Case Study
Syndica uses QuestDB for real-time analytics
Learn how emerging Web3 startup Syndica offers user-facing analytics and real-time dashboards for companies building protocols and decentralized applications.
- Turbo analytics
- Real-time, intensive time-series ingress unphased by high cardinality
- Web3 ready
- At the scale of emerging, data-intensive Web3 protocols
- QuestDB OSS
- Built from open source.

- Avg ingested rows/sec
- 3M+
- Write speed vs InfluxDB
- 10x
- Compression ratio
- 6x
- Cloud up-time
- 99.99999%
On the Web3 frontier
Syndica looked to QuestDB for massive scale
Syndica's sheer volume of collected data leads to unique requirements. But data-in is half the story. Fast queries and data-out are also essential. Dynamic, real-time dashboards for their internal teams and customers led them towards a time-series database.
- Real-Time Analytics
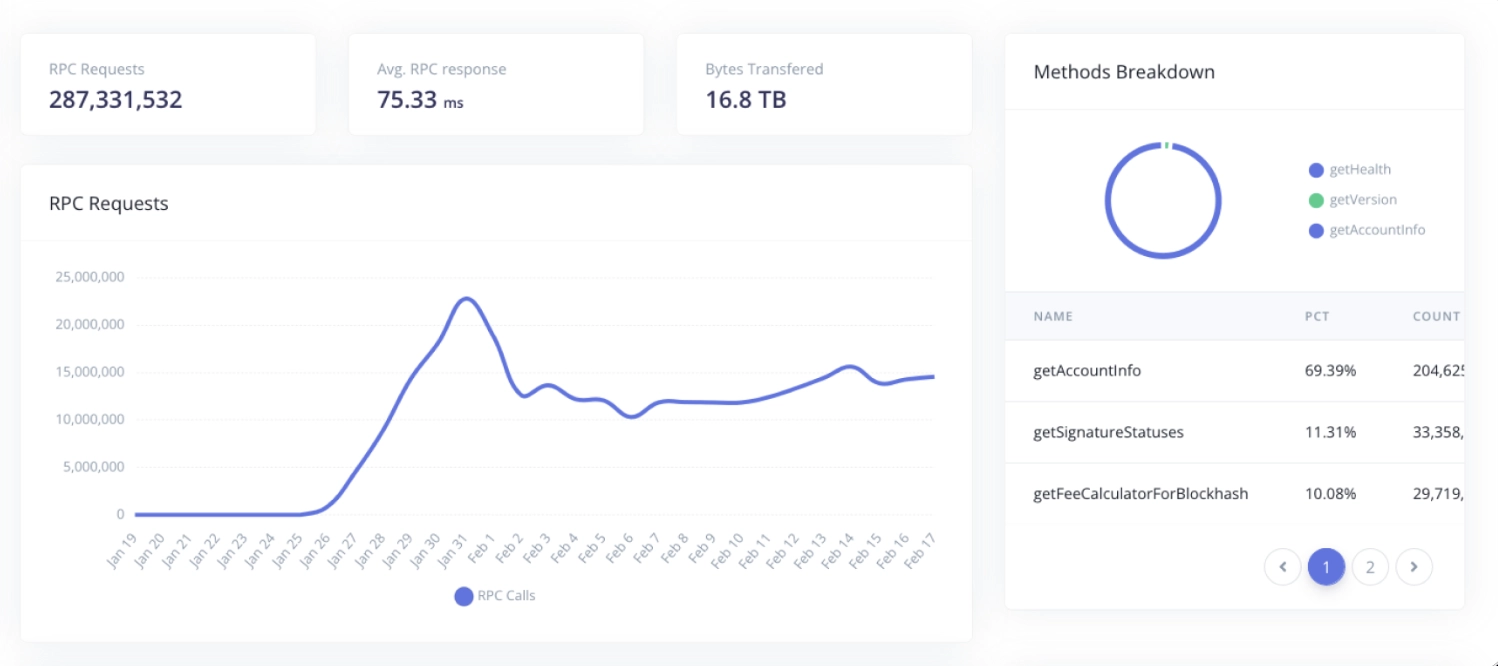
- To provide blazing fast analytics, Syndica uses QuestDB to collect a vast amount of time-series data from their user-accessible node infrastructure and API gateway.

