Case Study
Toggle switched from InfluxDB to QuestDB
Toggle AI is a SaaS company that uses QuestDB to provide state-of-the-art AI technology to help investors turn Big Data into investment insights.
- Cost Reduction
- Toggle benefited from massive cost reduction, saving significant infrastructure costs.
- Faster Queries
- Toggle observed performance improvements with queries being more than 300x faster.
- Efficient Data Migration
- Toggle easily migrated 600 million data points within a few minutes.

- Avg ingested rows/sec
- 3M+
- Write speed vs InfluxDB
- 10x
- Compression ratio
- 6x
- Cloud up-time
- 99.99999%
Simply grow
Optimizing Data Performance
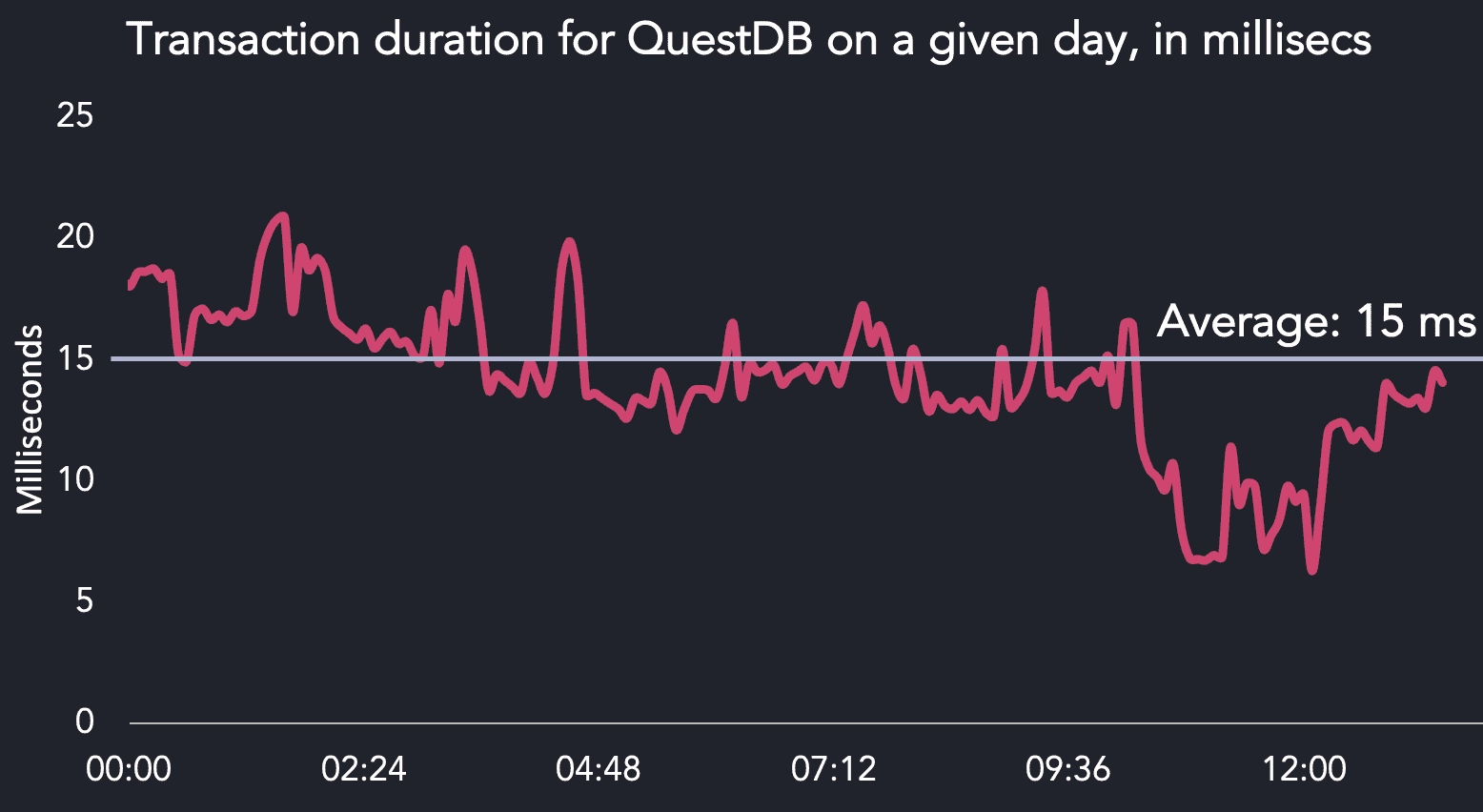
Efficiency even under massive load.
- Cost Savings
- QuestDB helped Toggle significantly reduce costs.
- Improved Performance
- Toggle saw massive performance improvements, including queries being over 300x faster.
- Efficient Migration
- Toggle imported 600 million data points in just minutes.

"The QuestDB team assisted us in all steps along the way. They were proactive in supporting our changeover, helping to debug issues as they arose, and optimize our deployment as we moved things into production."
Armenak Mayalian,
CTO, Toggle
Toggle Migration
QuestDB's performance improvements
Toggle migrated from InfluxDB to QuestDB and observed significant improvements in cost reduction and performance, leading to faster queries and efficient data migration.