Modern data architecture has largely shifted away from the ETL (Extract-Transform-Load) paradigm to ELT (Extract-Load-Transform) where raw data is first loaded into a data lake before transformations are applied (e.g., aggregations, joins) for further analysis. Traditional ETL pipelines were hard to maintain and relatively inflexible with changing business needs. As new cloud technologies promised cheaper storage and better scalability, data pipelines could move away from pre-built extractions and batch uploads to a more streaming architecture.
Change data capture (CDC) fits nicely into this paradigm shift where changes to data from one source can be streamed to other destinations. As the name implies, CDC tracks changes in data (usually a database) and provides plugins to act on those changes. For event-driven architectures, CDC is especially useful as a consistent data delivery mechanism between service boundaries (e.g., Outbox Pattern). In a complex microservice environment, CDC helps to simplify data delivery logic by offloading the burden to the CDC systems.
To illustrate, let's take a reference architecture to stream stock updates from PostgreSQL into QuestDB. A simple Java Spring App polls stock prices by ticker symbol and updates the current price to a PostgreSQL database. Then the updates are detected by Debezium (a popular CDC system) and fed to a Kafka topic. Finally, the Kafka Connect QuestDB connector listens to that topic and streams changes into QuestDB for analysis.
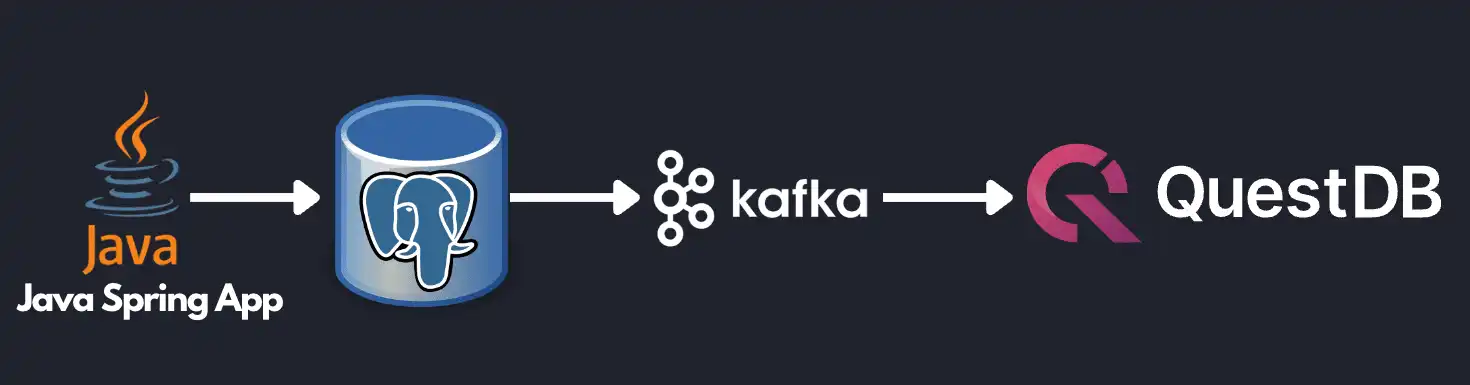
Structuring the data pipeline this way allows the application to be simple. The Java Spring App only needs to fetch the latest stock data and commit to PostgreSQL. Since PostgreSQL is an excellent OLTP (transactional) database, the app can rely on the ACID compliance to ensure that only the committed data will be seen by downstream services. The app developer does not need to worry about complicated retry logic or out-of-sync datasets. From the database standpoint, PostgreSQL can be optimized to do what it does best — transactional queries. Kafka can be leveraged to reliably feed data to other endpoints, and QuestDB can be used to store historical data to run analytical queries and visualization.
So without further ado, let's get to the example:
Prerequisites
- Git
- Docker Engine: 20.10+
Setup
To run the example locally, first clone the repo:
$ git clone https://github.com/questdb/kafka-questdb-connector.git
Then, navigate to the stocks sample to build and run the Docker compose files:
$ cd kafka-questdb-connector/kafka-questdb-connector-samples/stocks/
$ docker compose build
$ docker compose up
In Linux or older versions of Docker, the compose subcommand might not be
available. You can try to execute docker-compose instead of docker compose.
