Spark is an analytics engine for large-scale data engineering. Despite its long history, it still has its well-deserved place in the big data landscape. QuestDB, on the other hand, is a time-series database with a very high data ingestion rate. This means that Spark desperately needs data, a lot of it!...and QuestDB has it, a match made in heaven.
Of course, there is pandas for data analytics! The key here is the expression large-scale. Unlike pandas, Spark is a distributed system and can scale really well.
What does this mean exactly?
Let's take a look at how data is processed in Spark.
For the purposes of this article, we only need to know that a Spark job consists of multiple tasks, and each task works on a single data partition. Tasks are executed parallel in stages, distributed on the cluster. Stages have a dependency on the previous ones; tasks from different stages cannot run in parallel.
The schematic diagram below depicts an example job:
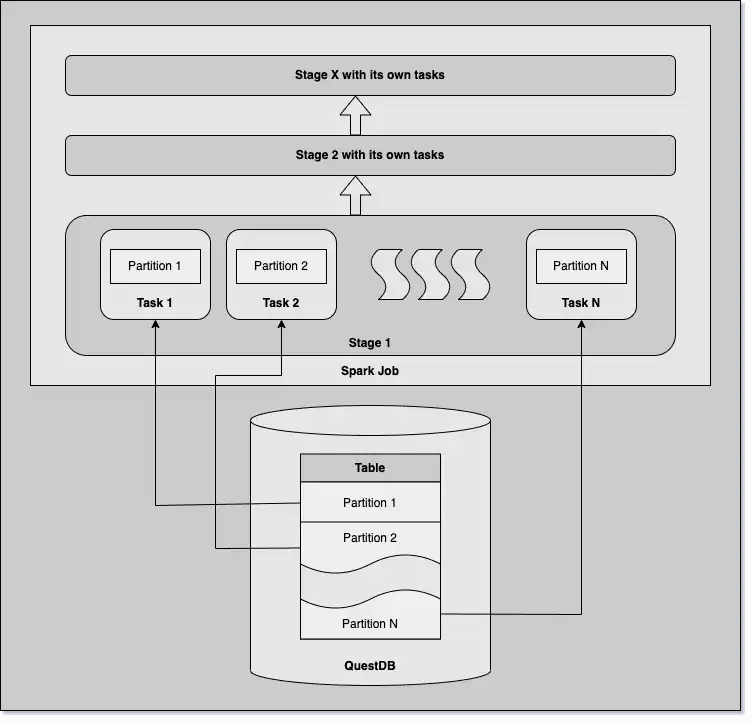
In this tutorial, we will load data from a QuestDB table into a Spark application and explore the inner working of Spark to refine data loading. Finally, we will modify and save the data back to QuestDB.
Loading data to Spark
First thing first, we need to load time-series data from QuestDB. I will use an
existing table, trades, with just over 1.3 million rows.
It contains bitcoin trades, spanning over 3 days: not exactly a big data scenario but good enough to experiment.
The table contains the following columns:
| Column Name | Column Type |
|---|---|
symbol | SYMBOL |
side | SYMBOL |
price | DOUBLE |
amount | DOUBLE |
timestamp | TIMESTAMP |
The table is partitioned by day, and the timestamp column serves as the
designated timestamp.
QuestDB accepts connections via Postgres wire protocol, so we can use JDBC to integrate. You can choose from various languages to create Spark applications, and here we will go for Python.
Create the script, sparktest.py:
from pyspark.sql import SparkSession
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# load 'trades' table into the dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "trades") \
.load()
# print the number of rows
print(df.count())
# do some filtering and print the first 3 rows of the data
df = df.filter(df.symbol == 'BTC-USD').filter(df.side == 'buy')
df.show(3, truncate=False)
Believe it or not, this tiny application already reads data from the database when submitted as a Spark job.
spark-submit --jars postgresql-42.5.1.jar sparktest.py
The job prints the following row count:
1322570
And these are the first 3 rows of the filtered table:
+-------+----+--------+---------+--------------------------+
|symbol |side|price |amount |timestamp |
+-------+----+--------+---------+--------------------------+
|BTC-USD|buy |23128.72|6.4065E-4|2023-02-01 00:00:00.141334|
|BTC-USD|buy |23128.33|3.7407E-4|2023-02-01 00:00:01.169344|
|BTC-USD|buy |23128.33|8.1796E-4|2023-02-01 00:00:01.184992|
+-------+----+--------+---------+--------------------------+
only showing top 3 rows
Although sparktest.py speaks for itself, it is still worth mentioning that
this application has a dependency on the JDBC driver located in
postgresql-42.5.1.jar. It cannot run without this dependency; hence it has to
be submitted to Spark together with the application.
Optimizing data loading with Spark
We have loaded data into Spark. Now we will look at how this was completed and some aspects to consider.
The easiest way to peek under the hood is to check QuestDB's log, which should tell us how Spark interacted with the database. We will also make use of the Spark UI, which displays useful insights of the execution, including stages and tasks.
