Processing Time-Series Data with QuestDB and Apache Kafka
Apache Kafka is a battle-tested distributed stream-processing platform popular in the financial industry to handle mission-critical transactional workloads. Kafka's ability to handle large volumes of real-time market data makes it a core infrastructure component for trading, risk management, and fraud detection. Financial institutions use Kafka to stream data from market data feeds, transaction data, and other external sources to drive decisions.
A common data pipeline to ingest and store financial data involves publishing real-time data to Kafka and utilizing Kafka Connect to stream that to databases. For example, the market data team may continuously update real-time quotes for a security to Kafka, and the trading team may consume that data to make buy/sell orders. Processed market data and orders may then be saved to a time series database for further analysis.
In this article, we'll create a sample data pipeline to illustrate how this could work in practice. We will poll an external data source (FinnHub) for real-time quotes of stocks and ETFs, and publish that information to Kafka. Kafka Connect will then grab those records and publish it to a time series database (QuestDB) for analysis.
Prerequisites
- Git
- Docker Engine: 20.10+
- Golang 1.19+
- FinnHub API Token
Setup
To run the example locally, first clone the repo
The codebase is organized into three parts:
- Golang code is located at the root of the repo
- Dockerfile for the Kafka Connect QuestDB image and the Docker Compose YAML file is under docker
- JSON files for Kafka Connect sinks are under
kafka-connect-sinks
Building the Kafka Connect QuestDB Image
We first need to build the Kafka Connect docker image with QuestDB Sink
connector. Navigate to the docker directory and run docker-compose build.
The Dockerfile is simply installing the Kafka QuestDB Connector via Confluent Hub on top of the Confluent Kafka Connect base image:
FROM confluentinc/cp-kafka-connect-base:7.3.2\RUN confluent-hub install --no-prompt questdb/kafka-questdb-connector:0.6
Start Kafka, Kafka Connect, QuestDB
Next, we will set up the infrastructure via Docker Compose. From the same
docker directory, run Docker Compose in the background:
docker-compose up -d
This will start Kafka + Zookeeper, our custom Kafka Connect image with the QuestDB Connector installed, as well as QuestDB. The full content of the Docker Compose file is as follows:
---version: "2"services:zookeeper:image: confluentinc/cp-zookeeper:7.3.2hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000broker:image: confluentinc/cp-kafka:7.3.2hostname: brokercontainer_name: brokerdepends_on:- zookeeperports:- "9092:9092"- "9101:9101"environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXTKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1KAFKA_JMX_PORT: 9101KAFKA_JMX_HOSTNAME: localhostkafka-connect:image: cp-kafka-connect-questdbbuild:context: .hostname: connectcontainer_name: connectdepends_on:- broker- zookeeperports:- "8083:8083"environment:CONNECT_BOOTSTRAP_SERVERS: "broker:29092"CONNECT_REST_ADVERTISED_HOST_NAME: connectCONNECT_REST_PORT: 8083CONNECT_GROUP_ID: compose-connect-groupCONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configsCONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsetsCONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1CONNECT_STATUS_STORAGE_TOPIC: docker-connect-statusCONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverterCONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverterquestdb:image: questdb/questdbhostname: questdbcontainer_name: questdbports:- "9000:9000"- "9009:9009"
Start the QuestDB Kafka Connect Sink
Wait for the Docker containers to be healthy (the kafka-connect image will log "Finished starting connectors and tasks" message), and we can create our Kafka Connect sinks. We will create two sinks: one for Tesla and one for SPY (SPDR S&P 500 ETF) to compare price trends of a volatile stock and the overall market.
Issue the following curl command to create the Tesla sink within the
kafka-connect-sinks directory:
curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @questdb-sink-TSLA.json http://localhost:8083/connectors
The JSON file it posts contains the following configurations.
{"name": "questdb-sink-SPY","config": {"connector.class": "io.questdb.kafka.QuestDBSinkConnector","tasks.max": "1","topics": "topic_SPY","key.converter": "org.apache.kafka.connect.storage.StringConverter","value.converter": "org.apache.kafka.connect.json.JsonConverter","key.converter.schemas.enable": "false","value.converter.schemas.enable": "false","host": "questdb","timestamp.field.name": "timestamp"}}
Create the sink for SPY as well:
curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @questdb-sink-SPY.json http://localhost:8083/connectors
Streaming real-time stock quotes with Apache Kafka and QuestDB
Now that we have our data pipeline set up, we are ready to stream real time stock quotes to Kafka and store them in QuestDB.
First, we need to get a free API token from Finnhub Stock API. Create a free account online and copy the API key.
