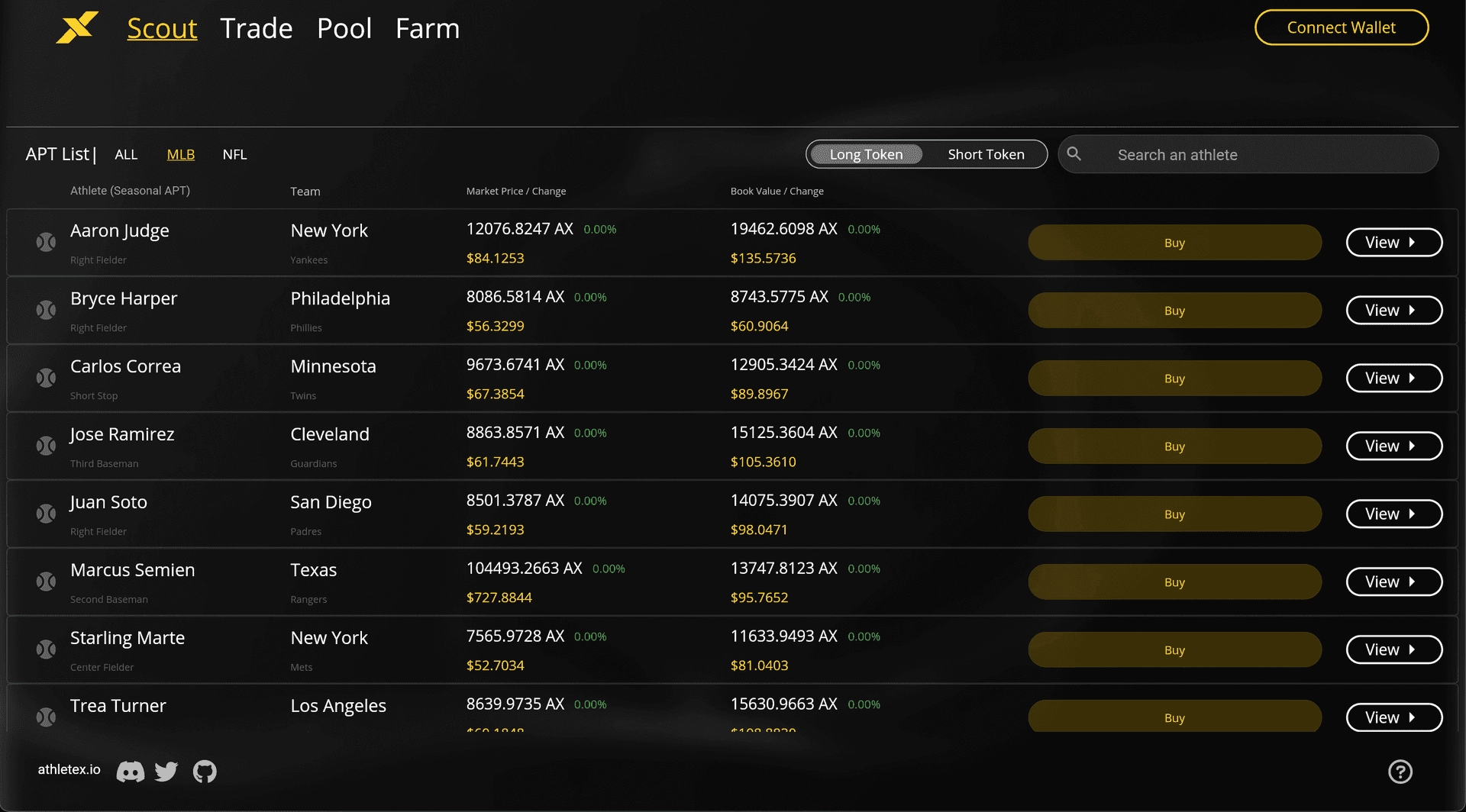
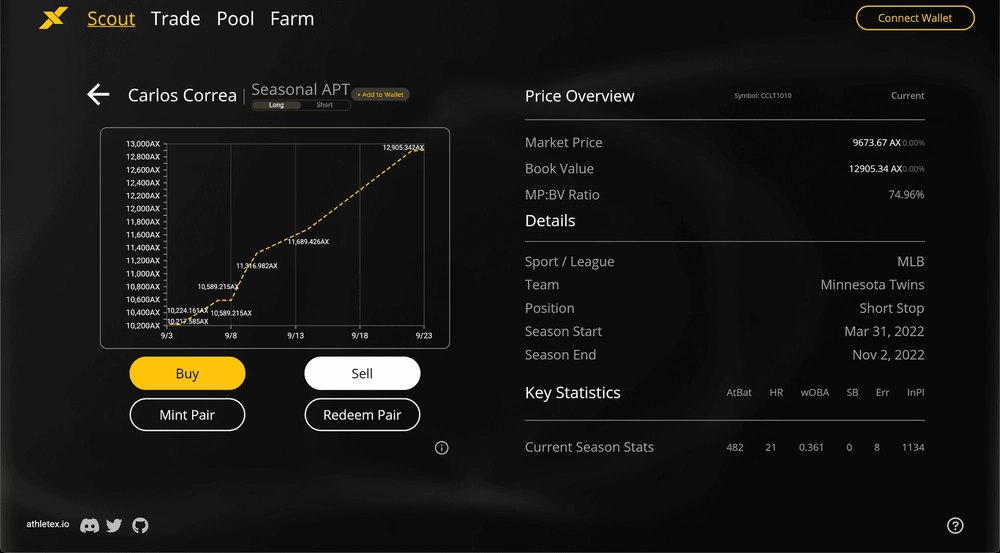
How is the use case related to time series databases?
Using MLB (baseball) as an example, some in-game metrics such as bats and home runs are generated every minute or every five minutes. We must store all that information over time. Coming from an IoT background, the problem is not new to me. So instead of going with something like MySQL or MongoDB, which didn't make a lot of sense, I knew that a time series database was what we needed.
Among all the available time series databases, why QuestDB?
QuestDB is faster than its competitors and goes above and beyond what we need it to handle at the current stage. It's also convenient to use SQL as the query language. At the moment, we store thousands of time series every minute and both the ingestion and querying performance has been satisfying. At scale, we anticipate hundreds of millions of data points and expect QuestDB to handle it smoothly.
Could you tell us more about the technical side of your use case and how QuestDB fits in?
QuestDB is the core foundation of our entire backend infrastructure. Due to the feed-type nature of our application and the need to look up athlete stats very fast, we need a database to manage large time series data sets while providing fast query speed.
Our data providers have all the sports related data for each season, sport, and player. And we have some Python scripts to grab all the data periodically, calculate the book value based on the WAR formula, and store it in QuestDB. QuestDB is the base layer that allows us to handle this kind of throughput. At the moment, we're storing nearly 2 millions records in QuestDB.
Further down in the data pipeline, we built an API using Kotlin to query QuestDB and show the charts on our frontend. And from this point on, it's more about the DeFi protocol than QuestDB, you can read our lite paper to get a deeper understanding on how our system was designed.