Spark connection to QuestDB: Spark is lazy
QuestDB log shows that Spark connected three times to the database. For simplicity I only show the relevant lines in the log:
2023-03-21T21:12:24.031443Z I pg-server connected [ip=127.0.0.1, fd=129]
2023-03-21T21:12:24.060520Z I i.q.c.p.PGConnectionContext parse [fd=129, q=SELECT * FROM trades WHERE 1=0]
2023-03-21T21:12:24.072262Z I pg-server disconnected [ip=127.0.0.1, fd=129, src=queue]
Spark first queried the database when we created the DataFrame, but as it turns
out, it was not too interested in the data itself. The query looked like this:
SELECT * FROM trades WHERE 1=0
The only thing Spark wanted to know was the schema of the table in order to create an empty DataFrame. Spark evaluates expressions lazily, and only does the bare minimum required at each step. After all, it is meant to analyze big data, so resources are incredibly precious for Spark. Especially memory: data is not cached by default.
The second connection happened when Spark counted the rows of the DataFrame. It
did not query the data this time, either. Interestingly, instead of pushing the
aggregation down to the database by running SELECT count(*) FROM trades, it
just queried a 1 for each record: SELECT 1 FROM trades. Spark adds the 1s
together to get the actual count.
2023-03-21T21:12:25.692098Z I pg-server connected [ip=127.0.0.1, fd=129]
2023-03-21T21:12:25.693863Z I i.q.c.p.PGConnectionContext parse [fd=129, q=SELECT 1 FROM trades ]
2023-03-21T21:12:25.695284Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-01.2 [rowCount=487309, partitionNameTxn=2, transientRowCount=377783, partitionIndex=0, partitionCount=3]
2023-03-21T21:12:25.749986Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-02.1 [rowCount=457478, partitionNameTxn=1, transientRowCount=377783, partitionIndex=1, partitionCount=3]
2023-03-21T21:12:25.800765Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-03.0 [rowCount=377783, partitionNameTxn=0, transientRowCount=377783, partitionIndex=2, partitionCount=3]
2023-03-21T21:12:25.881785Z I pg-server disconnected [ip=127.0.0.1, fd=129, src=queue]
Working with the data itself eventually forced Spark to get a taste of the table's content too. Filters are pushed down to the database by default.
2023-03-21T21:12:26.132570Z I pg-server connected [ip=127.0.0.1, fd=28]
2023-03-21T21:12:26.134355Z I i.q.c.p.PGConnectionContext parse [fd=28, q=SELECT "symbol","side","price","amount","timestamp" FROM trades WHERE ("symbol" IS NOT NULL) AND ("side" IS NOT NULL) AND ("symbol" = 'BTC-USD') AND ("side" = 'buy') ]
2023-03-21T21:12:26.739124Z I pg-server disconnected [ip=127.0.0.1, fd=28, src=queue]
We can see that Spark's interaction with the database is rather sophisticated, and optimized to achieve good performance without wasting resources. The Spark DataFrame is the key component which takes care of the optimization, and it deserves some further analysis.
What is a Spark DataFrame?
The name DataFrame sounds like a container to hold data, but we have seen it
earlier that this is not really true. So what is a Spark DataFrame then?
One way to look at Spark SQL, with the risk of oversimplifying it, is that it is
a query engine. df.filter(predicate) is really just another way of saying
WHERE predicate. With this in mind, the DataFrame is pretty much a query, or
actually more like a query plan.
Most databases come with functionality to display query plans, and Spark has it too! Let's check the plan for the above DataFrame we just created:
df.explain(extended=True)
== Parsed Logical Plan ==
Filter (side#1 = buy)
+- Filter (symbol#0 = BTC-USD)
+- Relation [symbol#0,side#1,price#2,amount#3,timestamp#4] JDBCRelation(trades) [numPartitions=1]
== Analyzed Logical Plan ==
symbol: string, side: string, price: double, amount: double, timestamp: timestamp
Filter (side#1 = buy)
+- Filter (symbol#0 = BTC-USD)
+- Relation [symbol#0,side#1,price#2,amount#3,timestamp#4] JDBCRelation(trades) [numPartitions=1]
== Optimized Logical Plan ==
Filter ((isnotnull(symbol#0) AND isnotnull(side#1)) AND ((symbol#0 = BTC-USD) AND (side#1 = buy)))
+- Relation [symbol#0,side#1,price#2,amount#3,timestamp#4] JDBCRelation(trades) [numPartitions=1]
== Physical Plan ==
*(1) Scan JDBCRelation(trades) [numPartitions=1] [symbol#0,side#1,price#2,amount#3,timestamp#4] PushedFilters: [*IsNotNull(symbol), *IsNotNull(side), *EqualTo(symbol,BTC-USD), *EqualTo(side,buy)], ReadSchema: struct<symbol:string,side:string,price:double,amount:double,timestamp:timestamp>
If the DataFrame knows how to reproduce the data by remembering the execution plan, it does not need to store the actual data. This is precisely what we have seen earlier. Spark desperately tried not to load our data, but this can have disadvantages too.
Caching data
Not caching the data radically reduces Spark's memory footprint, but there is a bit of jugglery here. Data does not have to be cached because the plan printed above can be executed again and again and again...
Now imagine how a mere decently-sized Spark cluster could make our lonely QuestDB instance suffer martyrdom.
