Data Integration for Time-Series: ETL, ELT, and CDC
As digital transformation reaches more industries, the number of data points generated is growing exponentially. As such, data integration strategies to collect such large volumes of data from different sources in varying formats and structures are now a primary concern for data engineering teams. Traditional approaches to data integration, which have largely focused on curating highly structured data into data warehouses, struggle to deal with the volume and heterogeneity of new data sets.
Time-series data present an additional layer of complexity. By nature, the value of each time series data point diminishes over time as the granularity of the data loses relevance as it gets stale. So it is crucial for teams to carefully plan data integration strategies into time-series databases (TSDBs) to ensure that the analysis reflects the trends and situation in near real-time.
In this article, we'll examine some of the most popular data integration solutions for time-series databases:
- ETL (Extract, Transform, Load)
- ELT (Extract, Load, Transform)
- Data Streaming with CDC (Change Data Capture)
Given the need for real-time insights for time series data, many modern event-driven architectures now implement data streaming with CDC. To illustrate how it works in practice, we will walk through a reference implementation with QuestDB to show that CDC can flexibly handle the needs of a time series data source.
Extract, Transform, Load (ETL)
ETL is a traditional and popular data integration strategy that involves first transforming the data into a predetermined structure, before loading the data into the target system (typically a data warehouse).
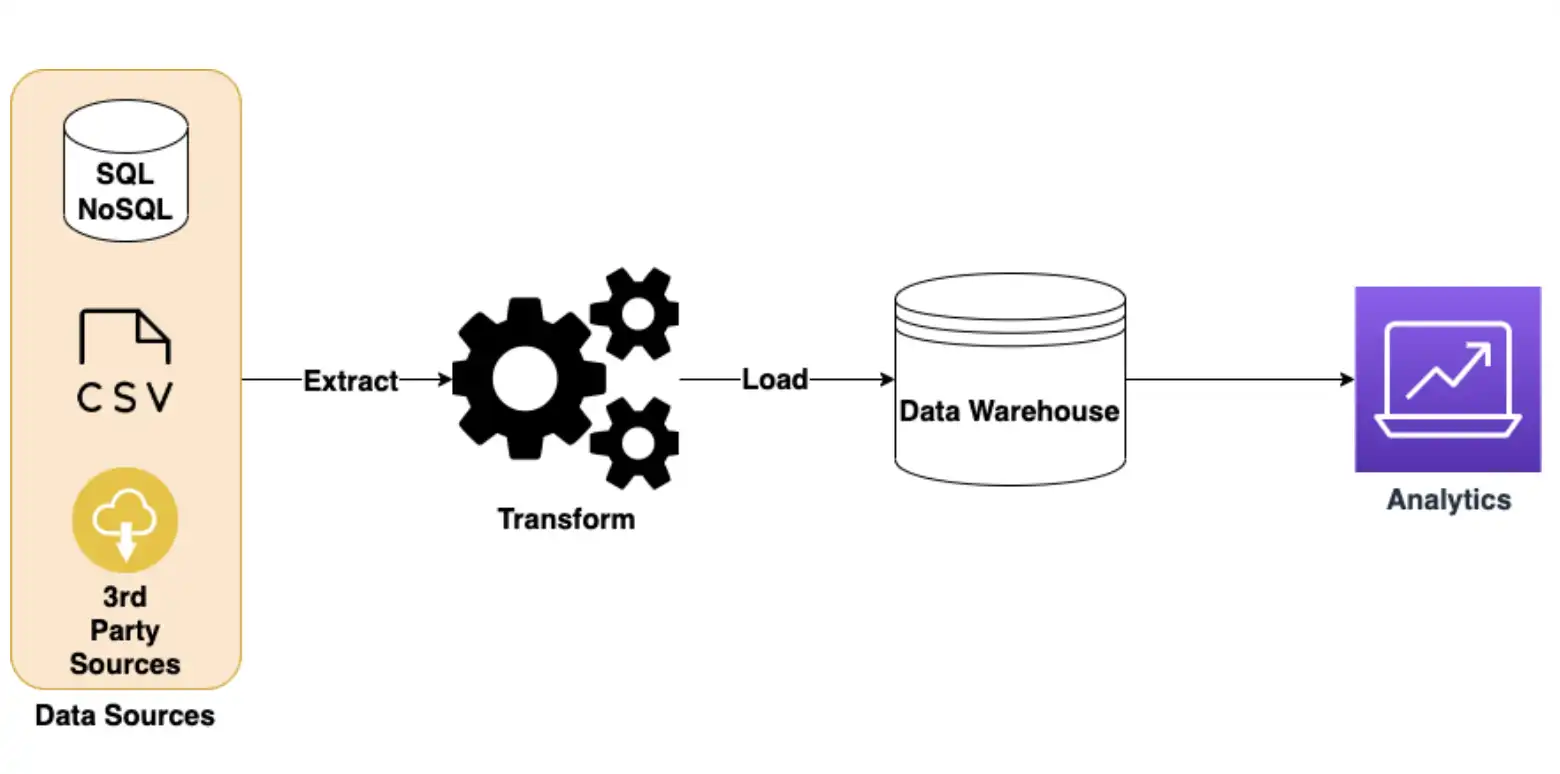
