QuestDB and Raspberry Pi 5 benchmark, a pocket-sized powerhouse
Compute costs, power costs and storage costs are going up. Developers are looking for cost-friendly alternatives. Enter the Raspberry Pi 5, which is mighty far beyond its form-factor. Paired with a next gen database, how does it perform with intensive workloads?
Pretty well! So well infact that perhaps the data centre of the future is a Raspberry Pi cluster in the corner of your office? Impossible!
Or is it? Let's find out.
This article will evaluate raw database performance.
We'll see what we can get out of the Pi5's minimal, power-efficient package.
The Why of Pi
For those unfamiliar, the Raspberry Pi is a small, integrated computing device. It comes equipped with concise and minimal hardware. Since its creation in 2012, the Pi has gotten better with each release. The 5 marks a standout year. Why? Performance and power efficiency.
It's equipped with a 2.4 GHz Quad-Core 64-bit ARM Cortex-A76. It's small enough to maintain its power-sipping nature, while offering enough juice for common server workloads or a proper "desktop grade" experience. The onboard GPU even supports Vulkan 1.2 which can offer light gaming if that's your thing. Our recommendation? Factorio!
The Raspberry Pi comes in 4GB and 8GB models and is deeply extensible. It has ports that can attach to a variety of sensors and common peripherals. Out of the box, it uses a small SD card for storage:

If you're interested in setting up a Pi on your own, we have a guide to follow which outlines all the setup work: How to upgrade and benchmark a Raspberry Pi.
We've benchmarked QuestDB using the 4GB version.
And?!
The results...
First: ingestion.
Ingestion benchmark results
We can see the average, median and max by scale and worker count.
This is every second, and the value indicates number of rows ingested:
| Scale | Workers | Avg. | Median | Max |
|---|---|---|---|---|
| 100 | 4 | 348882 | 346908 | 360503 |
| 8 | 331748 | 332514 | 334071 | |
| 12 | 329552 | 330254 | 330512 | |
| 1000 | 4 | 301448 | 298256 | 311138 |
| 8 | 303412 | 299620 | 311846 | |
| 12 | 297293 | 295555 | 305407 | |
| 4000 | 4 | 293759 | 293013 | 298257 |
| 8 | 265472 | 265778 | 275438 | |
| 12 | 265083 | 265455 | 272074 | |
| 100,000 | 4 | 270486 | 269556 | 274466 |
| 8 | 263547 | 280731 | 285468 | |
| 12 | 233756 | 221700 | 265499 | |
| 1,000,000 | 4 | 311230 | 311292 | 312914 |
| 8 | 294654 | 302839 | 304174 | |
| 12 | 282393 | 282387 | 282521 |
With 4 workers, QuestDB can easily handle near or over 300,000 rows per second in most scenarios. Additional workers don't necessarily help with such a small pool of resources. More RAM may change the equation, but that's unlikely - especially as the initial set of 8GB RPi 5 boards seems to have some deficiencies. Ultimately, the bottle neck will be the CPU.
This general shape of data volume captures many real-life use-cases.
Not bad for a computer that can fit into your pocket!
The implications of the results are fascinating.
And what about queries? Are they fast, too?
Query benchmark results
The time-series benchmark suite indicates how long it takes these queries to execute within that many rows and thus metrics. These queries apply a variety of extensions, which are defined as such:

And the results are...
| Type | Mean Query Time (ms) |
|---|---|
| lastpoint | 7980.03 |
| high-cpu-1 | 8.41 |
| high-cpu-all | 75.06 |
| groupby-orderby-limit | 10060.98 |
| double-groupby-1 | 128.82 |
| double-groupby-5 | 113.99 |
| double-groupby-all | 134.53 |
| single-groupby-1-1-1 | 27.89 |
| single-groupby-1-1-12 | 18.97 |
| single-groupby-1-8-1 | 16.51 |
| single-groupby-5-1-1 | 13.57 |
| single-groupby-5-1-12 | 15.72 |
| single-groupby-5-8-1 | 14.14 |
| cpu-max-all-1 | 16.40 |
| cpu-max-all-8 | 10.88 |
There's some struggle in lastpoint and groupby-orderby-limit.
But in most context the results are impressive.
Given the small CPU in the Pi5 and the billion values, not bad!
QuestDB, time-series database
So, what's QuestDB? It's a high-performance time-series database that specializes in any time-based workload. It offers category leading ingestion throughput and blazing fast SQL queries with time-series extensions. It's open source, efficient and built from the ground-up to handle modern industry requirements. As a time-series database, it also provides essentials like out-of-order indexing and de-duplication.
