Database partitioning (or data partitioning) is a technique used to split data in a large database into smaller chunks called partitions. Each partition is then stored and accessed separately to improve the performance and scalability of the database system.
Database partitioning strategies apply to different types of databases such as SQL databases (e.g., MySQL, PostgreSQL), NoSQL databases (e.g., MongoDB, Cassandra), or time series databases like QuestDB.
Advantages of database partitioning
The primary motivation for database partitioning is to improve the performance and scalability of large databases by distributing the data that can be accessed independently.
By dividing the data into partitions, databases can avoid reading from partitions that are not needed for queries that only need a subset of the data collocated in a partition. This allows the database to reduce expensive disk I/O calls and return the data much quicker.
Database partitioning vs. sharding
Database partitioning deals with a single database instance, whereas sharding splits partitions (shards) across multiple database instances for scalability and availability.
When a database is sharded, partitions are stored and managed by discrete servers that may run in different VMs, zones, or regions. Shards can even be replicated across servers to service more requests concurrently.
Finally, individual shards can be backed up, restored, or repaired independently to minimize the impact of hardware failures on a single database.
Types of database partitioning
There are two major types of database partitioning approaches:
Vertical partitioning
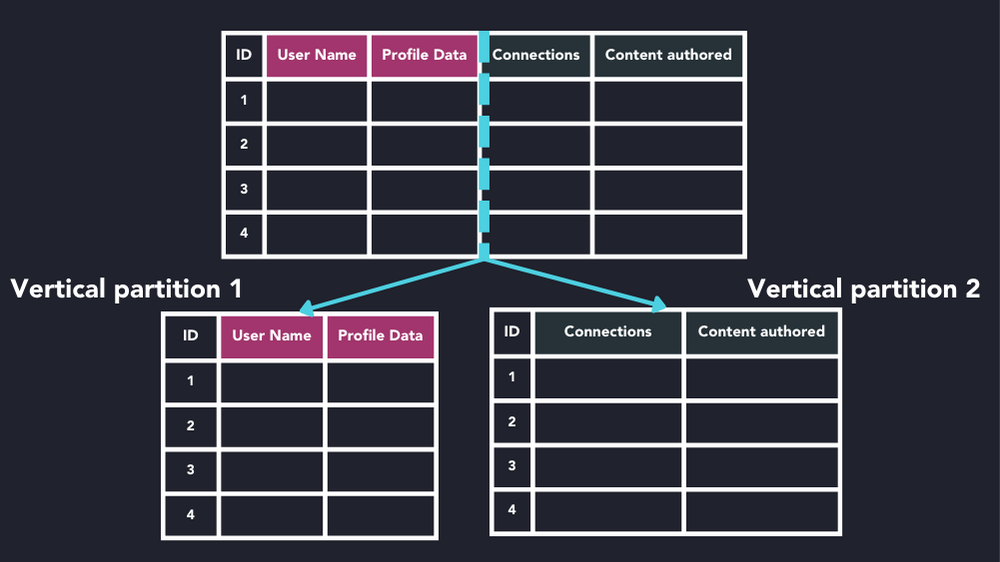
In vertical partitioning, columns of a table are divided into partitions with each partition containing one or more columns from the table. This approach is useful when some columns are accessed more frequently than others.
Data partitioning is often combined with sharding: frequently accessed columns may be split into different partitions and sharded to run on discrete servers. Alternatively, columns that are rarely used may be partitioned to a cheaper and slower storage solution to reduce the I/O overhead.
One of the downsides to vertical partitioning is that when a query needs to span multiple partitions, combining the results from those partitions may be slow or complicated. Also, as the database scales, partitions may need to be split even further to meet the demand.
Horizontal partitioning
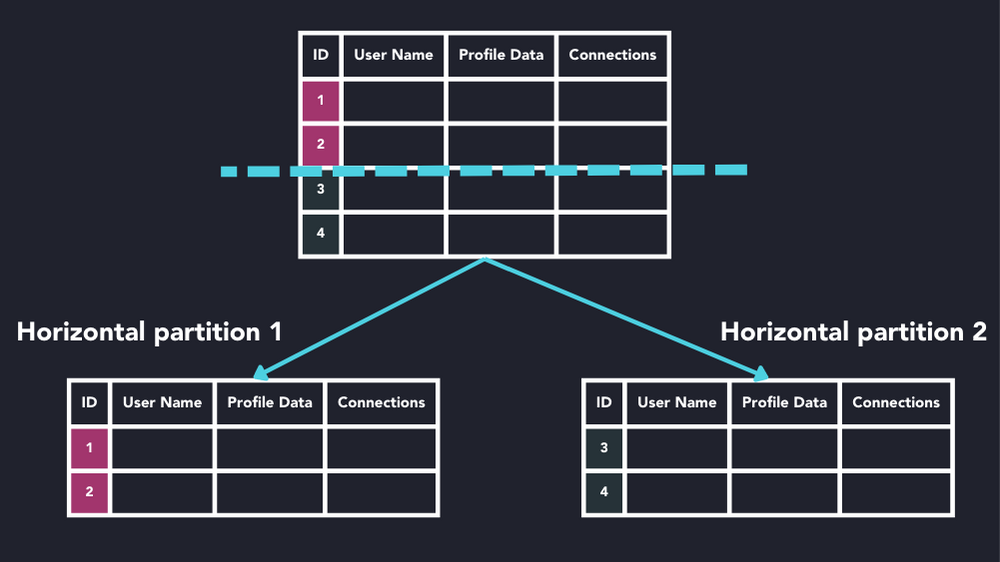
On the other hand, horizontal partitioning works by splitting the table by rows based on the partition key. In this approach, each row of the table is assigned to a partition based on some criteria, which include:
-
Range-based partitioning: data is split based on a range that does not overlap. The most common example is partitioning by time on time series workloads. Data can be partitioned by some time interval (e.g., daily, weekly, monthly) to aid range-based search. Old partitions can easily be archived to serve queries for newer ranges more efficiently.
-
List-based partitioning: data is split based on discrete sets of values, usually from a particular column.
For example, a table containing sales data may be partitioned by geo-regions such as North America or Asia-Pacific regions. Partitions may be further split into subsections.
-
Hash-based partitioning: data is split based on some hashing algorithm. Hash-based partitioning applies a hash function to one or more columns to determine which partition to send the request to.
For example, we may use a simple modulo function on the employee id field or use a complicated cryptographic hashing function on an IP address to divide the data. When a non-trivial hash function is used, hash-based partitioning tends to distribute the data evenly across partitions. However, depending on the function, adding or removing a new partition may require an expensive migration process.
-
Composite partitioning: any of the aforementioned methods can be combined. For example, a time series workload may first be partitioned by time and further split based on another column field.
One thing to note with horizontal partitioning is that the performance depends heavily on how evenly distributed the data is across the partitions. If the data distribution is skewed, the partition with the most records will become the bottleneck.
Also, most analytical databases employ horizontal partitioning strategies over vertical partitioning. Some popular file formats such as Apache Parquet support partitioning natively, making it ideal for big data processing.
Partitioning in QuestDB
QuestDB supports data partitioning by intervals of time, including hour, day, week, month, and year. Tables that are partitioned by time perform better for timestamp interval searches, as QuestDB’s SQL optimizer leverages partitioning to reduce disk I/O.
QuestDB also supports attaching or detaching partitions to archive data for storage optimization.