Export that key to our shell under FINNHUB_TOKEN:
export FINNHUB_TOKEN=<my-token-here>
The realtime quote endpoint returns various attributes such as the current price, high/low/open quotes, as well as previous close price. Since we are just interested in the current price, we only grab the price and add the ticket symbol and timestamp to the Kafka JSON message.
The code below will grab the quote every 30 seconds and publish to the Kafka
topic: topic_TSLA .
package mainimport ("encoding/json""fmt""io/ioutil""net/http""os""time""github.com/confluentinc/confluent-kafka-go/v2/kafka")type StockData struct {Price float64 `json:"c"`}type StockDataWithTime struct {Symbol string `json:"symbol"`Price float64 `json:"price"`Timestamp int64 `json:"timestamp"`}func main() {// Create a new Kafka producer instancep, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost:9092"})if err != nil {panic(fmt.Sprintf("Failed to create producer: %s\n", err))}defer p.Close()for {token, found := os.LookupEnv("FINNHUB_TOKEN")if !found {panic("FINNHUB_TOKEN is undefined")}symbol := "TSLA"url := fmt.Sprintf("https://finnhub.io/api/v1/quote?symbol=%s&token=%s", symbol, token)// Retrieve the stock dataresp, err := http.Get(url)if err != nil {fmt.Println(err)return}defer resp.Body.Close()// Read the response