Time series data is everywhere. It's the fastest growing new data type. But where is it all coming from? And isn't all data essentially series data? When does data ever exist outside of time? This article investigates the source of all this new time bound data, and explains why more and more of it will keep coming.
Is it all time series?
The quick and clean answer is no, not all data is time series data. There are many data types and most do not relate to time. To demonstrate, we'll pick a common non-time-series data type: Relational data.
Relational data is organized into tables and linked to other data through common attributes. An example would be a database of dogs, their breed, and whether or not they are well-behaved. This data is relational, categorical and cross-sectional. It's a snapshot of a group of entities with no relationship to "when". In this case, these entities are dogs. Adorable! But not time series data.
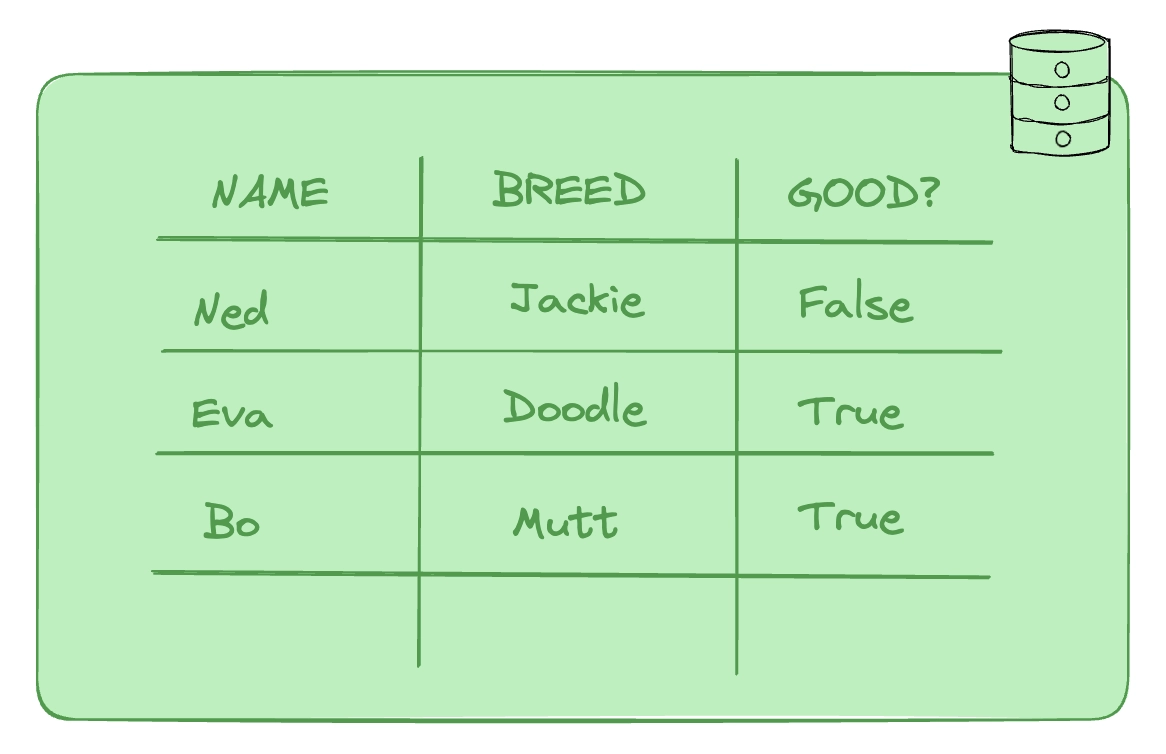
In this example, time is not relevant to the name, breed and behavioural tendencies of our dogs. It does not matter when the dog was added to the table, or when any of its values changed. The entities are held in a timeless vacuum.