One of the main advantages of ETL is that it provides the highest degree of customization. Since the data is first extracted to a staging area where it is transformed into a clean, standardized format, ETL systems can handle a wide range of formats and structures. Also, once the data is loaded into the data warehouse, data science teams can run efficient queries and analyses. Finally, given the maturity of the ETL ecosystem, there is a plethora of enterprise-grade tools to choose from.
On the other hand, ETL is both time- and resource-intensive to maintain. The logic for sanitizing and transforming the data can be complex and computationally expensive. This is why most ETL systems are typically batch-oriented, only loading the data into the warehouse periodically. As the volume of data and the sources of data grows, this can become a bottleneck.
Given these qualities, ETL systems are most used for datasets that require complex transformation logic before analysis. It can also work well for datasets that do not require real-time insights and can be stored for long-term trend analysis.
Extract, Load, Transform (ELT)
ELT, as the name suggests, loads the data first into the target system (typically a data lake) and performs the transformation within the system itself. Given the responsibilities of the target system to handle both fast loads and transformations, ELT pipelines usually leverage modern, cloud-based data lakes that can deal with the processing requirements
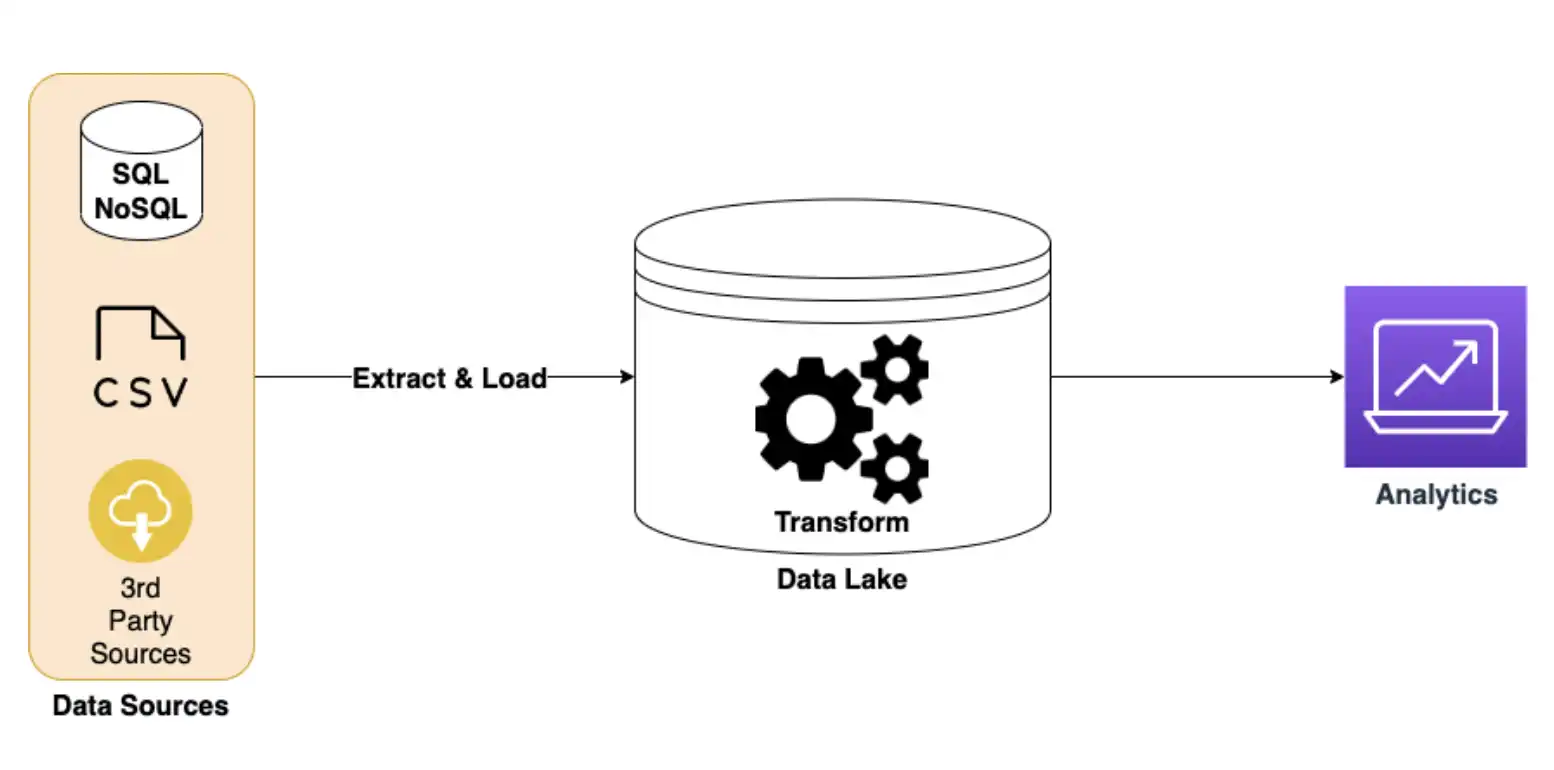
Compared to ETL pipelines, ELT systems can provide more real-time analysis of the data since raw data is ingested and transformed on the fly. Most cloud-based data lakes provide SDKs or endpoints to efficiently ingest data in micro-batches and provide almost limitless