bodybody, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println(err)return}// Unmarshal the JSON data into a structvar data StockDataerr = json.Unmarshal(body, &data)if err != nil {fmt.Println(err)return}// Format data with timestamptsData := StockDataWithTime{Symbol: symbol,Price: data.Price,Timestamp: time.Now().UnixNano() / 1000000,}jsonData, err := json.Marshal(tsData)if err != nil {fmt.Println(err)return}topic := fmt.Sprintf("topic_%s", symbol)err = p.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},Value: jsonData,}, nil)if err != nil {fmt.Printf("Failed to produce message: %s\n", err)}fmt.Printf("Message published to Kafka: %s", string(jsonData))time.Sleep(30 * time.Second)}}
To start streaming the data, run the code:
$ go run main.go
To also get data for SPY, open up another terminal window, modify the code for the symbol to SPY and run the code as well with the token value set.
Result
After running the producer code, it will print out messages that it sends to
Kafka like:
Message published to Kafka: {"symbol":"TSLA","price":174.48,"timestamp":1678743220215} .
This data is sent to the Kafka topic topic_TSLA and sent to QuestDB via the
Kafka Connect sink.
We can then navigate to http://localhost:9000 to access the QuestDB console. Searching for all records in the topic_TSLA table, we can see our real-time market quotes:
SELECT * FROM 'topic_TSLA'