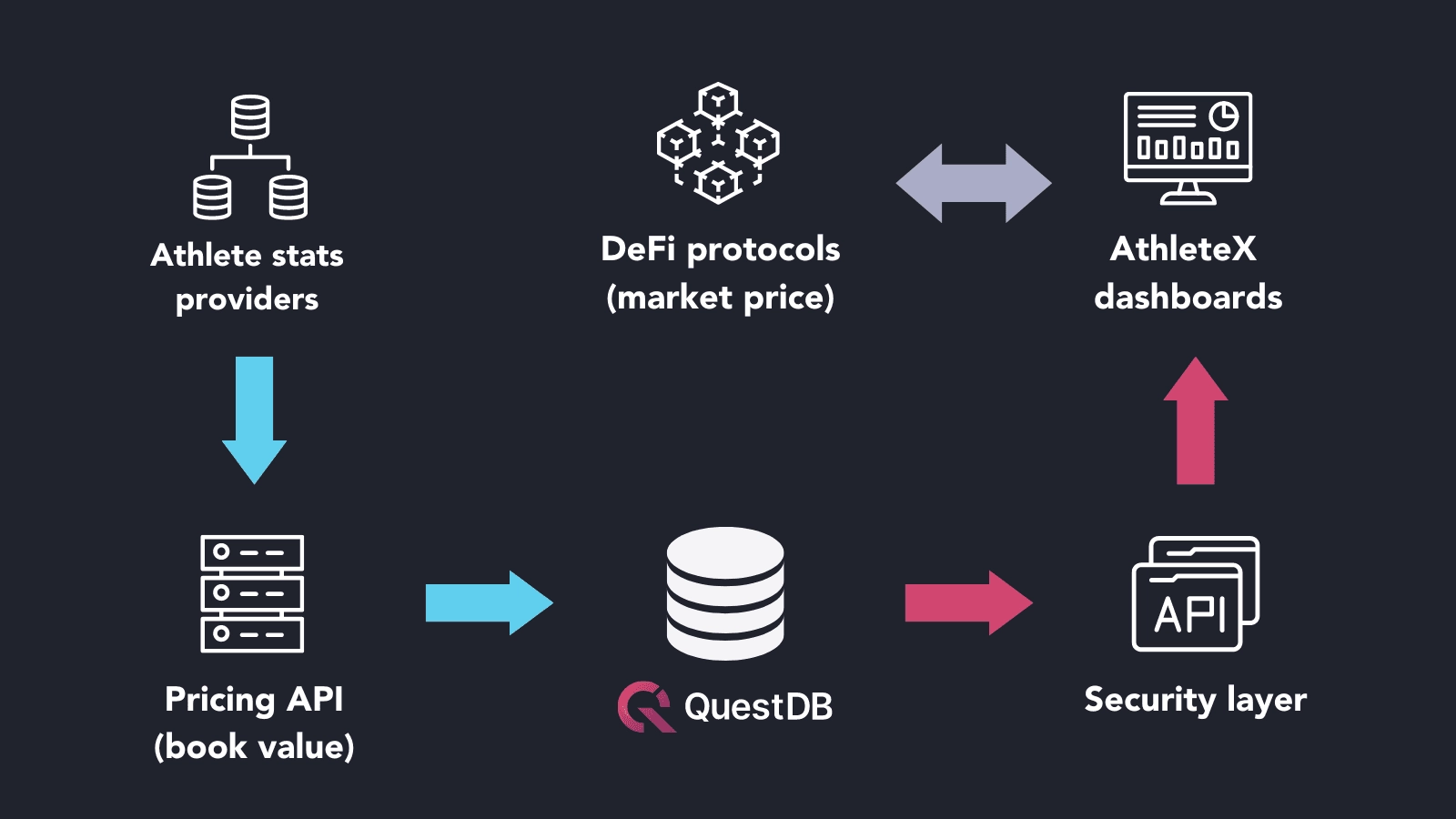
What are the most common queries you use for your application?
We often use simple SELECT statements together with WITH and ORDER BY. We
also dabbled with SAMPLE BY and the performance has been exemplary.
Were there any challenges you ran into with QuestDB? And how did you overcome it?
We wanted to allow some users to query QuestDB directly using the Web Console or some dashboards, without having access to drop or alter any tables. It was not possible to do that directly since it's lacking a security layer or built-in authentication. We ended up writing our own API for this purpose.
Insights from the QuestDB team: since
QuestDB 6.3, we
implemented a new configuration pg.security.readonly to toggle the read-only
mode for PostgreSQL Wire Protocol. Similarily, the existing
http.security.readonly can be applied to the
Web Console.
What are some of the new features or functionalities you really look forward to in QuestDB? And why?
High availability is one thing we look forward to seeing in QuestDB. For now we try to scale the resources with the single instance but it come at the expense of some downtime. Replication is an important feature to ensure that the data is echoed correctly across all the replicas.
We could also benefit a lot if QuestDB can work smoothly with Metabase or something similar to that. We've tried to create dashboards with Grafana but it doesn't appear to be as human friendly as products like Metabase, especially for the non-technical end users that we have.
Anything more you'd like to tell the readers?
AtheleteX 1.0.0 has just been released on Sept 10, 2022. If you're interested in learning more about the project, check out our release announcement!