It is extremely high-performing compared to competitors, such as InfluxDB and TimescaleDB:
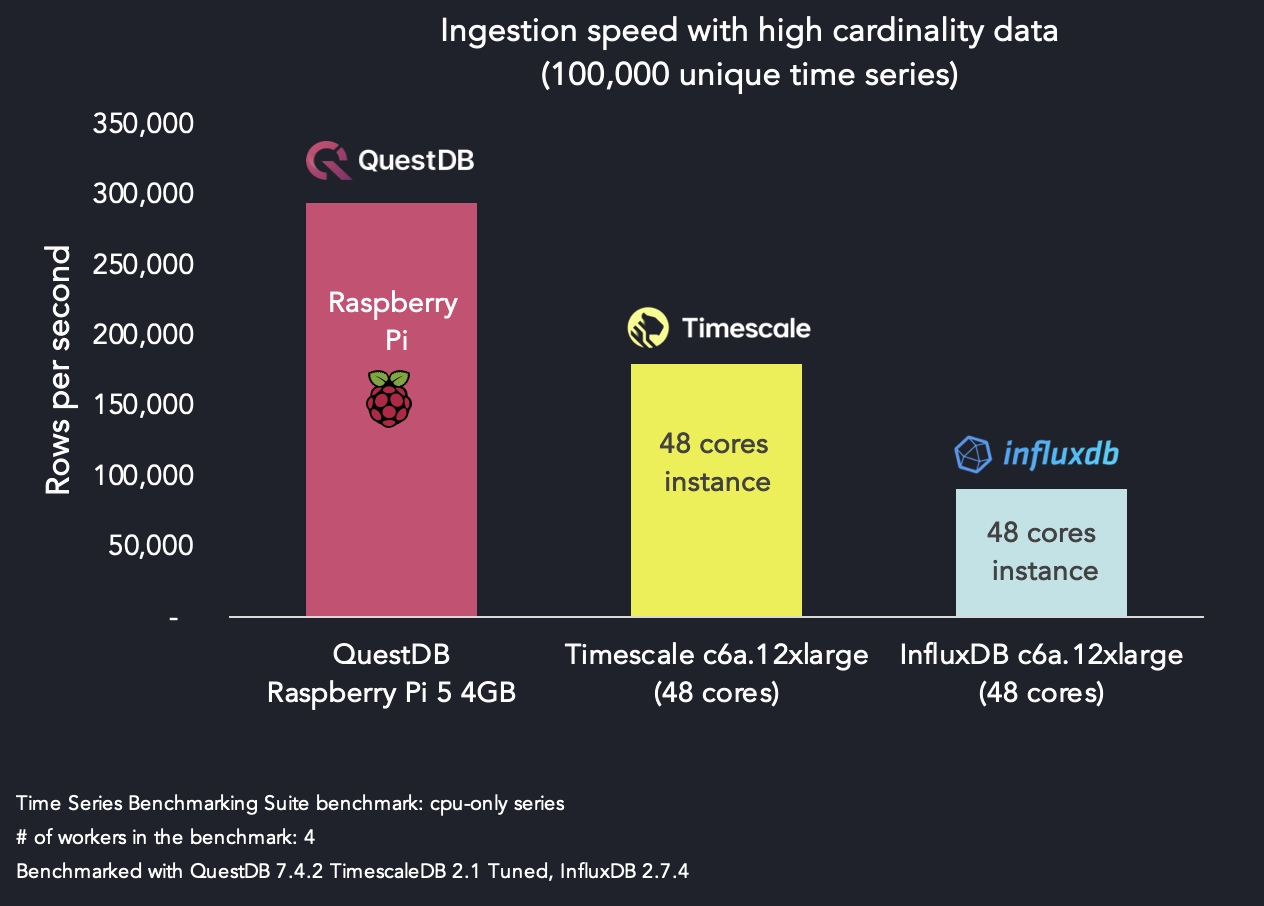
When packaged without Java, QuestDB is less than 10MB. This small package is a key feaure. Why? If building sophisticated sensor arrays, stitching together blockchains or financial data, or working with any stream of data related to time, the performance of an inexpensive, small-yet-punchy device and matching database is of great interest.
After all, data centres like AWS are hyper-sophisticated networks of computers. And you pay for it. But if you can accomplish all of your intensive data analysis with a sub-$100 device, you can save a great deal on costs. And avoid vendor lock-in to boot.
Unpacking the benchmark data
So, what kind of data did we ingest? Server data. Hosts, in particular.
Over 300k rows/second is impressive, but less so if it's very simple data.
