Solving duplicate data with performant deduplication

It's a mad, mad, mad, mad world...
Your plane lands and the cabin crew announces: "You may now use your electronic devices.” You switch your phone on and a few seconds later a text message welcomes you to the network and informs you of the (outrageous) service rates. Minutes later, you get exactly the same message. Double-y outrageous! What just happened? Well, you've been "at-least-once'd”.
The same thing can happen tens of thousands of times when you ingest time series, analytic or event data. Duplicate data is a pain. It wastes compute and storage resources, slows down ingestion times and distorts the accuracy of your data sets. Wouldn't it be better if “at-least-once” was “exactly once?”
In this article, we'll look at data deduplication and compare the performance impact of data deduplication across Timescale, Clickhouse and QuestDB.
Performance details for the curious mind
Before we get into more details about deduplication, including the approach we
took with QuestDB, let's start with the data. Of course, we expect deduplication
to degrade performance somewhat. How much will depend on the number of
UPSERT Keys and on the number of conflicts. But how much?
To demonstrate, we'll run an experiment.
Our goal is to evaluate the performance impact when ingesting a dataset twice.
Our methodology is:
- Ingest a dataset once
- Re-ingest the same dataset again
This is a pretty ugly scenario, as every row means a conflict. To make things even more interesting, we will ingest the datasets in parallel. This will force the databases to not only deal with duplicates, but also with out-of-order data. The processing of out-of-order data — while valuable for customers ingesting large data volumes — is more challenging to process.
To make sure performance degradation is within industry expectations, we will run the experiment against two very popular and excellent databases that we usually meet in real-time or time-series use cases: Clickhouse and Timescale.
Disclaimer: This experiment is not intended to be a rigorous benchmark. The goal is to check relative performance of QuestDB when handling duplicate data. While we are quite knowledgeable of QuestDB, we're average at operating Timescale and Clickhouse. As such, the experiment applies default, out-of-the-box configurations for each database engine, with no alterations. Fine-tuning would certainly generate different results. We welcome you to perform your own tests and share the benchmarks!
This test will run on an AWS EC2 instance: m6a.4xlarge, 16 CPUs, 64 Gigs of RAM, GP3 EBS volume. We will ingest 15 uncompressed CSV files, each containing 12,614,400 rows, for a total of 189,216,000 rows representing 12 years of hourly data.
The data represents synthetic e-commerce statistics, with one hourly entry per country (ES, DE, FR, IT, and UK) and category (WOMEN, MEN, KIDS, HOME, KITCHEN). It will be ingested into five tables (one per country) with this structure:
CREATE TABLE 'ecommerce_sample_test_DE' (ts TIMESTAMP,country SYMBOL capacity 256 CACHE,category SYMBOL capacity 256 CACHE,visits LONG,unique_visitors LONG,avg_unit_price DOUBLE,sales DOUBLE) timestamp (ts) PARTITION BY DAY WAL DEDUP UPSERT KEYS(ts,country,category);
The total size of the raw CSVs is about 17GB, and we are reading from a RAM disk to minimize the impact of reading the files. We will thus be reading/parsing/ingesting from up to 8 files in parallel. The experiment's scripts are written in Python, so we could optimize ingestion by reducing CSV parsing time using a different programming language. But remember: this is not a rigorous benchmark.
- Our data set: https://mega.nz/folder/A1BjnSYQ#NQe5qhYLVBqiRwhWRmcVtg
- Our scripts: https://github.com/javier/deduplication-stats-questdb
How did it turn out?
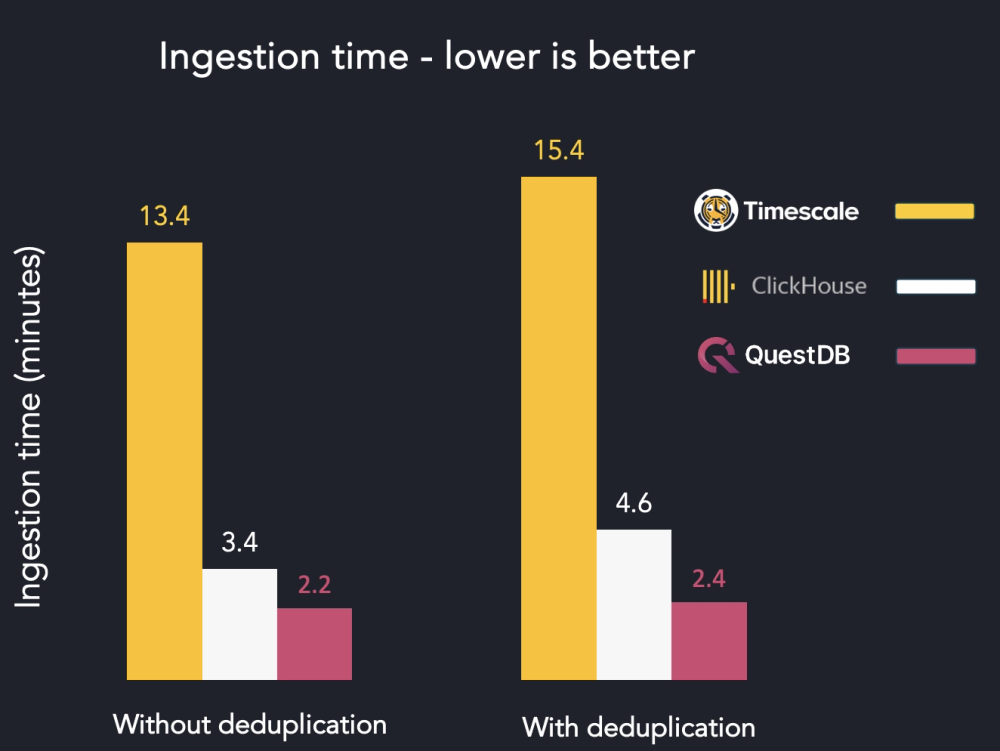
As far as raw numbers, the table demonstrates:
| Storage engine | Ingest without dedupe | Ingest with dedupe | Latency increase (lower is better) |
|---|---|---|---|
| Timescale | 13m23s | 15m23s | +15.5% |
| Clickhouse | 3m24s | 4m36 | +17.9% |
| QuestDB | 2m12s | 2m23s | +8.3% |
To get these results, the ingestion script was run multiple times for every database. The execution numbers below are those of the best runs. In any case, variability was quite low when re-running several times. Looks good! But the raw numbers don't tell the full story.