By contrast, time series data is indexed in accordance with time, which is linear and synchronized. It consists of a sequence of data points, each associated with a timestamp. An example would be if our database of dogs included the dog's name, their breed, and their time in the local dog race:
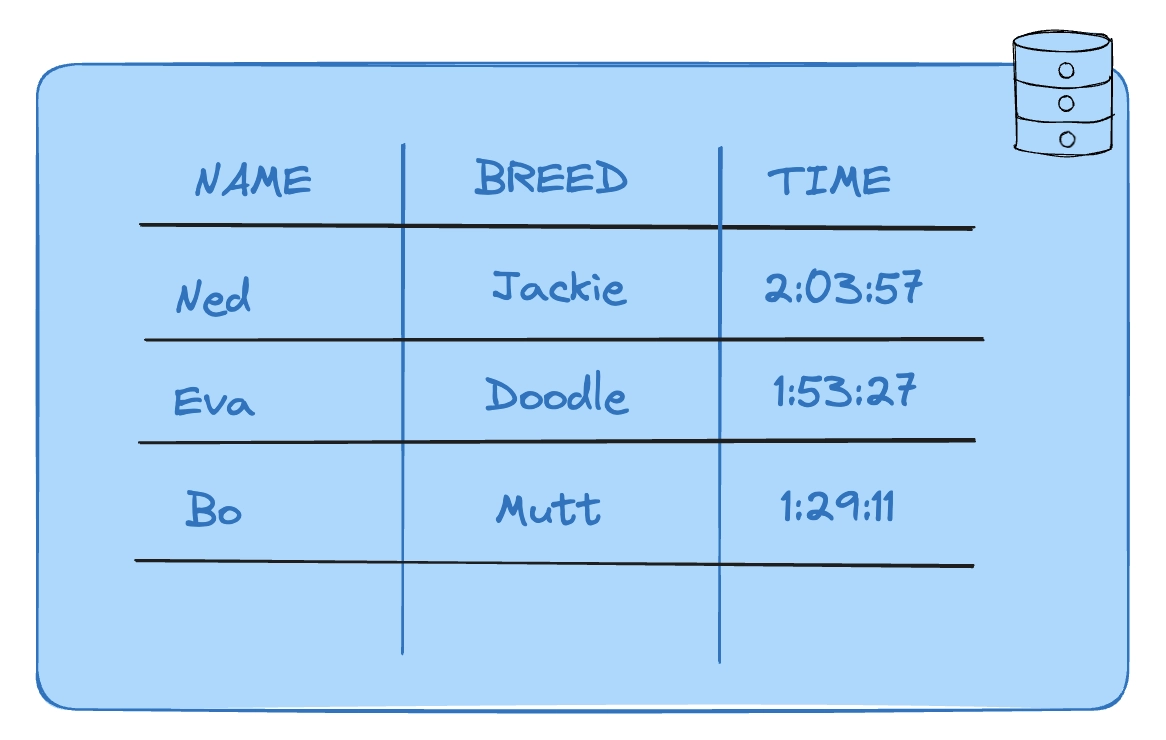
This table contains a timestamp and so now contains time series data. But this data is not the time series data that requires specific features or a specialized time series database. To require a specialized database, data must also match a specific set of demand and usage patterns. For now, it is simply time series data in a transactional, relational database.
In each action, a wake of time
When does it cross into that threshold? For this example, we will put our table of dogs into a practical light. Consider that a group of people input dog information into a database:
Simple! Now take one more practical step. How is the database accessed? A small team of people each login to a front-end data-entry application. For security purposes, an authentication server sits before the web application. A person authenticates, and then their session is kept alive for 24 hours:
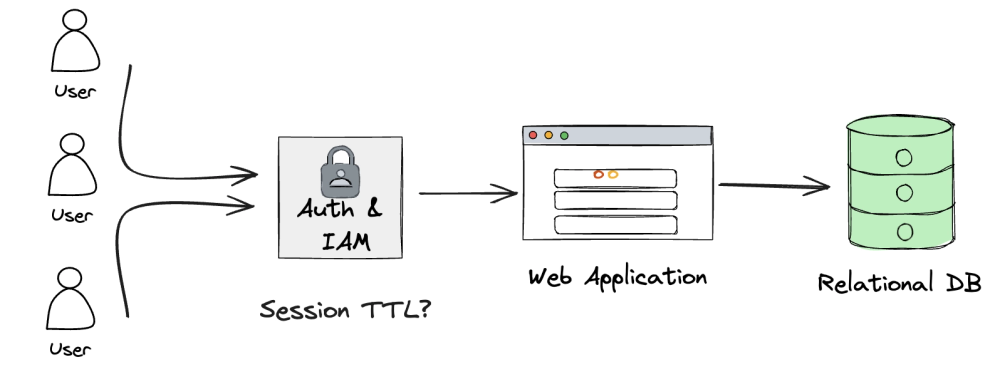
The authentication server needs to know exactly when a person logged in to determine when to invalidate their session. This requires a timestamp column. The security provider that handles login may receive tens of thousands of requests every second. Tracking each attempt in chronological order and revoking sessions with precision is an intense demand.