"QuestDB outperforms every database we have tested and delivered a 10x improvement in querying speed. It has become a critical piece of our infrastructure."
SELECTstart_time AS ts,COUNT(*)FROMrequest_logsWHEREtimestamp > dateadd('d', -30, now())AND kind = 'RPC'SAMPLE BY1sFILL(NULL)ALIGN TO CALENDAR
Premium time-series SQL extensions
Deep observability with SQL time-series extensions
Syndica uses SQL time-series extensions like SAMPLE BY for downsampling data. The following query samples massive RPC logs to power Syndica's dashboards. Through these queries, Syndica also provides structured searchable logs for the Syndica RPC. Developers can filter and drill down to very detailed time slices (milliseconds) of logging data to gain ultimate visibility and observability of the running application.
Essential in modern architecture
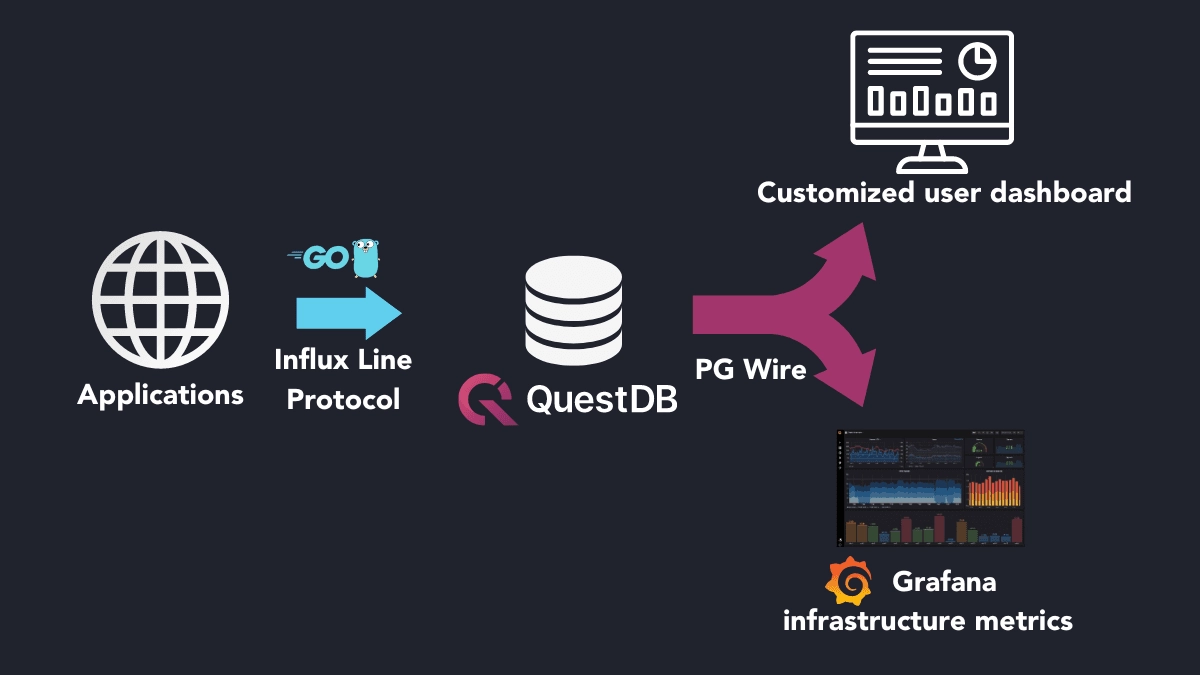
QuestDB architecture for Syndica
Syndica leverages two high-performance QuestDB instances connecting to other applications via the InfluxDB line protocol ("ILP") for ingestion and PGWire for queries. To chart their infrastructure metrics, Syndica plots the results on dashboards via Grafana.
"We have tried almost everything the market offers: ClickHouse, TimescaleDB, PostgreSQL, Amazon Timestream, and InfluxDB. None of them met all of our requirements except QuestDB. ”