Case Study
QuestDB enables machine learning engines that power Yahoo search
Yahoo use QuestDB in an embedded capacity within their machine learning engine. This system intelligently services close to a billion users at a rate of 500k queries per second.
- Massive performance
- Billions of users, massive queries per-second. No problem.
- ML + hyper ingest
- ML engines require the latest, fastest data in their pipelines. QuestDB delivers.
- Fault Tolerance
- Reliable data monitoring at massive scale, where every impression counts.
- Avg ingested rows/sec
- 3M+
- Write speed vs InfluxDB
- 10x
- Compression ratio
- 6x
- Cloud up-time
- 99.99999%
Vespa Machine Learning Engine
Yahoo's Vespa Platform
Yahoo relies on a custom machine learning engine that powers search and recommendation, serving personalized content to hundreds of millions of users in real-time. For high-quality insights out, ML engines need high-quality data in. QuestDB deduplication and out-of-order indexing keep the streams blasting.
- Efficient Metrics
- Monitor metrics for autoscaling decisions in real-time
QuestDB + ML
Intelligent data monitoring at true scale
Yahoo stores and analyze application monitoring metrics in real-time.
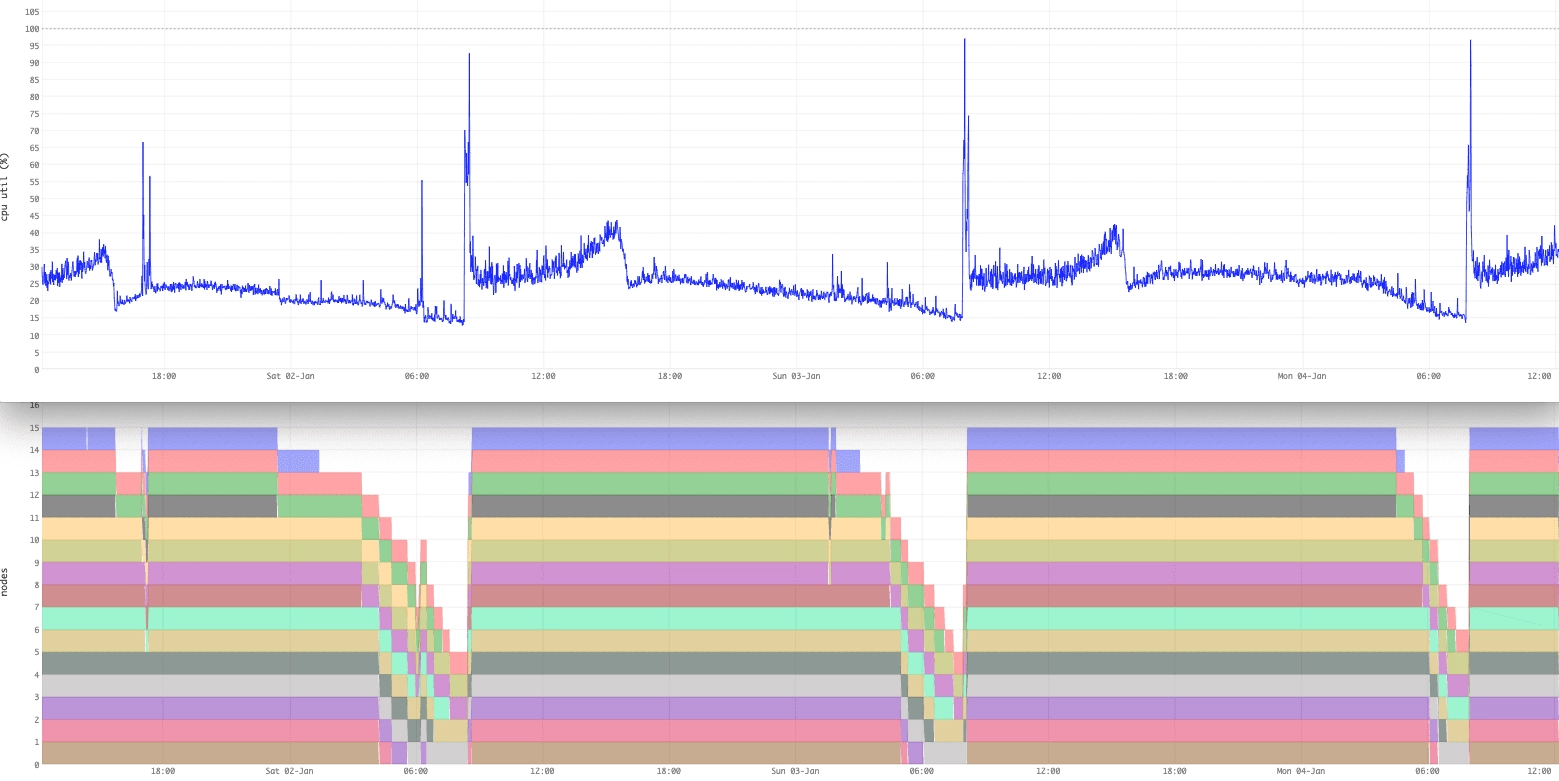
- Cost-effective monitoring
- No external monitoring solutions required for autoscaling decisions
- Embedded Analytics
- Store and analyze application monitoring metrics quickly within the application
- Native Time Series
- QuestDB enables native timeseries support within the ML engine

"We use QuestDB to monitor metrics for autoscaling decisions within our ML engine that provides search, recommendation, and personalization via models and aggregations on continuously changing data."
Advanced Machine Learning
QuestDB in your modern stack
Yahoo leverages QuestDB's high-performance and fault tolerance to power its custom machine learning engine for real-time analytics. Massive ingestion in, with familiar SQL for data-out. Dashboards, queries, it's yours in moments.