This is a key point. As above, the presence of time series data didn't mean much to our small-scale transactional, relational database. But now we've got a flow of time series data. And with it our requirements change.
And so deeper we go...
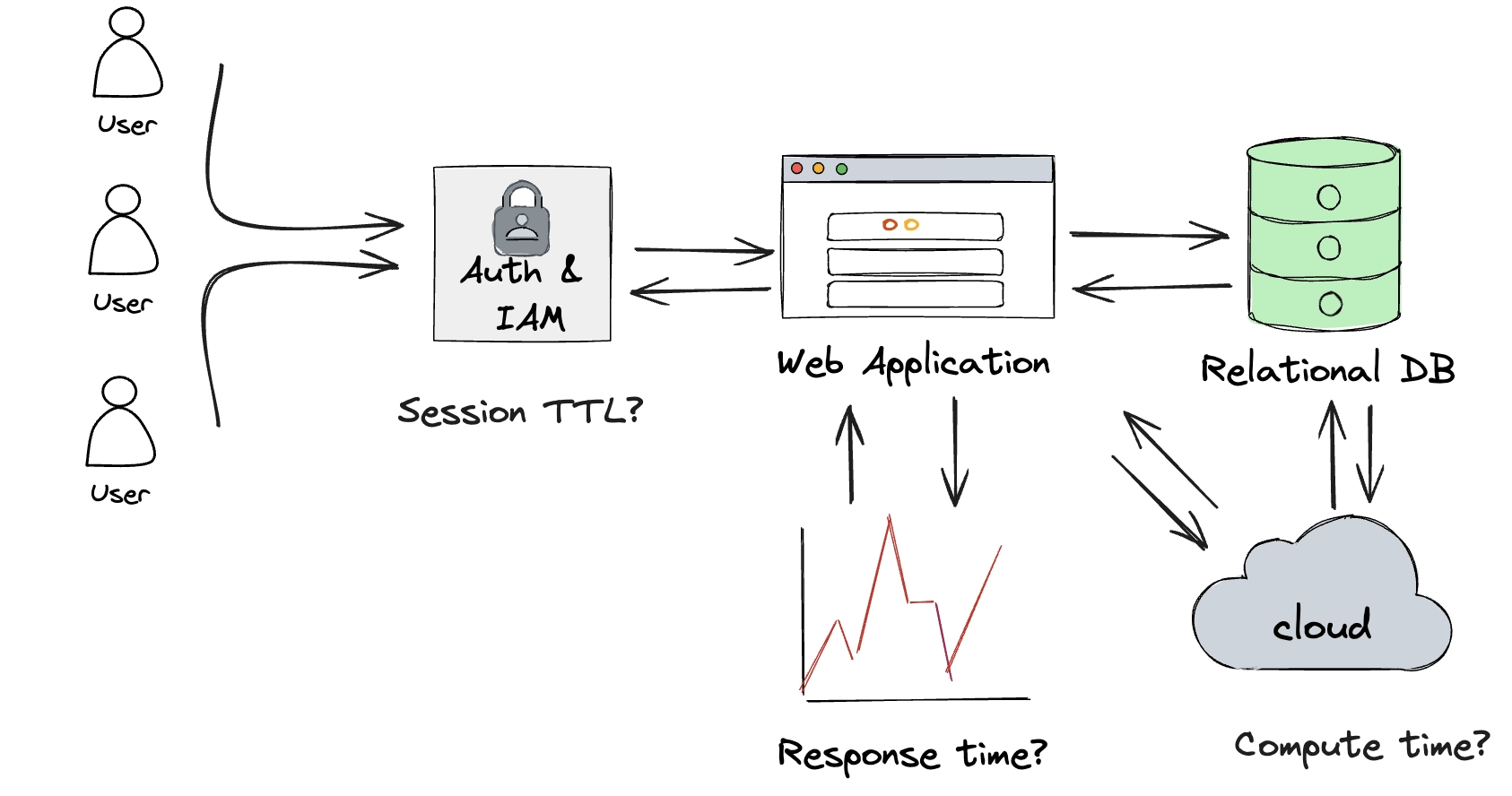
The database is hosted somewhere, perhaps in the Cloud. Cloud billing is based on compute time. The matching front-end application collects performance metrics. This is all novel time series data which contains essential insights from which business logic is written.