With a massive table containing many partitions, Spark would generate a large number of tasks to be executed parallel across different nodes of the cluster. These tasks would query the table almost simultaneously, putting a heavy load on the database. So, if you find your colleagues cooking breakfast on your database servers, consider forcing Spark to cache some data to reduce the number of trips to the database.
This can be done by calling df.cache(). In a large application, it might
require a bit of thinking about what is worth caching and how to ensure that
Spark executors have enough memory to store the data.
In practice, you should consider caching smallish datasets used frequently throughout the application's life.
Let's rerun our code with a tiny modification, adding .cache():
from pyspark.sql import SparkSession
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# load 'trades' table into the dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "trades") \
.load() \
.cache()
# print the number of rows
print(df.count())
# print the first 3 rows of the data
df.show(3, truncate=False)
This time Spark hit the database only twice. First, it came for the schema, the
second time for the data:
SELECT "symbol","side","price","amount","timestamp" FROM trades.
2023-03-21T21:13:04.122390Z I pg-server connected [ip=127.0.0.1, fd=129]
2023-03-21T21:13:04.147353Z I i.q.c.p.PGConnectionContext parse [fd=129, q=SELECT * FROM trades WHERE 1=0]
2023-03-21T21:13:04.159470Z I pg-server disconnected [ip=127.0.0.1, fd=129, src=queue]
2023-03-21T21:13:05.873960Z I pg-server connected [ip=127.0.0.1, fd=129]
2023-03-21T21:13:05.875951Z I i.q.c.p.PGConnectionContext parse [fd=129, q=SELECT "symbol","side","price","amount","timestamp" FROM trades ]
2023-03-21T21:13:05.876615Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-01.2 [rowCount=487309, partitionNameTxn=2, transientRowCount=377783, partitionIndex=0, partitionCount=3]
2023-03-21T21:13:06.259472Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-02.1 [rowCount=457478, partitionNameTxn=1, transientRowCount=377783, partitionIndex=1, partitionCount=3]
2023-03-21T21:13:06.653769Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-03.0 [rowCount=377783, partitionNameTxn=0, transientRowCount=377783, partitionIndex=2, partitionCount=3]
2023-03-21T21:13:08.479209Z I pg-server disconnected [ip=127.0.0.1, fd=129, src=queue]
Clearly, even a few carefully placed .cache() calls can improve the overall
performance of an application, sometimes significantly. What else should we take
into consideration when thinking about performance?
Earlier, we mentioned that our Spark application consists of tasks, which are working on the different partitions of the data parallel. So, partitioned data mean parallelism, which results in better performance.
Spark data partitioning
Now we turn to the Spark UI.
It tells us that the job was done in a single task:
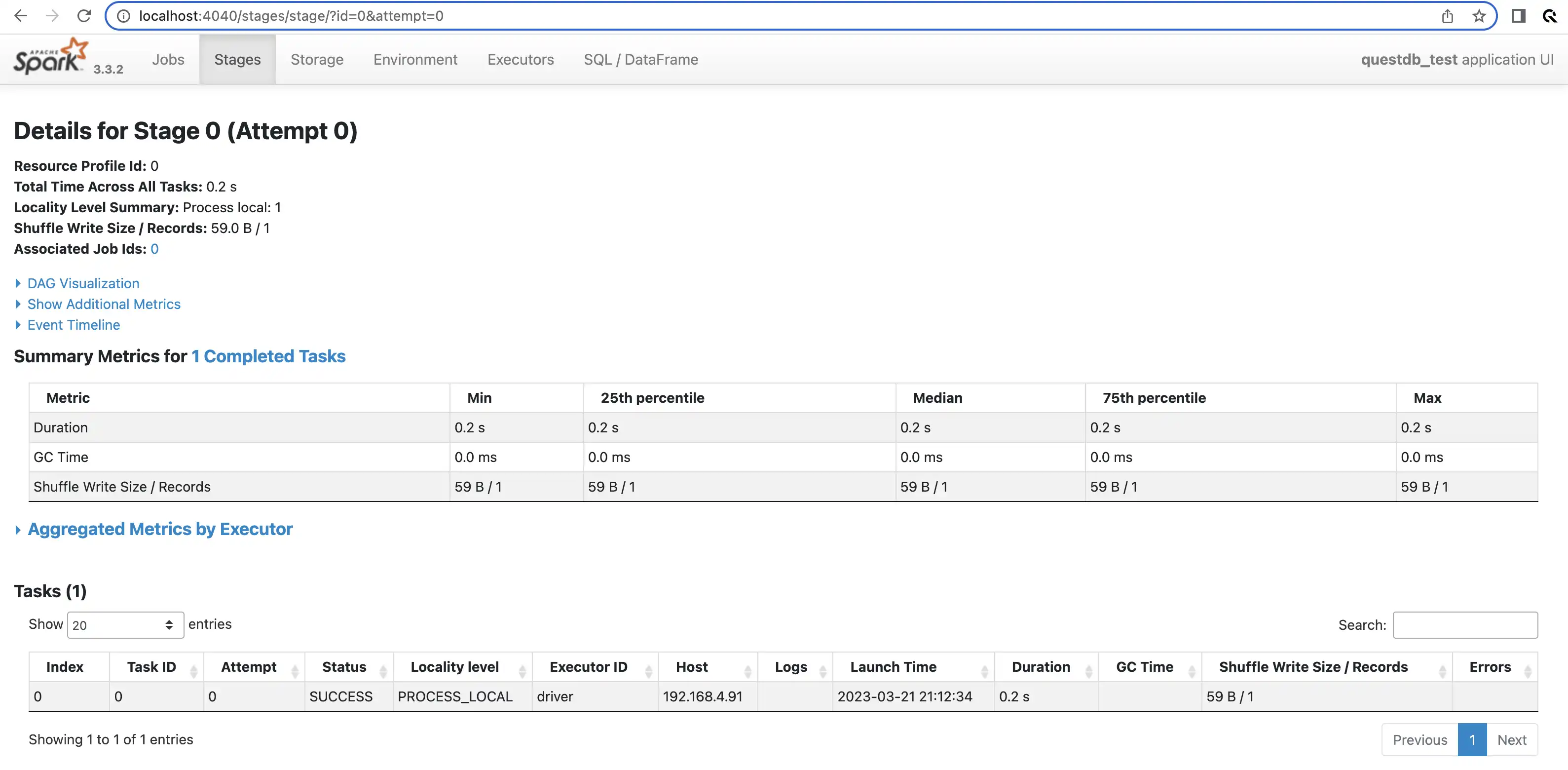
The truth is that we have already suspected this. The execution plan told us
(numPartitions=1) and we did not see any parallelism in the QuestDB logs
either. We can display more details about this partition with a bit of
additional code:
from pyspark.sql.functions import spark_partition_id, min, max, count
df = df.withColumn("partitionId", spark_partition_id())
df.groupBy(df.partitionId) \
.agg(min(df.timestamp), max(df.timestamp), count(df.partitionId)) \
.show(truncate=False)
+-----------+--------------------------+--------------------------+------------------+
|partitionId|min(timestamp) |max(timestamp) |count(partitionId)|
+-----------+--------------------------+--------------------------+------------------+
|0 |2023-02-01 00:00:00.078073|2023-02-03 23:59:59.801778|1322570 |