Timescale deduplication performance
Timescale took 13 minutes and 23 seconds to ingest the whole dataset for the
first time. When re-ingesting for deduplication over the same tables with
ON CONFLICT … DO UPDATE, the process took 15 minutes and 28 seconds.
As was to be expected due to the underlying PostgreSQL engine, uniqueness is guaranteed at every point. This would be suitable for strong exactly-once semantics. But performance-wise, re-playing the events took 15.5% longer than the initial ingestion. And this was significantly slower than analytics optimized storage engines, Clickhouse and QuestDB.
Clickhouse deduplication performance
Clickhouse took 3 minutes and 54 seconds to ingest the whole dataset for the
first time. When re-ingesting over the same tables using the
ReplacingMergeTree engine and defining Primary Keys, the process took 4
minutes and 36 seconds. That's quite awesome.
However, when we ran a SELECT count(*) FROM ecommerce_sample_test_ES, the
number of rows was 60,543,200 which is exactly double the number of rows within
the dataset. The explanation is that Clickhouse applies deduplication in the
background after a few minutes have elapsed. Fast, but during that time period
we have inaccurate data.
If we want to generate the real number of unique rows, we can add the FINAL
keyword to the query. But in that case the query slows down. For example, a
simple count went from 0.002 seconds to 0.337 seconds. Doing so is also not
recommended by Clickhouse themselves. This makes it tricky to get to a strong
exactly-one semantic. Performance-wise, re-playing the events took 17.9% longer
than the initial ingestion.
QuestDB deduplication performance
QuestDB took 2 minutes and 12 seconds to ingest the whole dataset for the first
time. When re-ingesting over the same tables using DEDUP … USERT KEYS, the
process took 2 minutes and 23 seconds. No duplicates were written, so this would
be suitable for strong exactly-once semantics. Performance-wise, re-playing the
events took 8.3% longer than the initial ingestion.
Overall, performance looks good. But let's take a step back and explain what's happening within QuestDB. Briefly, how does it work?
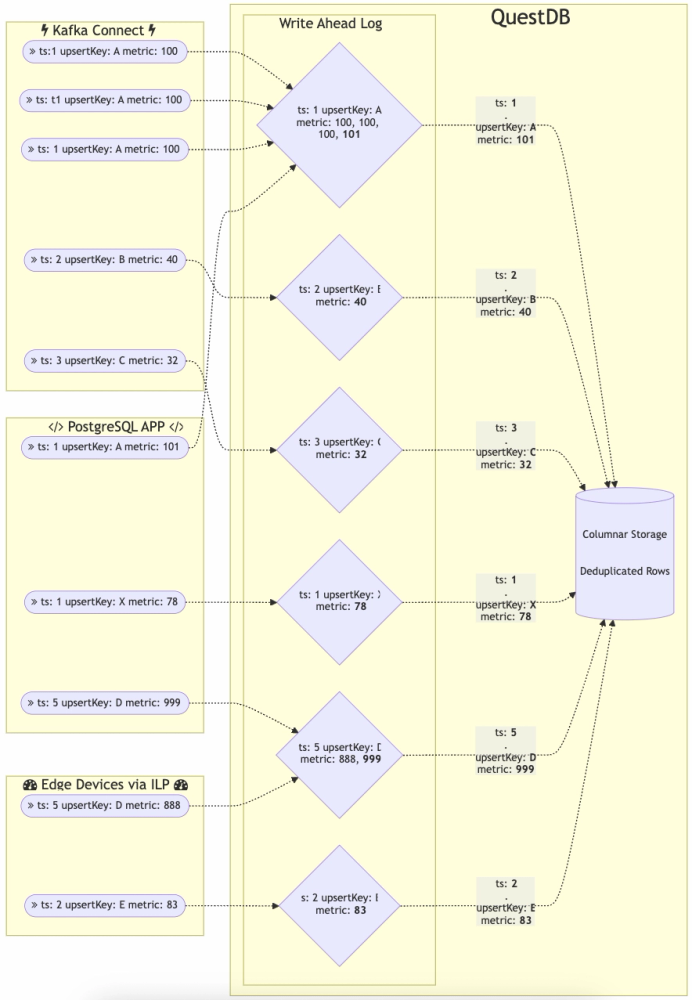
The process for QuestDB deduplication is:
- Sort the commit data by designated timestamp before
INSERTinto the table. This is the same as a normalINSERT - If deduplication uses extra
UPSERT Keys, sort the data by an additional key against the matching timestamp - Eliminate the duplicates in uncommitted data
- Perform a 2-way sorted merge of the uncommitted data into existing
partitions. This is also the same as a normal
INSERT - If a particular timestamp value exists in both new and existing data, compare the additional key columns. If it is a full match, take the new row instead of the old one
The extra steps are 2, 3, and 5. To perform the comparison, these steps require
more CPU processing and disk IO to load the values from the additional columns.