The data used by TSBS is "host data".
Servers are everywhere, and they generate waves of host-specific data. The region, its identifier, its operating system, processor type, a timestamp and more, are all included per row:
| hostname | region | datacentre | rack | os | arch | team | service | service_version | service_environment | usage_user | usage_system | usage_idle | usage_nice | usage_iowait | usage_irq | usage_softirq | usage_steal | usage_guest | usage_guest_nice | timestamp |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| host_0 | eu-central-1 | eu-central-1a | 6 | Ubuntu15.10 | x86 | SF | 19 | 1 | test | 58 | 2 | 24 | 61 | 22 | 63 | 6 | 44 | 80 | 38 | 2016-01-01T00:00:00.000000Z |
| host_1 | us-west-1 | us-west-1a | 41 | Ubuntu15.10 | x64 | NYC | 9 | 1 | staging | 84 | 11 | 53 | 87 | 29 | 20 | 54 | 77 | 53 | 74 | 2016-01-01T00:00:00.000000Z |
| host_2 | sa-east-1 | sa-east-1a | 89 | Ubuntu16.04LTS | x86 | LON | 13 | 0 | staging | 29 | 48 | 5 | 63 | 17 | 52 | 60 | 49 | 93 | 1 | 2016-01-01T00:00:00.000000Z |
Our specified sample data time range means we churned out around between 20-40 million rows of data just like this, depending on the scale. Keep in mind that as the number of hosts goes up, so does the cardinality and the difficulty of ingestion.
We sampled 100, 1000, 4000, 100,000 or 1,000,000 servers, or hosts as our scale. This means that we generated information about 1,000,000 servers in bursts every 10 seconds. Each row is also unique. As such, this is very high cardinality. Many databases struggle as cardinality goes up.
The generation is also based on a seed. Using a seed means that our dataset is
deterministic. If anyone wants to replicate just this, use the seed to
replicate our results. And finally, our base parameter for benchmarking is
cpu_only as opposed to a specific use-case like IoT.
Now, enough talkin'.
Let’s generate our data, so you can replicate if you'd like:
#!/bin/bash# Define the base directoryDATA_DIR="/data/quest"mkdir -p $DATA_DIRscales=(100 1000 4000 100000 1000000)for scale in "${scales[@]}"; do# Set the default timeout durationtimeout_duration="2m"echo "Generating data for scale $scale with a timeout of $timeout_duration..."if ! timeout $timeout_duration bin/tsbs_generate_data --use-case="cpu-only" --seed=123 --scale=$scale --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --log-interval="10s" --format="questdb" > $DATA_DIR/cpu_only_$scale; thenecho "Failed to generate data for scale $scale."continue # Skip this scale and go to the nextfiecho "Truncating the last line of scale $scale..."if ! truncate_size=$(tail -n 1 "$DATA_DIR/cpu_only_$scale" | wc -c | xargs); thenecho "Failed to calculate the size of the last line for scale $scale."continue # Skip truncation if last line size calculation failsfiif ! truncate "$DATA_DIR/cpu_only_$scale" -s -$truncate_size; thenecho "Failed to truncate the last line for scale $scale."continue # Skip this scale and go to the nextfiecho "Completed scale $scale."doneecho "All data generation and truncation processes are complete."
This has created all of our sample data.
Now, we need to setup an ingestion exercise and a querying exercise.
Ingestion benchmarking
QuestDB is no stranger to massive data volumes.
We ingested data via QuestDB's InfluxDB Line Protocol support which operates over HTTP.
Another script will do:
#!/bin/bash# Declare arrays to hold scales and worker numbersdeclare -a scales=()declare -a workers=()# Parse command line optionswhile getopts 's:w:' flag; docase "${flag}" ins) scales+=("${OPTARG}") ;;w) workers+=("${OPTARG}") ;;esacdone# Loop through all scale and worker combinationsfor scale in "${scales[@]}"; dofor worker in "${workers[@]}"; do# Drop the CPU table if it exists, suppressing outputif curl "localhost:9000/exec?query=drop%20table%20if%20exists%20cpu" > /dev/null 2>&1; thenecho "Table dropped successfully or did not exist. Running for scale: $scale, workers: $worker"elseecho "Failed to drop table, continuing anyway..."fi# Execute the data loading script with the specified number of workers and direct all output to stdoutbin/tsbs_load_questdb --file="data/quest/cpu_only_$scale" --workers=$workerdonedone
As discussed earlier, we provided different "scale" levels.