+-----------+--------------------------+--------------------------+------------------+
The UI helps us confirm that the data is loaded as a single partition. QuestDB stores this data in 3 partitions. We should try to fix this.
Although it is not recommended, we can try to use DataFrame.repartition().
This call reshuffles data across the cluster while
partitioning the data, so it should be our
last resort. After running df.repartition(3, df.timestamp), we see 3
partitions, but not exactly the way we expected. The partitions overlap with one
another:
+-----------+--------------------------+--------------------------+------------------+
|partitionId|min(timestamp) |max(timestamp) |count(partitionId)|
+-----------+--------------------------+--------------------------+------------------+
|0 |2023-02-01 00:00:00.698152|2023-02-03 23:59:59.801778|438550 |
|1 |2023-02-01 00:00:00.078073|2023-02-03 23:59:57.188894|440362 |
|2 |2023-02-01 00:00:00.828943|2023-02-03 23:59:59.309075|443658 |
+-----------+--------------------------+--------------------------+------------------+
It seems that DataFrame.repartition() used hashes to distribute the rows
across the 3 partitions. This would mean that all 3 tasks would require data
from all 3 QuestDB partitions.
Let's try this instead: df.repartitionByRange(3, "timestamp"):
+-----------+--------------------------+--------------------------+------------------+
|partitionId|min(timestamp) |max(timestamp) |count(partitionId)|
+-----------+--------------------------+--------------------------+------------------+
|0 |2023-02-01 00:00:00.078073|2023-02-01 21:22:35.656399|429389 |
|1 |2023-02-01 21:22:35.665599|2023-02-02 21:45:02.613339|470372 |
|2 |2023-02-02 21:45:02.641778|2023-02-03 23:59:59.801778|422809 |
+-----------+--------------------------+--------------------------+------------------+
This looks better but still not ideal. That is because
DaraFrame.repartitionByRange() samples the dataset and then estimates the
borders of the partitions.
What we really want is for the DataFrame partitions to match exactly the partitions we see in QuestDB. This way, the tasks running parallel in Spark do not cross their way in QuestDB, likely to result in better performance.
Data source options are to the rescue! Let's try the following:
from pyspark.sql import SparkSession
from pyspark.sql.functions import spark_partition_id, min, max, count
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# load 'trades' table into the dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "trades") \
.option("partitionColumn", "timestamp") \
.option("numPartitions", "3") \
.option("lowerBound", "2023-02-01T00:00:00.000000Z") \
.option("upperBound", "2023-02-04T00:00:00.000000Z") \
.load()
df = df.withColumn("partitionId", spark_partition_id())
df.groupBy(df.partitionId) \
.agg(min(df.timestamp), max(df.timestamp), count(df.partitionId)) \
.show(truncate=False)
+-----------+--------------------------+--------------------------+------------------+
|partitionId|min(timestamp) |max(timestamp) |count(partitionId)|
+-----------+--------------------------+--------------------------+------------------+
|0 |2023-02-01 00:00:00.078073|2023-02-01 23:59:59.664083|487309 |
|1 |2023-02-02 00:00:00.188002|2023-02-02 23:59:59.838473|457478 |
|2 |2023-02-03 00:00:00.565319|2023-02-03 23:59:59.801778|377783 |
+-----------+--------------------------+--------------------------+------------------+
After specifying partitionColumn, numPartitions, lowerBound, and
upperBound, the situation is much better: the row counts in the partitions
match what we have seen in the QuestDB logs earlier: rowCount=487309,
rowCount=457478 and rowCount=377783. Looks like we did it!