If there are no additional UPSERT Keys or if all the timestamps are unique,
then these additional steps add virtually no load.
Towards exactly once
To solve data deduplication, top databases typically implement one of the following strategies:
Unique indexes
Traditional databases like PostgreSQL, PostgreSQL-based systems like Timescale and most relational databases require that you create Unique indexes. Unique indexes thus provide two options:
- Throw an error when a duplicate is encountered
- Use an
UPSERTstrategy
With UPSERT, non-duplicate rows are inserted as usual. But rows where the
unique keys already exist will be considered updates that store the most recent
values for the non-unique columns. The table still doesn't hold duplicates, but
it does allow for corrections or updates.
Since indexes are involved, deduplication has an impact on performance. For the typical use case of a relational database, when the read/write ratio is heavily biased for reads, this impact might be negligible. But with write-heavy systems such as those seen within analytics, performance can noticeably degrade.
Compacted tables
Analytical databases such as Clickhouse prioritize ingestion performance. As a result, they will accept duplicate values. At a later point in time they will then compact the tables in the background, keeping only the latest version of a row. This means that for an indeterminate time, duplicates will be present on your tables. This is probably not ideal for data accuracy and efficiency.
To resolve this, developers can add the FINAL keyword to their queries as a
workaround. The FINAL keyword will prevent duplicates from appearing within
query results. But that makes queries slower. Clickhouse recommends that people
avoid this method. That means that the recommended, performant path risks
duplicates making it into your data set and thus into your queries and
dashboards.
Out-of-database deduplication
The third strategy is to move deduplication handling outside of the database itself. In this case, the deduplication logic is applied right before ingestion, as a connector running on Kafka Connect, Apache Flink, Apache Spark, or another similar stream processing component. This solution can be flimsy. Data ingested outside of the connector or outside a particular time-range might result in duplicates. Until recently, this was the only approach available in QuestDB.
Adding native data deduplication to QuestDB
While delegating deduplication to an external component was convenient for the QuestDB team, it was not ideal for customers. Customers had to manage an extra component so that all ingestion occurred within the deduplication pipeline. In many cases, external deduplication was only best-effort and didn't hit our high quality standards.
To address this, the team implemented native data deduplication with four goals in mind:
- Guaranteed with exactly-once-semantics
- Works as
UPSERT. Must load then discard exact duplicates, and update the metric columns when a new version of a record appears; make re-ingestion idempotent - Impact on performance must be negligible, so deduplication can be always-on
- Simple to activate/deactivate and transparent for developers and tools that select data
After a few months of hard work, the DEDUP keyword was released as part of
QuestDB 7.3. Now a
developer can activate/deactivate deduplication either as part of a
CREATE TABLE statement, or any time via ALTER TABLE.
QuestDB is a time-series database. Thus
deduplication must include the designated timestamp, plus any number of columns
to use as UPSERT Keys. A table with deduplication enabled is guaranteed to
store only one row for each unique combination of designated timestamp +
UPSERT Keys. will then silently update the rest of the columns if a new
version of the row is received.
Deduplication happens at ingestion time, which means you will never see any duplicates when selecting rows from a table. This gives you a strong exactly-once guarantee. The best part is that QuestDB will do all of that with very low impact on ingestion performance.
Conclusion, only a mad world
If you need ingestion idempotence and exactly-once semantics for your database, QuestDB gives you deduplication with very low impact on performance. As a result, you can enjoy strong performance with deduplication always enabled. When compared to other excellent database engines, QuestDB strikes a very good balance between performance, strong guarantees and usability.
To learn more about deduplication and see how you can apply it in QuestDB, checkout our data deduplication documentation.