If docker-compose is unavailable in your distribution, you can
install it manually.
This will build the Dockerfile for the Java Spring App/Kafka Connector for QuestDB and pull down PostgreSQL (preconfigured with Debezium), Kafka/Zookeeper, QuestDB, and Grafana containers. Kafka and Kafka Connect take a bit to initialize. Wait for the logs to stop by inspecting the connect container.
Start the Debezium connector
At this point, the Java App is continuously updating the stock table in PostgreSQL, but the connections have not been setup. Create the Debezium connector (i.e., PostgreSQL → Debezium → Kafka) by executing the following:
curl -X POST -H "Content-Type: application/json" -d '{"name":"debezium_source","config":{"tasks.max":1,"database.hostname":"postgres","database.port":5432,"database.user":"postgres","database.password":"postgres","connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.dbname":"postgres","database.server.name":"dbserver1"}} ' localhost:8083/connectors
Start the QuestDB Kafka Connect sink
Finish the plumbing by creating the Kafka Connect side (i.e., Kafka → QuestDB sink):
curl -X POST -H "Content-Type: application/json" -d '{"name":"questdb-connect","config":{"topics":"dbserver1.public.stock","table":"stock", "connector.class":"io.questdb.kafka.QuestDBSinkConnector","tasks.max":"1","key.converter":"org.apache.kafka.connect.storage.StringConverter","value.converter":"org.apache.kafka.connect.json.JsonConverter","host":"questdb", "transforms":"unwrap", "transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState", "include.key": "false", "symbols": "symbol", "timestamp.field.name": "last_update"}}' localhost:8083/connectors
Final result
Now all the updates written to the PostgreSQL table will also be reflected in QuestDB. To validate, navigate to http://localhost:19000 and select from the stock table:
SELECT * FROM stock;
You can also run aggregations for a more complex analysis:
SELECT
timestamp,
symbol,
avg(price),
min(price),
max(price)
FROM stock
WHERE symbol = 'IBM'
SAMPLE BY 1m ALIGN TO CALENDAR;
Finally, you can interact with a Grafana dashboard for visualization at http://localhost:3000/d/stocks/stocks?orgId=1&refresh=5s&viewPanel=2.
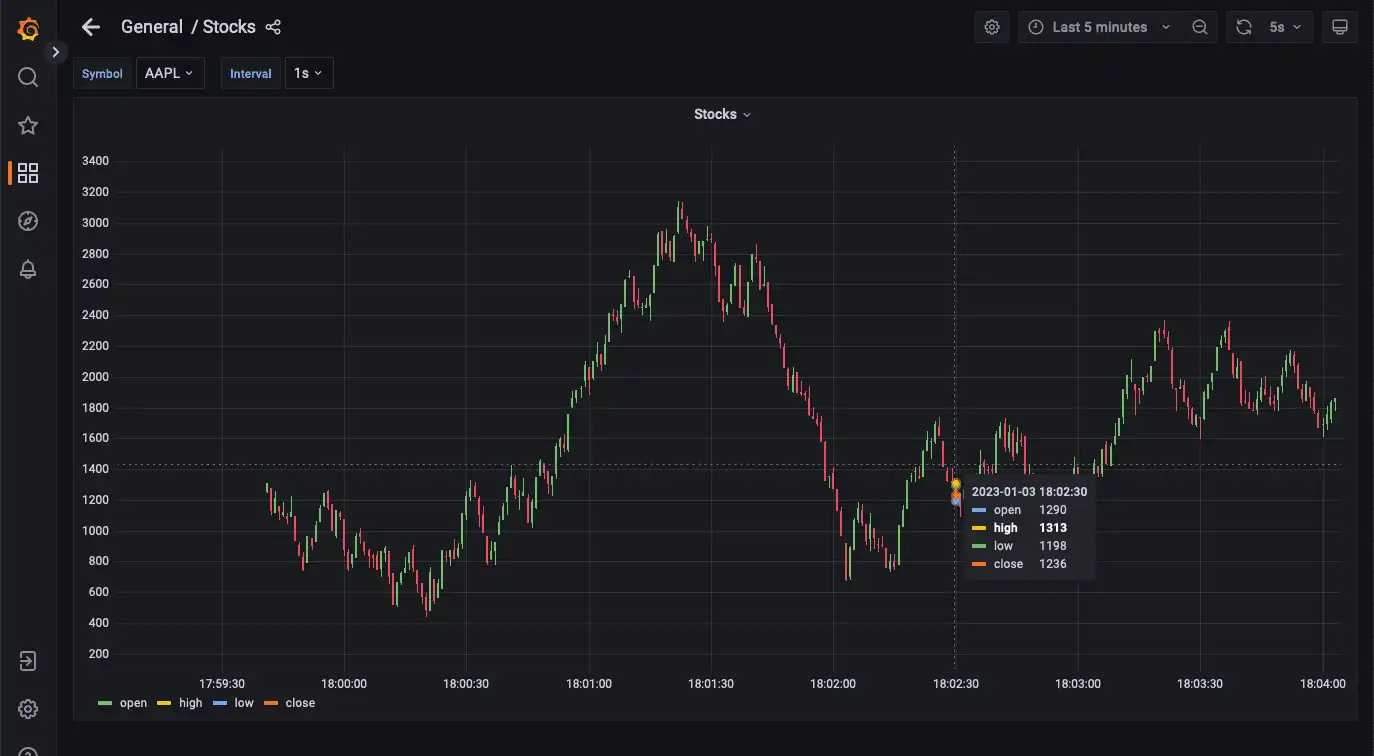
The visualization is a candle chart composed of changes captured by Debezium; each candle shows the opening, closing, high, and low price, in a given time interval. The time interval can be changed by selecting the top-left 'Interval' option:
Deep dive
Now that we have the sample application up and running, let's take a deeper dive into each component in the stocks example.
We will look at the following files:
├── kafka-questdb-connector/kafka-questdb-connector-samples/stocks/
│ ├── Dockerfile-App
| | -- The Dockerfile to package our Java App
| ├── Dockerfile-Connect
| | -- The Dockerfile to combine the Debezium container
| | -- image the with QuestDB Kafka connector
│ ├── src/main/resources/schema.sql
| | -- The SQL which creates the stock table in PostgreSQL
| | -- and populates it with initial data
│ ├── src/main/java/com/questdb/kafka/connector/samples/StocksApplication.java
| | -- The Java Spring App which updates the stock table in PostgreSQL
| | -- in regular intervals
...
Producer (Java App)
The producer is a simple Java Spring Boot App. It has two components:
-
The
schema.sqlfile. This file is used to create the stock table in PostgreSQL and populate it with initial data. It's picked up by the Spring Boot App and executed on startup.schema.sqlCREATE TABLE IF NOT EXISTS stock (
id serial primary key,
symbol varchar(10) unique,
price float8,
last_update timestamp
);
INSERT INTO stock (symbol, price, last_update) VALUES ('AAPL', 500.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('IBM', 50.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('MSFT', 100.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('GOOG', 1000.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('FB', 200.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('AMZN', 1000.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('TSLA', 500.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('NFLX', 500.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('TWTR', 50.0, now()) ON CONFLICT DO NOTHING;
INSERT INTO stock (symbol, price, last_update) VALUES ('SNAP', 10.0, now()) ON CONFLICT DO NOTHING;The
ON CONFLICT DO NOTHINGclause is used to avoid duplicate entries in the table when the App is restarted. -
Java code to update prices and timestamps with a random value. The updates are not perfectly random, the application uses a very simple algorithm to generate updates which very roughly resembles stock price movements. In a real-life scenario, the application would fetch the price from some external source.