2023-03-21T21:13:05.876615Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-01.2 [rowCount=487309, partitionNameTxn=2, transientRowCount=377783, partitionIndex=0, partitionCount=3]
2023-03-21T21:13:06.259472Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-02.1 [rowCount=457478, partitionNameTxn=1, transientRowCount=377783, partitionIndex=1, partitionCount=3]
2023-03-21T21:13:06.653769Z I i.q.c.TableReader open partition /Users/imre/Work/dbroot/db/trades~10/2023-02-03.0 [rowCount=377783, partitionNameTxn=0, transientRowCount=377783, partitionIndex=2, partitionCount=3]
We can check Spark UI again; it also confirms that the job was completed in 3 separate tasks, each of them working on a single partition.
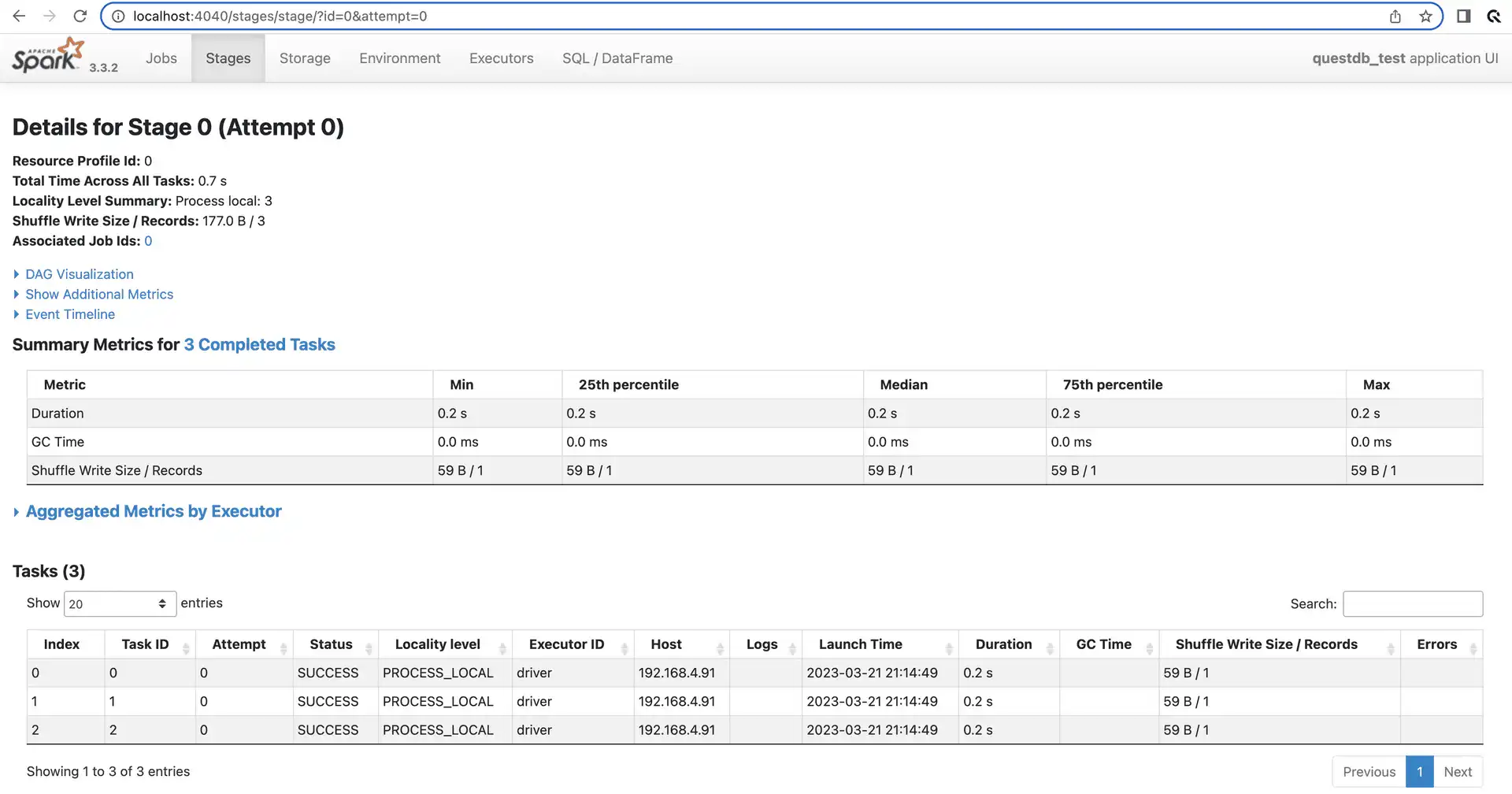
Sometimes it might be tricky to know the minimum and maximum timestamps when creating the DataFrame. In the worst case, you could query the database for those values via an ordinary connection.