scalability. However, ELT is not without downsides. Since transformation is done by the target system, such operations are limited by the capabilities supported by the data lakes. If you need a more complex transformation logic, additional steps may be needed to re-extract data and store it in a more friendly format.
For most use cases, ELT is a more efficient data integration strategy than ETL. If your application can leverage cloud-based tools and does not require complex processing, ELT can be a great choice to handle large amounts of data in near real-time.
Change Data Capture (CDC)
For new projects, teams can plan to utilize TSDBs as one of the target systems in an ETL or ELT pipeline. However, for existing projects, either migrating to or adding a TSDB into the mix can be a challenge. For one, work may be required to either modify or use a new driver/SDK to stream data into the TSDB. Even if the same drivers are supported, data formats may also need to change to fully take advantage of TSDB capabilities. CDC tools can be useful to bridge this gap.
CDC is simple in principle: CDC tools such as Debezium continuously monitor changes in the source system and notify your data pipeline whenever there is a change. The application causing the change is often not even aware there is a CDC process listening on changes. This makes CDC a good fit for integrating new real-time data pipelines into existing architectures because it requires small or no changes in the existing applications. As such, CDC can be used in conjunction with either ETL or ELT pipelines. For example, the source system can be a SQL RDBMS (e.g., MySQL, PostgreSQL, etc) or NoSQL DB (e.g., MongoDB, Casandra) and one of the target systems can be a TSDB along with other data lakes or warehouses.