For each scale, we'll test using the full set of workers:
bash bench_run.sh -s 100 -s 1000 -s 4000 -s 100000 -s 1000000 -w 4 -w 8 -w 12 >> results/run_1.txt
And we can pass as many workers as we'd like to QuestDB, but given the small hardware profile and 4GB of available RAM, we have maxed out at 12. We suspect that managing workers at million-scale data complexity would ultimately lead to performance degradation.
After we've generated the results, we'll clip out the necessary information:
awk '/Running for scale.*/ || /loaded [0-9]+ rows .*/' results/run_1.txt
That provides our ingestion result.
Query benchmarking
We'll generate the queries, then run them many times for an average.
For this exercise we simulated queries over 100M rows, which adds up to around 1 billion metrics:
#!/bin/bash# Declare arrays to hold scalesdeclare -a scales=()# Declare a scalar for number of queriesdeclare queries=''declare -a query_names=('single-groupby-1-1-1' 'single-groupby-1-1-12' 'single-groupby-1-8-1' 'single-groupby-5-1-1' 'single-groupby-5-1-12' 'single-groupby-5-8-1' 'cpu-max-all-1' 'cpu-max-all-8' 'double-groupby-1' 'double-groupby-5' 'double-groupby-all' 'high-cpu-all' 'high-cpu-1' 'lastpoint' 'groupby-orderby-limit')while getopts 's:q:' flag; docase "${flag}" ins) scales+=("${OPTARG}") ;;q) queries="${OPTARG}" ;; # Set queries as a scalaresacdonefor scale in "${scales[@]}"; doecho "Generating queries for scale: $scale, number of queries: $queries"for query_name in "${query_names[@]}"; doecho "Generating $query_name"output_file="data/quest/${query_name}_scale_${scale}.txt" # Unique filename for each scale and queryif ! bin/tsbs_generate_queries --use-case="cpu-only" --seed=123 --scale=$scale --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --queries="$queries" --query-type="$query_name" --format="questdb" > "$output_file"; thenecho "Failed to generate queries for $query_name at scale $scale."continue # Skip this query and go to the nextfiecho "Running query bench for $query_name"if ! bin/tsbs_run_queries_questdb --file="$output_file" --workers=10 >&1; thenecho "Failed to run queries for $query_name at scale $scale."continue # Skip this query and go to the nextfiecho "$query_name complete."echo ""donedone
Our script also receives a scale value, the same as in the ingestion piece. We'll use 4000, which is in the middle and representative of many real use-cases. We'll also pass the number of times we'll query:
./generate_run_queries.sh -s 4000 -q 1000 >> results/query_1.txt
This is how we generated our query results.
And we should note that this is all systems-driven.
If you'd like to run a regular query on your own, checkout one via our public demo:
SELECT timestamp, avg(l2price(5000,ask_sz_00, ask_px_00,ask_sz_01, ask_px_01,ask_sz_02, ask_px_02,ask_sz_03, ask_px_03,ask_sz_04, ask_px_04,ask_sz_05, ask_px_05,ask_sz_06, ask_px_06,ask_sz_07, ask_px_07,ask_sz_08, ask_px_08,ask_sz_09, ask_px_09) - ask_px_00)FROM AAPL_orderbookWHERE timestamp IN '2023-08-25T13:30:00;6h'SAMPLE BY 10m;
Summary
As more and more workloads pour into the hyper-scaler Clouds, it's neat to see a pocket-sized revolution unfurl in the hardware world. Not long ago these results would have been inconceivable. But the Raspberry Pi 5 is an impressive device. Teamed up with QuestDB, it's an analytics powerhouse in a small package.
When we take a step back, in global networking and data analytics, the speed of light is ultimately the bottle neck. Transporting data from your sensors, apps, rockets, or whatever it may be, over networks can only be so fast. But as these small devices get more powerful, we're capable of putting the analysis right next to or as a part of the sensor, app or device itself.
Though it's a fun thought and not always sane in practice, we can safely wonder: Maybe the data centres of the future are indeed a local, wired-up shoe-box with a bunch of small machines in it and a fan on top.
Want more Pi?
If this sort of thing is up your alley, we've got more fun Pi projects:
- Create an IoT server with QuestDB and a Raspberry Pi
- Build a temperature IoT sensor with Raspberry Pi Pico & QuestDB
- Create an ADS-B flight radar with QuestDB and a Raspberry Pi
- How to upgrade and benchmark a Raspberry Pi
We'd also love to see your benchmarks.
Can you replicate this scenario? Improve upon it?
Is there a DB that can do this better, or faster?
Let us know on social media or in our engaging Community Forum or our public Slack.