We have managed to replicate our QuestDB partitions in Spark, but data does not always come from a single table. What if the data required is the result of a query? Can we load that, and is it possible to partition it?
Options to load data: SQL query vs table
We can use the query option to load data from QuestDB with the help of a SQL
query:
# 1-minute aggregated trade data
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("query", "SELECT symbol, sum(amount) as volume, "
"min(price) as minimum, max(price) as maximum, "
"round((max(price)+min(price))/2, 2) as mid, "
"timestamp as ts "
"FROM trades WHERE symbol = 'BTC-USD' "
"SAMPLE BY 1m ALIGN to CALENDAR") \
.load()
Depending on the amount of data and the actual query, you might find that pushing the aggregations to QuestDB is faster than completing it in Spark. Spark definitely has an edge when the dataset is really large.
Now let's try partitioning this DataFrame
with the options used before with the option dbtable. Unfortunately, we will
get an error message:
Options 'query' and 'partitionColumn' can not be specified together.
However, we can trick Spark by just giving the query an alias name. This means
we can go back to using the dbtable option again, which lets us specify
partitioning. See the example below:
from pyspark.sql import SparkSession
from pyspark.sql.functions import spark_partition_id, min, max, count
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# load 1-minute aggregated trade data into the dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "(SELECT symbol, sum(amount) as volume, "
"min(price) as minimum, max(price) as maximum, "
"round((max(price)+min(price))/2, 2) as mid, "
"timestamp as ts "
"FROM trades WHERE symbol = 'BTC-USD' "
"SAMPLE BY 1m ALIGN to CALENDAR) AS fake_table") \
.option("partitionColumn", "ts") \
.option("numPartitions", "3") \
.option("lowerBound", "2023-02-01T00:00:00.000000Z") \
.option("upperBound", "2023-02-04T00:00:00.000000Z") \
.load()
df = df.withColumn("partitionId", spark_partition_id())
df.groupBy(df.partitionId) \
.agg(min(df.ts), max(df.ts), count(df.partitionId)) \
.show(truncate=False)
+-----------+-------------------+-------------------+------------------+
|partitionId|min(ts) |max(ts) |count(partitionId)|
+-----------+-------------------+-------------------+------------------+
|0 |2023-02-01 00:00:00|2023-02-01 23:59:00|1440 |
|1 |2023-02-02 00:00:00|2023-02-02 23:59:00|1440 |
|2 |2023-02-03 00:00:00|2023-02-03 23:59:00|1440 |
+-----------+-------------------+-------------------+------------------+
Looking good. Now it seems that we can load any data from QuestDB into Spark by passing a SQL query to the DataFrame. Do we, really?
Our trades table is limited to three data types only. What about all the other
types you can find in QuestDB?
We expect that Spark will successfully map a double or a timestamp when
queried from the database, but what about a geohash? It is not that obvious
what is going to happen.
As always, when unsure, we should test.
Type mappings
I have another table in the database with a different schema. This table has a column for each type currently available in QuestDB.
CREATE TABLE all_types (
symbol SYMBOL,
string STRING,
char CHAR,
long LONG,
int INT,
short SHORT,
byte BYTE,
double DOUBLE,
float FLOAT,
bool BOOLEAN,
uuid UUID,
--long128 LONG128,
long256 LONG256,
bin BINARY,
g5c GEOHASH(5c),
date DATE,
timestamp TIMESTAMP
) timestamp (timestamp) PARTITION BY DAY;
INSERT INTO all_types values('sym1', 'str1', 'a', 456, 345, 234, 123, 888.8,
11.1, true, '9f9b2131-d49f-4d1d-ab81-39815c50d341',
--to_long128(10, 5),
rnd_long256(), rnd_bin(10,20,2), rnd_geohash(35),
to_date('2022-02-01', 'yyyy-MM-dd'),
to_timestamp('2022-01-15T00:00:03.234', 'yyyy-MM-ddTHH:mm:ss.SSS'));
long128 is not fully supported by QuestDB yet, so it is commented out.
Let's try to load and print the data; we can also take a look at the schema of the DataFrame:
from pyspark.sql import SparkSession
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# create dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "all_types") \
.load()
# print the schema
print(df.schema)
# print the content of the dataframe
df.show(truncate=False)
Much to my surprise, Spark managed to create the DataFrame and mapped all types.
Here is the schema:
StructType([
StructField('symbol', StringType(), True),
StructField('string', StringType(), True),
StructField('char', StringType(), True),
StructField('long', LongType(), True),
StructField('int', IntegerType(), True),
StructField('short', ShortType(), True),
StructField('byte', ShortType(), True),
StructField('double', DoubleType(), True),
StructField('float', FloatType(), True),
StructField('bool', BooleanType(), True),
StructField('uuid', StringType(), True),
# StructField('long128', StringType(), True),
StructField('long256', StringType(), True),
StructField('bin', BinaryType(), True),
StructField('g5c', StringType(), True),
StructField('date', TimestampType(), True),
StructField('timestamp', TimestampType(), True)
])
It looks pretty good but you might wonder if it is a good idea to map long256
and geohash types to String. QuestDB does not provide arithmetics for these
types, so it is not a big deal.