The producer is packaged into a minimal Dockerfile,
Dockerfile-App,
and linked to PostgreSQL:
FROM maven:3.8-jdk-11-slim AS builder
COPY ./pom.xml /opt/stocks/pom.xml
COPY ./src ./opt/stocks/src
WORKDIR /opt/stocks
RUN mvn clean install -DskipTest
FROM azul/zulu-openjdk:11-latest
COPY --from=builder /opt/stocks/target/kafka-samples-stocks-*.jar /stocks.jar
CMD ["java", "-jar", "/stocks.jar"]
Kafka Connect, Debezium, and QuestDB Kafka Connector
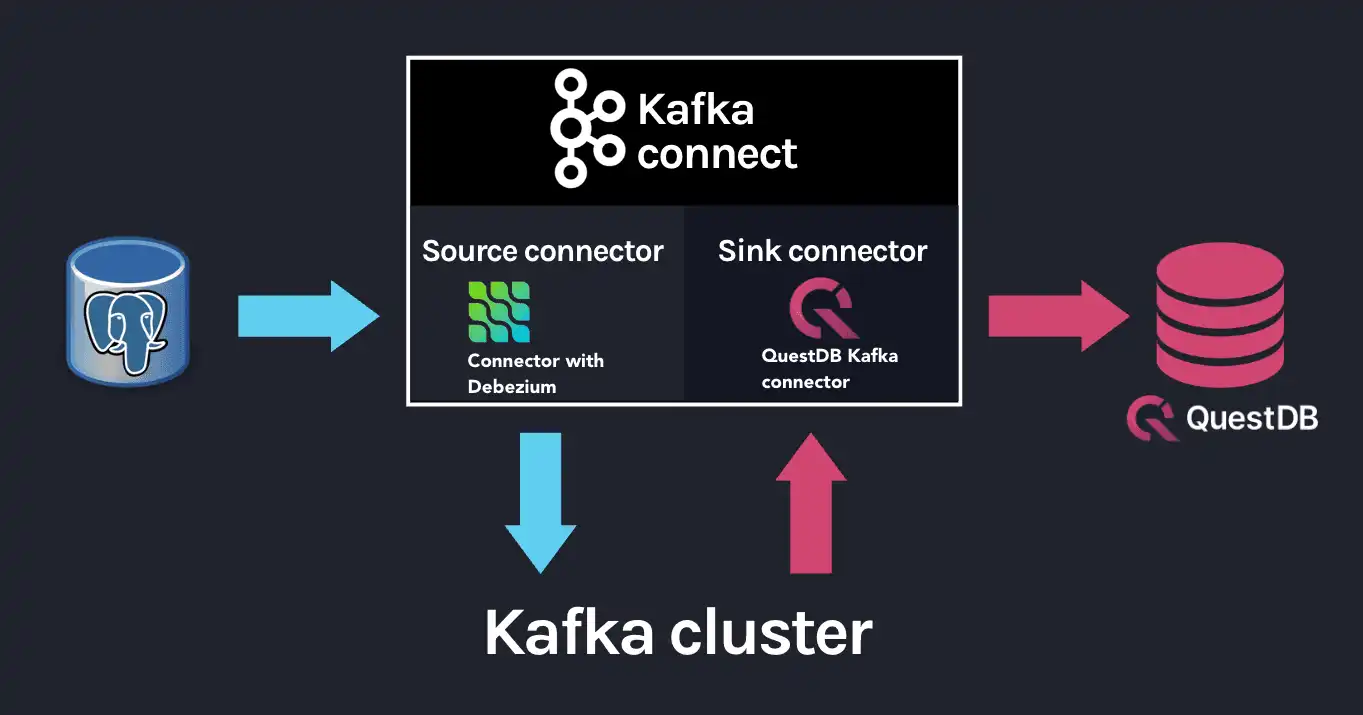
Before we dive into the Kafka Connect, Debezium, and the QuestDB Kafka connector configurations, let's take a look at their relation with each other.
Kafka Connect is a framework for building connectors to move data between Kafka and other systems. It supports 2 classes of connectors:
- Source connectors - read data from a source system and write it to Kafka
- Sink connectors - read data from Kafka and write it to a sink system
Debezium is a Source connector for Kafka Connect that can monitor and capture the row-level changes in the databases. What does it mean? Whenever a row is inserted, updated, or deleted in a database, Debezium will capture the change and write it as an event to Kafka.