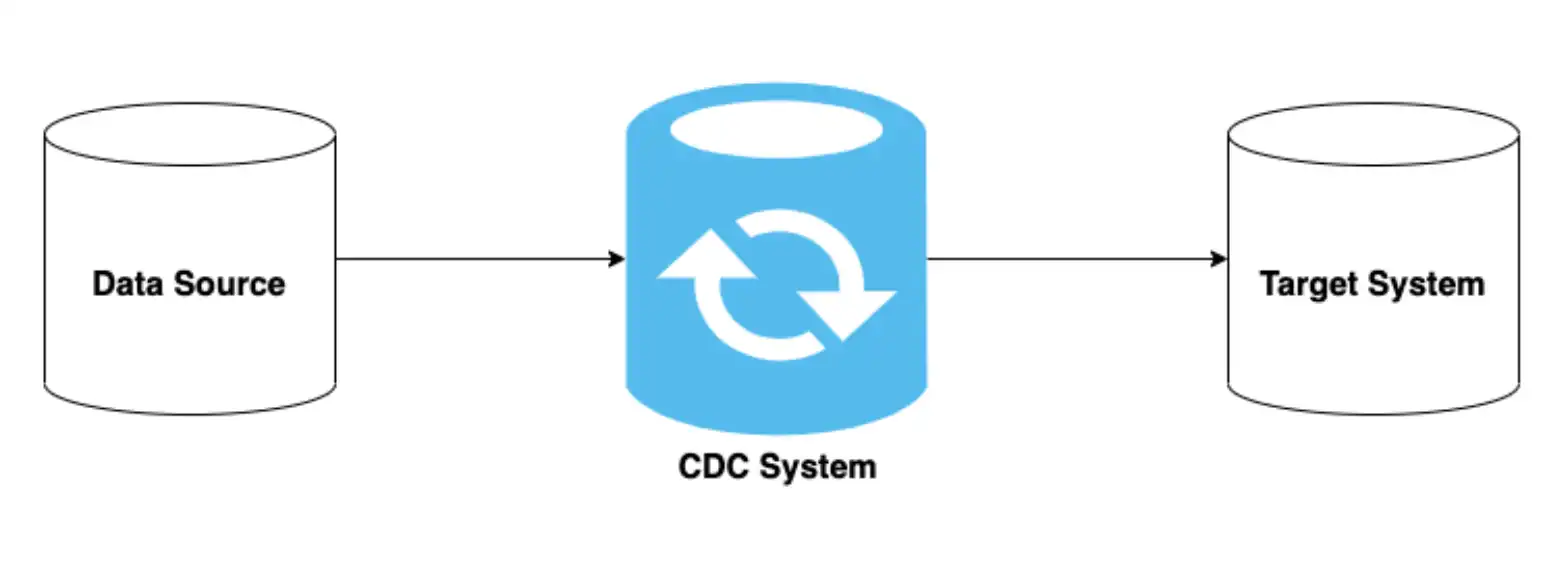
The main advantage of using CDC for data integration is that it provides real-time data replication. Unlike traditional ETL and ELT systems that work with batches, the changes to the source system are continuously streamed into one or more target systems. This can be useful to replicate either a subset or the entire data across multiple databases in near real-time. The target databases may even be in different geographical regions or serve different purposes (i.e., long-term storage vs. real-time analytics). For time series data where the changes in value over time are often most useful, CDC efficiently captures that delta for real-time insights.
Reference Implementation for CDC
To illustrate how CDC works more concretely, let's take the reference implementation I wrote about recently to stream stock prices into QuestDB.
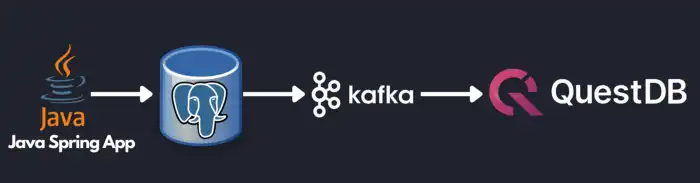
At a high level, a Java Spring App publishes stock price information into PostgreSQL. Debezium Connector then reads the changes from PostgreSQL and publishes them onto Kafka. On the other side, QuestDB's Kafka Connector reads from the Kafka topics and streams them onto QuestDB.
For a deeper dive, please refer to Change Data Capture with QuestDB and Debezium.
In this reference architecture, the Java Spring App is transforming and loading the data onto PostgreSQL before it's replicated to TSDB for further analysis. If a more ELT-like pipeline is desired, raw data from another provider could have been loaded directly onto PostgreSQL and transformed later in QuestDB as well.
The important thing to note with this architecture is that CDC can seamlessly integrate with existing systems. From the application standpoint, it can retain the transactional guarantees of PostgreSQL, while adding a new TSDB component down the pipeline.
Conclusion
Data integration plays an important role for organizations that use a TSDB to store and analyze time series data. In this article, we looked at some advantages and disadvantages of using ETL or ELT. We also examined how CDC can be used in conjunction with those pipelines to provide real-time replication into TSDBs.
Given the special qualities of time series data, using a TSDB to properly store and analyze them is important. If you are starting fresh, look to build an ELT pipeline to stream data into a TSDB. To integrate with an existing system, look at utilizing CDC tools to limit the disruption to the current architecture.