Geohashes are basically 32-base numbers, represented and stored in their string
format. The 256-bit long values are also treated as string literals. long256
is used to store cryptocurrency private keys.
Now let's see the data:
+------+------+----+----+---+-----+----+------+-----+----+------------------------------------+
|symbol|string|char|long|int|short|byte|double|float|bool|uuid |
+------+------+----+----+---+-----+----+------+-----+----+------------------------------------+
|sym1 |str1 |a |456 |345|234 |123 |888.8 |11.1 |true|9f9b2131-d49f-4d1d-ab81-39815c50d341|
+------+------+----+----+---+-----+----+------+-----+----+------------------------------------+
+------------------------------------------------------------------+----------------------------------------------------+
|long256 |bin |
+------------------------------------------------------------------+----------------------------------------------------+
|0x8ee3c2a42acced0bb0bdb411c82bb01e7e487689228c189d1e865fa0e025973c|[F2 4D 4B F6 18 C2 9A A7 87 C2 D3 19 4A 2C 4B 92 C4]|
+------------------------------------------------------------------+----------------------------------------------------+
+-----+-------------------+-----------------------+
|g5c |date |timestamp |
+-----+-------------------+-----------------------+
|q661k|2022-02-01 00:00:00|2022-01-15 00:00:03.234|
+-----+-------------------+-----------------------+
It also looks good, but we could omit the 00:00:00 from the end of the date
field. We can see that it is mapped to Timestamp and not Date.
We could also try to map one of the numeric fields to Decimal. This can be
useful if later we want to do computations that require high precision.
We can use the customSchema option to customize the column types. Our modified
code:
from pyspark.sql import SparkSession
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# create dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "all_types") \
.option("customSchema", "date DATE, double DECIMAL(38, 10)") \
.load()
# print the schema
print(df.schema)
# print the content of the dataframe
df.show(truncate=False)
The new schema:
StructType([
StructField('symbol', StringType(), True),
StructField('string', StringType(), True),
StructField('char', StringType(), True),
StructField('long', LongType(), True),
StructField('int', IntegerType(), True),
StructField('short', ShortType(), True),
StructField('byte', ShortType(), True),
StructField('double', DecimalType(38,10), True),
StructField('float', FloatType(), True),
StructField('bool', BooleanType(), True),
StructField('uuid', StringType(), True),
# StructField('long128', StringType(), True),
StructField('long256', StringType(), True),
StructField('bin', BinaryType(), True),
StructField('g5c', StringType(), True),
StructField('date', DateType(), True),
StructField('timestamp', TimestampType(), True)
])
And the data is displayed as:
+------+------+----+----+---+-----+----+--------------+-----+----+------------------------------------+
|symbol|string|char|long|int|short|byte|double |float|bool|uuid |
+------+------+----+----+---+-----+----+--------------+-----+----+------------------------------------+
|sym1 |str1 |a |456 |345|234 |123 |888.8000000000|11.1 |true|9f9b2131-d49f-4d1d-ab81-39815c50d341|
+------+------+----+----+---+-----+----+--------------+-----+----+------------------------------------+
+------------------------------------------------------------------+----------------------------------------------------+
|long256 |bin |
+------------------------------------------------------------------+----------------------------------------------------+
|0x8ee3c2a42acced0bb0bdb411c82bb01e7e487689228c189d1e865fa0e025973c|[F2 4D 4B F6 18 C2 9A A7 87 C2 D3 19 4A 2C 4B 92 C4]|
+------------------------------------------------------------------+----------------------------------------------------+
+-----+----------+-----------------------+
|g5c |date |timestamp |
+-----+----------+-----------------------+
|q661k|2022-02-01|2022-01-15 00:00:03.234|
+-----+----------+-----------------------+
It seems that Spark can handle almost all database types. The only issue is
long128, but this type is a work in progress currently in QuestDB. When
completed, it will be mapped as String, just like long256.
Writing data back into the database
There is only one thing left: writing data back into QuestDB.
In this example, first, we will load some data from the database and add two new features:
- 10-minute moving average
- standard deviation, also calculated over the last 10-minute window
Then we will try to save the modified DataFrame back into QuestDB as a new
table. We need to take care of some type mappings as DOUBLE columns are sent
as FLOAT8 to QuestDB by default, so we end up with this code:
from pyspark.sql import SparkSession
from pyspark.sql.window import Window
from pyspark.sql.functions import avg, stddev, when
# create Spark session
spark = SparkSession.builder.appName("questdb_test").getOrCreate()
# load 1-minute aggregated trade data into the dataframe
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "(SELECT symbol, sum(amount) as volume, "
"round((max(price)+min(price))/2, 2) as mid, "
"timestamp as ts "
"FROM trades WHERE symbol = 'BTC-USD' "
"SAMPLE BY 1m ALIGN to CALENDAR) AS fake_table") \
.option("partitionColumn", "ts") \
.option("numPartitions", "3") \
.option("lowerBound", "2023-02-01T00:00:00.000000Z") \
.option("upperBound", "2023-02-04T00:00:00.000000Z") \
.load()
# add new features
window_10 = Window.partitionBy(df.symbol).rowsBetween(-10, Window.currentRow)
df = df.withColumn("ma10", avg(df.mid).over(window_10))
df = df.withColumn("std", stddev(df.mid).over(window_10))
df = df.withColumn("std", when(df.std.isNull(), 0.0).otherwise(df.std))
# save the data as 'trades_enriched'
df.write.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "trades_enriched") \
.option("createTableColumnTypes", "volume DOUBLE, mid DOUBLE, ma10 DOUBLE, std DOUBLE") \
.save()
All works but… we soon realize that our new table, trades_enriched is not
partitioned and does not have a designated timestamp, which is not ideal.