On a technical level, Debezium is a Kafka Connect connector running inside the Kafka Connect framework. This is reflected in the Debezium container image, which packages the Kafka Connect with Debezium connectors pre-installed.
QuestDB Kafka connector is also a Kafka Connect connector. It's a Sink connector that reads data from Kafka and writes it to QuestDB. We add the QuestDB Kafka connector to the Debezium container image, and we get a Kafka Connect image that has both Debezium and QuestDB Kafka connector installed!
This is the Dockerfile we use to build the image:
FROM ubuntu:latest AS builder
WORKDIR /opt
RUN apt-get update && apt-get install -y curl wget unzip jq
RUN curl -s https://api.github.com/repos/questdb/kafka-questdb-connector/releases/latest | jq -r '.assets[]|select(.content_type == "application/zip")|.browser_download_url'|wget -qi -
RUN unzip kafka-questdb-connector-*-bin.zip
FROM debezium/connect:1.9.6.Final
COPY --from=builder /opt/kafka-questdb-connector/*.jar /kafka/connect/questdb-connector/
The Dockerfile downloads the latest release of the QuestDB Kafka connector, unzip it copies it to the Debezium container image. The resulting image has both Debezium and QuestDB Kafka connector installed:

The overall Kafka connector is completed with a Source connector and a Sink connector:
Debezium Connector
We already know that Debezium is a Kafka Connect connector that can monitor and capture the row-level changes in the databases. We also have a Docker image that has both Debezium and QuestDB Kafka connectors installed. However, at this point neither of the connectors is running. We need to configure and start them. This is done via CURL command that sends a POST request to the Kafka Connect REST API.
curl -X POST -H "Content-Type: application/json" -d '{"name":"debezium_source","config":{"tasks.max":1,"database.hostname":"postgres","database.port":5432,"database.user":"postgres","database.password":"postgres","connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.dbname":"postgres","database.server.name":"dbserver1"}} ' localhost:8083/connectors
The request body contains the configuration for the Debezium connector, let's break it down:
{
"name": "debezium_source",
"config": {
"tasks.max": 1,
"database.hostname": "postgres",
"database.port": 5432,
"database.user": "postgres",
"database.password": "postgres",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.dbname": "postgres",
"database.server.name": "dbserver1"
}
}
It listens to changes in the PostgreSQL database and publishes to Kafka with the
above configuration. The topic name defaults to
<server-name>.<schema>.<table>. In our example, it is
dbserver1.public.stock. Why? Because the database server name is dbserver1,
the schema is public and the only table we have is stock.
So after we send the request, Debezium will start listening to changes in the
stock table and publish them to the dbserver1.public.stock topic.
QuestDB Kafka Connector
At this point, we have a PostgreSQL table stock being populated with random
stock prices and a Kafka topic dbserver1.public.stock that contains the
changes. The next step is to configure the QuestDB Kafka connector to read from
the dbserver1.public.stock topic and write the data to QuestDB.
Let's take a deeper look at the configuration in the start the QuestDB Kafka Connect sink:
{
"name": "questdb-connect",
"config": {
"topics": "dbserver1.public.stock",
"table": "stock",
"connector.class": "io.questdb.kafka.QuestDBSinkConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"host": "questdb",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"include.key": "false",
"symbols": "symbol",
"timestamp.field.name": "last_update"
}
}
The important things to note here are:
-
tableandtopics: The QuestDB Kafka connector will create a QuestDB table with the namestockand write the data from thedbserver1.public.stocktopic to it. -
host: The QuestDB Kafka connector will connect to QuestDB running on thequestdbhost. This is the name of the QuestDB container. -
connector.class: The QuestDB Kafka connector class name. This tells Kafka Connect to use the QuestDB Kafka connector. -
value.converter: The Debezium connector produces the data in JSON format. This is why we need to configure the QuestDB connector to use the JSON converter to read the data:org.apache.kafka.connect.json.JsonConverter. -
symbols: Stock symbols are translated to QuestDB symbol type, used for string values with low cardinality (e.g., enums). -
timestamp.field.name: Since QuestDB has great support for timestamp and partitioning based on that, we can specify the designated timestamp column. -
transforms: unwrap field usesio.debezium.transforms.ExtractNewRecordStatetype to extract just the new data and not the metadata that Debezium emits. In other words, this is a filter to basically take thepayload.afterportion of the Debezium data on the Kafka topics. See its documentation for more details.