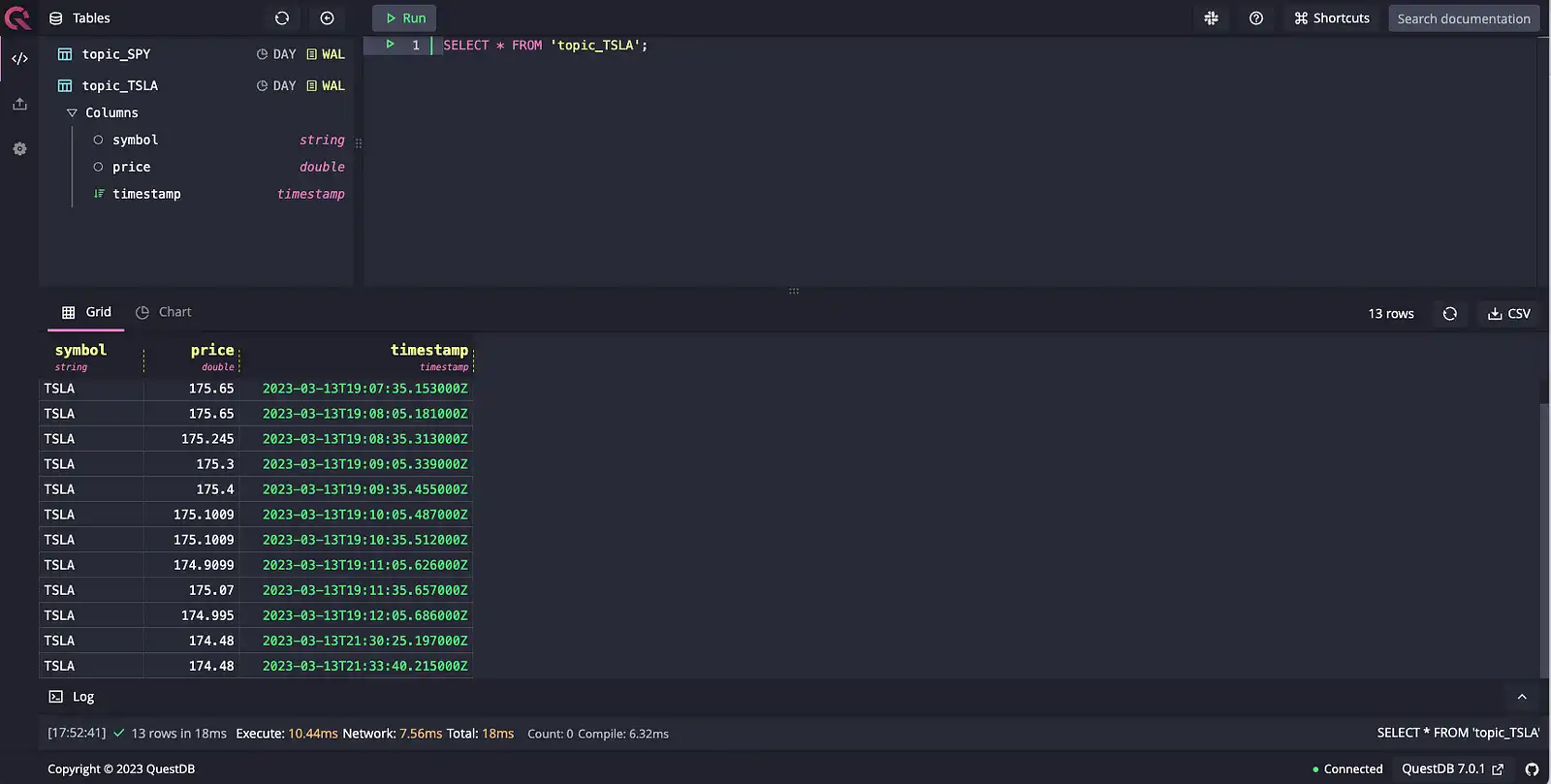
We can also look at SPY data from topic_SPY:
SELECT * FROM 'topic_SPY'
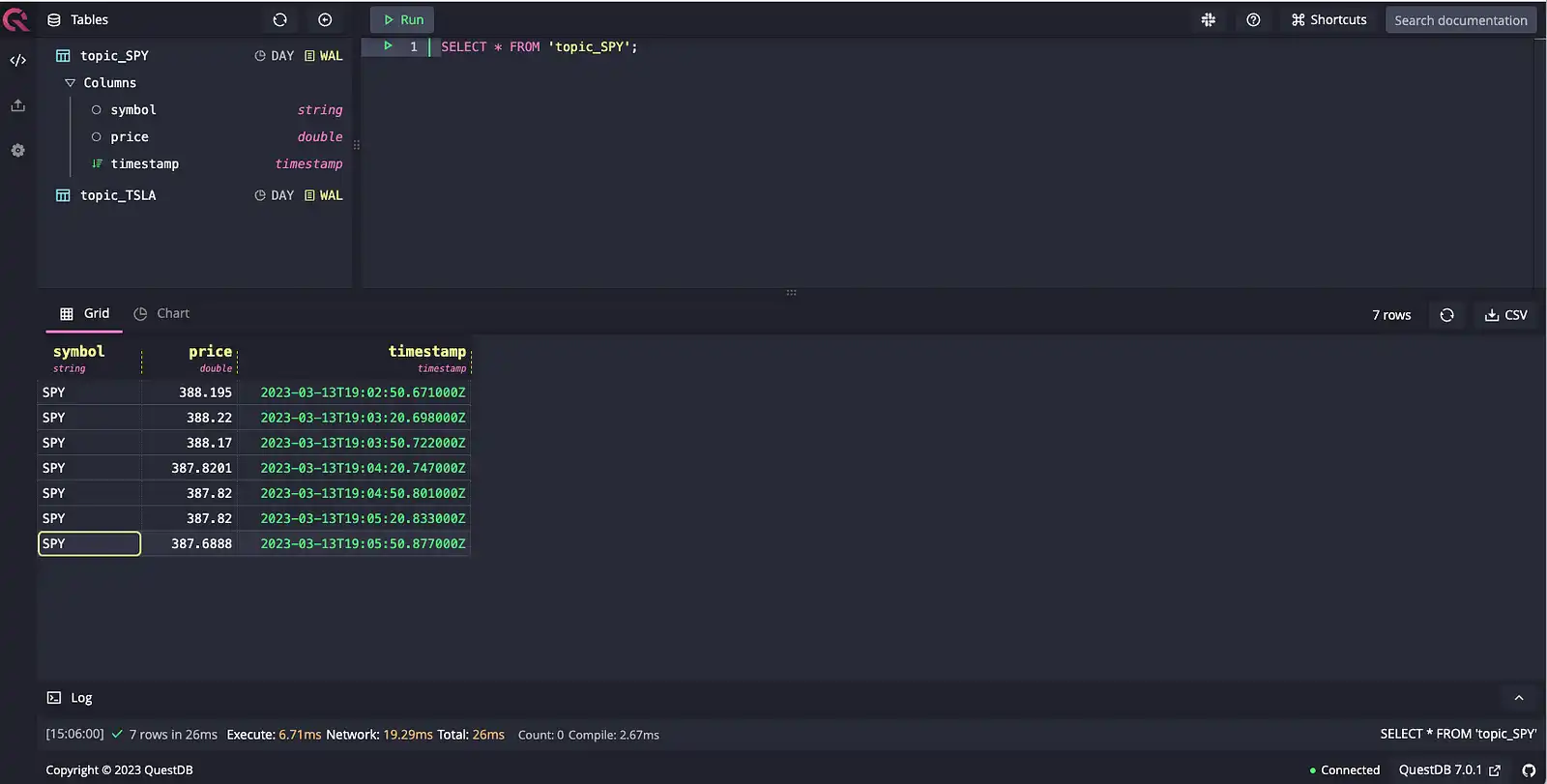
With the data now in QuestDB, we can query for aggregate information by getting the average price over 2m window:
SELECT avg(price), timestamp FROM topic_SPY SAMPLE BY 2m;
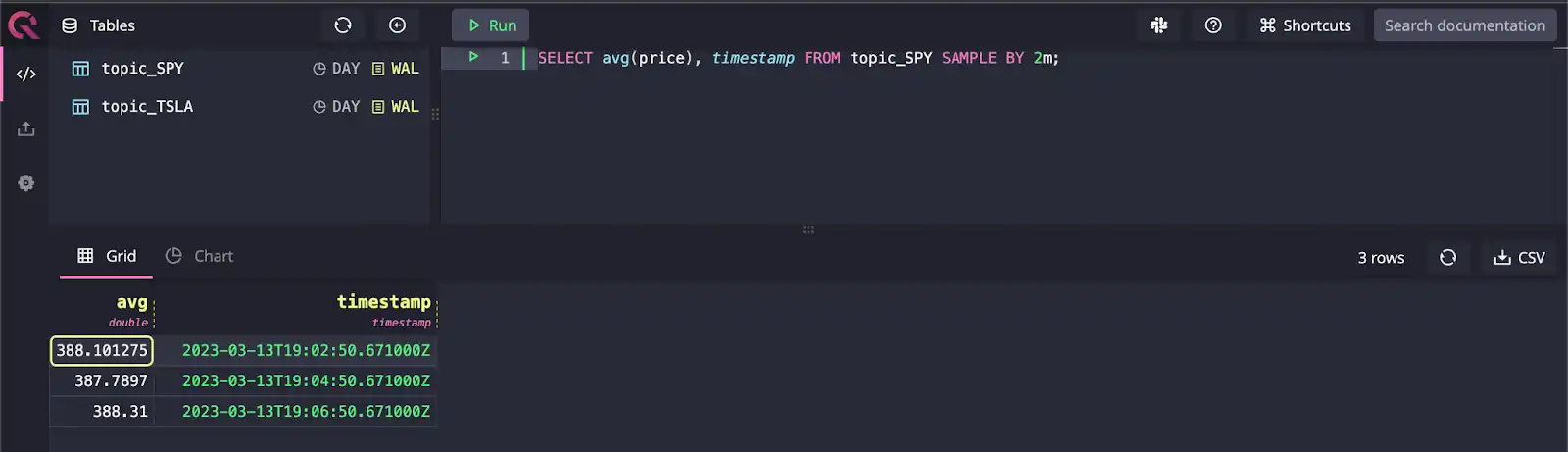
Conclusion
Kafka is a trusted component of data pipelines handling large amounts of time series data such as financial data. Kafka can be used to stream mission-critical source data to multiple destinations, including time series databases suited for real-time analytics.
In this article, we created a reference implementation of how to poll real-time market data and use Kafka to stream that to QuestDB via Kafka Connect. For more information on the QuestDB Kafka connector, check out the overview page on the QuestDB website. It lists more information on the configuration details and FAQs on setting it up. The GitHub repo for the connector also has sample projects including a Node.js and a Java example for those looking to extend this reference architecture.
Additional resources
Apache Kafka Connector for QuestDB
Realtime crypto tracker with QuestDB Kafka Connector
Real-time analytics and anomaly detection with Apache Kafka, Apache Flink, Grafana & QuestDB