Obviously Spark has no idea of QuestDB specifics.
It would work better if we created the table upfront and Spark only saved the data into it. We drop the table and re-create it; this time, it is partitioned and has a designated timestamp:
DROP TABLE trades_enriched;
CREATE TABLE trades_enriched (
volume DOUBLE,
mid DOUBLE,
ts TIMESTAMP,
ma10 DOUBLE,
std DOUBLE
) timestamp (ts) PARTITION BY DAY;
The table is empty and waiting for the data.
We rerun the code; all works, no complaints. The data is in the table, and it is partitioned.
One aspect of writing data into the database is if we are allowed to create duplicates. What if I try to rerun the code again without dropping the table? Will Spark let me save the data this time? No, we get an error:
pyspark.sql.utils.AnalysisException: Table or view 'trades_enriched' already exists. SaveMode: ErrorIfExists.
The last part of the error message looks interesting: SaveMode: ErrorIfExists.
What is SaveMode? It turns out we can configure what should happen if the
table already exists. Our options are:
errorifexists: the default behavior is to return an error if the table already exists, Spark is playing safe hereappend: data will be appended to the existing rows already present in the tableoverwrite: the content of the table will be replaced entirely by the newly saved dataignore: if the table is not empty, our save operation gets ignored without any error
We have already seen how errorifexists behaves, append and ignore seem to
be simple enough just to work.
However, overwrite is not straightforward. The content of the table must be
cleared before the new data can be saved. Spark will delete and re-create the
table by default, which means losing partitioning and the designated timestamp.
In general, we do not want Spark to create tables for us. Luckily, with the
truncate option we can tell Spark to use TRUNCATE to clear the table instead
of deleting it:
# save the data as 'trades_enriched', overwrite if already exists
df.write.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:8812/questdb") \
.option("driver", "org.postgresql.Driver") \
.option("user", "admin").option("password", "quest") \
.option("dbtable", "trades_enriched") \
.option("truncate", True) \
.option("createTableColumnTypes", "volume DOUBLE, mid DOUBLE, ma10 DOUBLE, std DOUBLE") \
.save(mode="overwrite")
The above works as expected.
Conclusion
Our ride might seem bumpy, but we finally have everything working. Our new motto should be "There is a config option for everything!".
To summarize what we have found:
- We can use Spark's JDBC data source to integrate with QuestDB.
- It is recommended to use the
dbtableoption, even if we use a SQL query to load data. - Always try to specify partitioning options (
partitionColumn,numPartitions,lowerBoundandupperBound) when loading data, partitions ideally should match with the QuestDB partitions. - Sometimes it makes sense to cache some data in Spark to reduce the number of trips to the database.
- It can be beneficial to push work down into the database, depending on the
task and how much data is involved. It makes sense to make use of QuestDB's
time-series-specific features, such as
SAMPLE BY, instead of trying to rewrite it in Spark. - Type mappings can be customized via the
customSchemaoption when loading data. - When writing data into QuestDB always specify the desired saving mode.
- Generally works better if you create the table upfront and do not let Spark create it, because this way you can add partitioning and designated timestamp.
- If selected the
overwritesaving mode, you should enable thetruncateoption too to make sure Spark does not delete the table; hence partitioning and the designated timestamp will not get lost. - Type mappings can be customized via the
createTableColumnTypesoption when saving data.
I mentioned only the config options which are most likely to be tweaked when working with QuestDB; the complete set of options can be found here: Spark data source options.
What could the future bring?
Overall everything works, but it would be nice to have a much more seamless way
of integration, where partitioning would be taken care of automagically. Some
type mappings could use better defaults, too, when saving data into QuestDB. The
overwrite saving mode could default to use TRUNCATE.
More seamless integration is not impossible to achieve. If QuestDB provided its
own JDBCDialect implementation for Spark, the above nuances could be handled.
We should probably consider adding this.
Finally, there is one more thing we did not mention yet, data locality. That is because, currently QuestDB cannot run as a cluster. However, we are actively working on a solution - check out The Inner Workings of Distributed Databases for more information.
When the time comes, we should ensure that data locality is also considered. Ideally, each Spark node would work on tasks that require partitions loaded from the local (or closest) QuestDB instance.
However, this is not something we should be concerned about at this moment... for now, just enjoy data crunching!