We can go deeper still and consider the entire chain. DNS queries hit DNS resolvers and hold a Time-To-Live value for DNS propagation. A Content Delivery Network before the front-end application gives precise detail on when something was accessed and how long static assets will need to live within the cache. Just one transactional update to the relational database generates a wake of essential time-bound data, for security and analysis.
Thus we retreat from our dive and head into the next section with the following crystallized takeaway: Not all data is time-series data, but time series data is generated via virtually any operation, including the creation, curation, and analysis of “non-time-series data” in “non-time-series databases”.
OLAP vs OLTP: Process types
This cascading relationship between transactions and analysis is best explained via a comparison of two common data processing techniques: Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP).
Online Transaction Processing (OLTP)
OLTP systems prioritize fast queries and data integrity in multi-access environments, where many people make updates at once. They are designed to handle a large number of short, atomic transactions and are optimized for transactional consistency. OTLP systems tend to perform operational tasks, such as creating, reading, updating, and deleting operations — the basic CRUD operations in a database.
Most OLTP systems use a relational database, where data is organized into normalized tables. Our dog database is OLTP. Another example would be an ecommerce system where customers purchase from an inventory. Many shoppers purchase many shoes from an accurate, single source of inventory. Each transaction is atomic, and the system handles a large number of concurrent transactions.
Online Analytical Processing (OLAP)
OLAP systems prioritize the fast computation of complex queries and often aggregate large amounts of data. They optimize for query and ingest speed over transactional consistency. They tend to be fast, powerful and flexible.
Our dog race database is not an example of an OLAP system. Even though it applies time series data, the race times are recorded and then entered into the database, making it more transactional and thus better suited for OLTP. In other words: the presence of time series data does not automatically mean it's an OLAP use case.
However, the example infrastructure above introduces time series elements where the performance optimizations found in OLAP systems become essential. On the way to one transactional operation, thousands of time-bound data points may be collected. Given how much time series data is created, ingest and analysis requires the mightier performance profile of a purpose-built analytical system.
Better with both
OLAP and OLTP are not at odds. They are complementary. Both OLTP and OLAP systems apply time series data. But due to their respective strengths, time series specialized databases excel at OLAP while relational databases with their transactional guarantees are a more natural fit for OLTP. At scale, you will see both systems work together.
Consider ecommerce once more. The ratio of browsers to buyers skews very heavily towards browsers. We all window shop from time to time, but a much smaller percentage of us complete a purchase. Every completed purchase requires a reliable way to update the inventory, which is a task for OLTP.
But every browser generates waves of data with their clicks, navigation and interactions: behavioural, statistical, and so on, which can be leveraged to increase the likelihood a person will complete a purchase. Time series data is created in abundance in the browsers case.
