Listen to Your CPU - Full-table Scans Are Fast
One of our core engineers, Jaromir Hamala, was inspired by an article comparing performance between index merging and composite indexes. He conducted a similar test on QuestDB's table scanning strategy. In this article, Jaromir explains the benefit of table scanning and shows the superior query performance it brings.
A Hacker News article: index merges and composite indexes
While browsing Hacker News, I stumbled upon an excellent article written by Simon Hørup Eskildsen: "Index Merges vs Composite Indexes in Postgres and MySQL". Simon compares index performance for queries using a conjunction of two attributes. This is a fancy way to say that an SQL query contains a predicate similar to this:
WHERE attribute1 = 'foo' AND attribute2 = 'bar;
The article does multiple things exceptionally well:
- It describes different strategies a database engine can use to evaluate the query: composite indexes v.s. merging results from individual indexes.
- It shows systematic thinking about performance. It tries to estimate expected performance results based on the capabilities of modern hardware in combination with educated guesses about how a database likely works. I found this part incredibly fascinating. Reasoning about performance from first principles is more than just cool. It helps to build a better intuition and deeper understanding of our tools.
- It shows the actual results from MySQL and PostgreSQL, discusses how they differ from the expected results, and tries to explain the reasons. Again, very enlightening!
While reading the article, I wondered: how would QuestDB perform in this scenario? My curiosity increased after reading a discussion on Hacker News - someone posted results from a similar query running on ClickHouse. So I thought that it'd be interesting to do a similar one on QuestDB!
To index or not index, that is the question
QuestDB - as many other analytical/OLAP databases - tends to rely on table scans rather than index lookups. This is due to the nature of analytical queries: they are typically more complex than OLTP queries and often touch a lot of data.
Table scanning also plays nicely with modern hardware: our hardware is incredibly fast in everything sequential. Sequential memory access is MUCH faster than random access. Sequential disk access allows deeper IO queues resulting in better performance than random access. Sequential access also offers optimization opportunities, such as using SIMD instructions to evaluate filters. Table scanning also means that there is no index to maintain, and therefore the concurrency model is simpler. This allows the utilization of multiple threads with very little inter-thread communication, which is costly. The simplicity also translates into another advantage: a straightforward query plan can be Just-In-Time compiled into a native code, increasing performance further.
Testing time
I did what every curious software engineer would do: I started an EC2 instance,
unpacked QuestDB, and started poking it. Specifically, I created an
m6a.8xlarge instance with 32 vCPU and 128GB of RAM. That is not a bad machine,
it's probably better than most development workstations. On the other hand, it's
not a super beefy machine for a database server. I also asked AWS to use GP3 as
block storage, but that was it. No further tuning; even all GP3 parameters were
left on defaults.
QuestDB installation is effortless. Download a tarball, unzip, and start it:
$ wget https://github.com/questdb/questdb/releases/download/6.6.1/questdb-6.6.1-rt-linux-amd64.tar.gz$ tar xzvf ./questdb-6.6.1-rt-linux-amd64.tar.gz$ cd ./questdb-6.6.1-rt-linux-amd64/bin/$ ./questdb.sh start
Then I used the builtin Web Console to create a table and populate it with data:
CREATE TABLE test_table (id long,text1 String,text2 String,int1000 long,int100 long,int10 long,int10_2 long);INSERT INTO test_tableSELECTrnd_long(),rnd_str(1, 1024, 1024, 0),rnd_str(1, 255, 255, 0),rnd_long(0, 999, 0),rnd_long(0, 99, 0),rnd_long(0, 9, 0),rnd_long(0, 9, 0)FROM long_sequence(10000000);
The INSERT query generates 10 million rows with random data roughly matching
the shape of the table and data from the original article.
And finally, the moment of truth: how fast will QuestDB run the aggregation with the same filter? Will it be faster than PostgreSQL's composite index? Or at least faster than MySQL's index merge? Will raw performance and mechanical sympathy outperform smart indexes? Here is the result:
SELECT count(*)FROM test_tableWHERE int100 = 1 AND int1000 = 1;
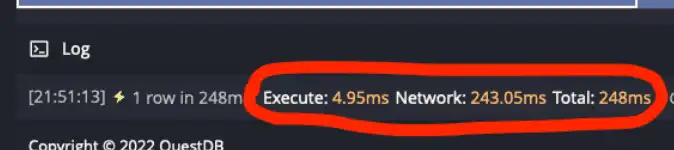
It shows the query execution time was just under 5 milliseconds! That is on par with the best result in the original blog, where PostgreSQL uses a composite index specialized for this shape of queries, and it's better than all other results in the original post! Once again, QuestDB does a full table scan. It does not use any fancy data structure to minimize the number of reads. It's just raw power and algorithms written to use the best out of your hardware.
The main advantage of this approach is clear: I did not have to prepare indexes upfront and specialized them for a given shape of a query. I could run a query filtering on a different combination of columns and the result would be very similar. This is a huge advantage for ad-hoc queries, which are very common in analytics.
Are indexes useless?
This is not a serious comparison, as I do not know the hardware specs used in the original post. Perhaps even more importantly, MySQL and PostgreSQL are very different beasts from time-series/analytical databases. They make different design and implementation trade-offs because they aim at different typical use cases. So what is the point of this article? It's simple:
- I wanted to satisfy my own curiosity :smile:
- I wanted to show how amazingly fast modern hardware is when we - the developers - are not sabotaging its inner working. Once again, The database scanned 10M rows in less than 5 ms, and I still find it incredible!
This is not to say indexes have no place in analytical databases. They still do: an index with great selectivity (think of a unique index) will outperform full table scans. Sparse indexes can be cheaper to maintain and help avoid scanning chunks of data. This can be very relevant in architectures where hot data is kept on fast local SSDs while cold data is kept on cheaper storages such as AWS S3. If an index can be used to avoid copying data from a cold storage then it's a performance (and cost!) win, too.
Further experiments
QuestDB is running a public demo where you can explore various datasets. My favorite example of a raw sequential performance is this super simple aggregation:
SELECT avg(trip_distance) FROM trips;
It aggregates 1.6B rows in under 0.5s! When I saw it for the first time, I assumed it must have been cached. Well, it's not. It's mechanical sympathy in practice!