The ExtractNewRecordState transform is probably the least intuitive part of
the configuration. Let's have a closer look at it: In short, for every change in
the PostgreSQL table, the Debezium emits a JSON message to a Kafka topic such as
the following:
{
"schema": "This JSON key contains Debezium message schema. It's not very relevant for this sample. Omitted for brevity.",
"payload": {
"before": null,
"after": {
"id": 8,
"symbol": "NFLX",
"price": 1544.3357414199545,
"last_update": 1666172978269856
}
},
"source": {
"version": "1.9.6.Final",
"connector": "postgresql",
"name": "dbserver1",
"ts_ms": 1666172978272,
"snapshot": "false",
"db": "postgres",
"sequence": "[\"87397208\",\"87397208\"]",
"schema": "public",
"table": "stock",
"txId": 402087,
"lsn": 87397208,
"xmin": null
},
"op": "u",
"ts_ms": 1666172978637,
"transaction": null
}
Don't get scared if you feel overwhelmed by the sheer size of this message. Most
of the fields are metadata, and they are not relevant to this sample. See
Debezium documentation,
for more details. The important point is that we cannot push the whole JSON
message to QuestDB and we do not want all the metadata in QuestDB. We need to
extract the payload.after portion of the message and only then push it to
QuestDB. This is exactly what the ExtractNewRecordState transform does: It
transforms the big message into a smaller one that contains only the
payload.after portion of the message. Hence, it is as if the message looked
like this:
{
"id": 8,
"symbol": "NFLX",
"price": 1544.3357414199545,
"last_update": 1666172978269856
}
This is the message that we can push to QuestDB. The QuestDB Kafka connector will read this message and write it to the QuestDB table. The QuestDB Kafka connector will also create the QuestDB table if it does not exist. The QuestDB table will have the same schema as the JSON message - where each JSON field will be a column in the QuestDB table.
QuestDB and Grafana
Once the data is written to QuestDB tables, we can work with the time-series data easier. Since QuestDB is compatible with the PostgreSQL wire protocol, we can use the PostgreSQL data source on Grafana to visualize the data. The preconfigured dashboard is using the following query:
SELECT
$__time(timestamp),
min(price) as low,
max(price) as high,
first(price) as open,
last(price) as close
FROM
stock
WHERE
$__timeFilter(timestamp)
and symbol = '$Symbol'
SAMPLE BY $Interval ALIGN TO CALENDAR;
We have created a system that continuously tracks and stores the latest prices for multiple stocks in a PostgreSQL table. These prices are then fed as events to Kafka through Debezium, which captures every price change. The QuestDB Kafka connector reads these events from Kafka and stores each change as a new row in QuestDB, allowing us to retain a comprehensive history of stock prices. This history can then be analyzed and visualized using tools such as Grafana, as demonstrated by the candle chart.
Next steps
This sample project is a foundational reference architecture to stream data from a relational database into an optimized time series database. For existing projects that are using PostgreSQL, Debezium can be configured to start streaming data to QuestDB and take advantage of time series queries and partitioning. For databases that are also storing raw historical data, adopting Debezium may need some architectural changes. However, this is beneficial as it is an opportunity to improve performance and establish service boundaries between a transactional database and an analytical, time-series database.
This reference architecture can also be extended to configure Kafka Connect to also stream to other data warehouses for long-term storage. After inspecting the data, QuestDB can also be configured to downsample the data for longer term storage or even detach partitions to save space.
Give this sample application a try and join the Community Forum if you have any questions.