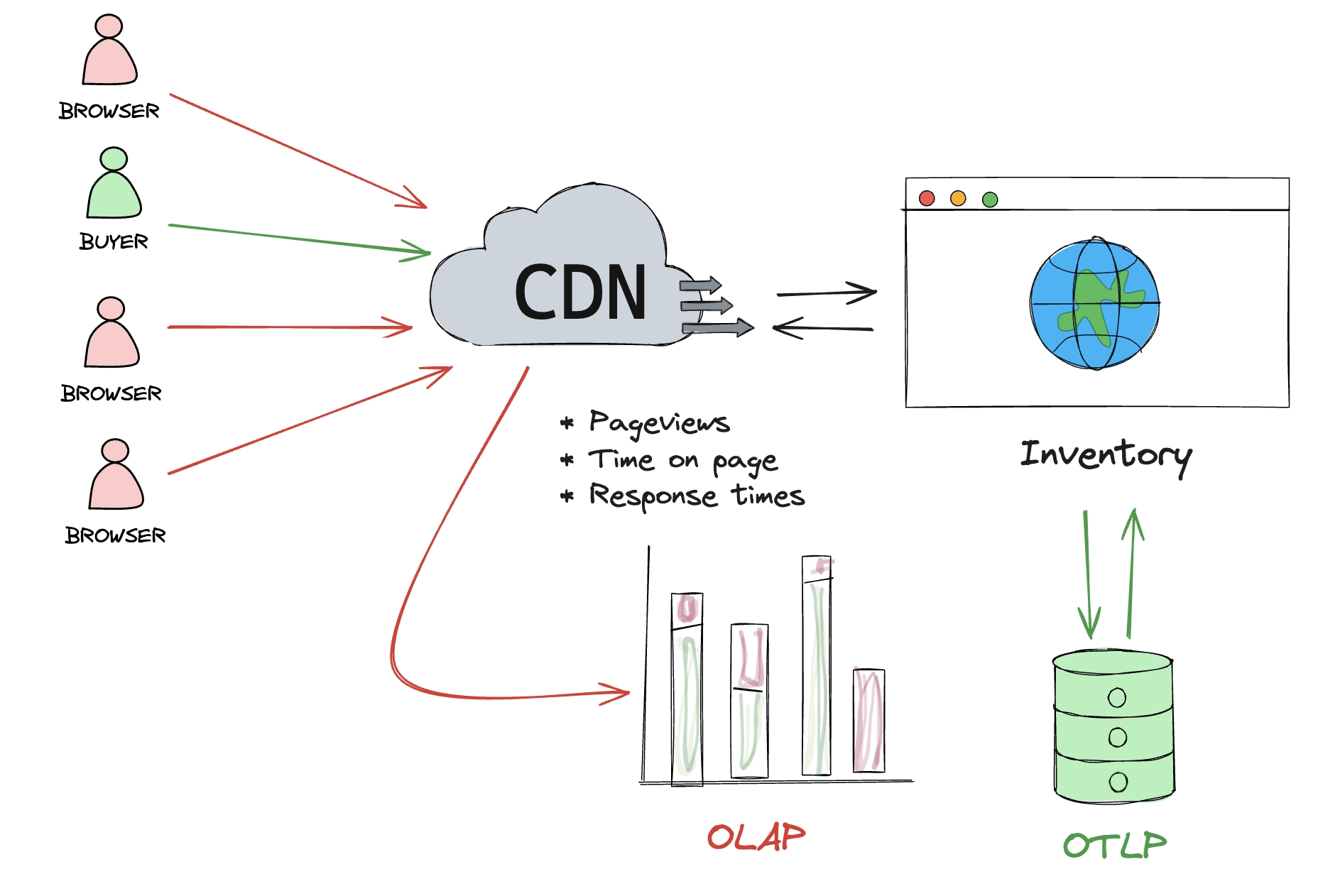
QuestDB is a specialized time series database. It excels at OLAP cases, and supplements OLTP cases. Consider a traditional relational database like PostgreSQL. In it we may store stock exchange data, such as the current price of a stock for tens of thousands of companies. With the sheer number of stocks and transactions between them, a time series database is needed beside it to record and analyze its history.
For example, whenever a stock price changes, an application will update a queue
which then updates a PostgreSQL table. The UPDATE/INSERT event is then sent to
something like Apache Kafka, which
reads the events, and then inserts them into a time series database.
The relational store, which provides the transactional guarantee, maintains the
stock prices and the present "state". The time series database then keeps the
history of changes, visualizing trends via a dashboard with computed averages
and a chart showing the volume of changes. The relational database may process
and hold 100,000 rows at any time, while the time series database may process
and hold 100,000 * seconds rows for present and future analysis.
Read our dive into SQL extensions for OLAP vs. time series databases
Conclusion
Not all data is time series data. But creating and accessing any online data generates time series data in waves. To respond to this demand, time series databases like QuestDB and others have arrived to handle the wake of data left in the exchange of high-integrity transactions and high-volume operations.
While time series data is found in both OLAP and OTLP systems, a specialized performance and feature profile is required to handle the significant historical and temporal data that is generated by even basic functions in modern day applications. Time series databases excel with these demands, while not being confined strictly to OLAP use cases.