Master the time-series database (TSDB)
This article explores all aspects of time-series databases, complete with explanatory images and clear examples.
What's a time-series database?
A time-series database (TSDB) is a database designed to efficiently store and process time-series data. Time-series data is a set of data points associated with a timestamp, typically collected and recorded in chronological order. For example, this data is common in financial market data, sensor readings, and application or infrastructure metrics.
If you appreciate videos, the following explanation of one high performance time-series database will help connect the dots:
Due to the continuous nature of time-series data, traditional relational databases are not optimized to store and query them. Time series databases are purpose-built to handle the unique characteristics of time series data, allowing for fast data ingestion and analysis. We will compare time-series database and relational databases in a later section.
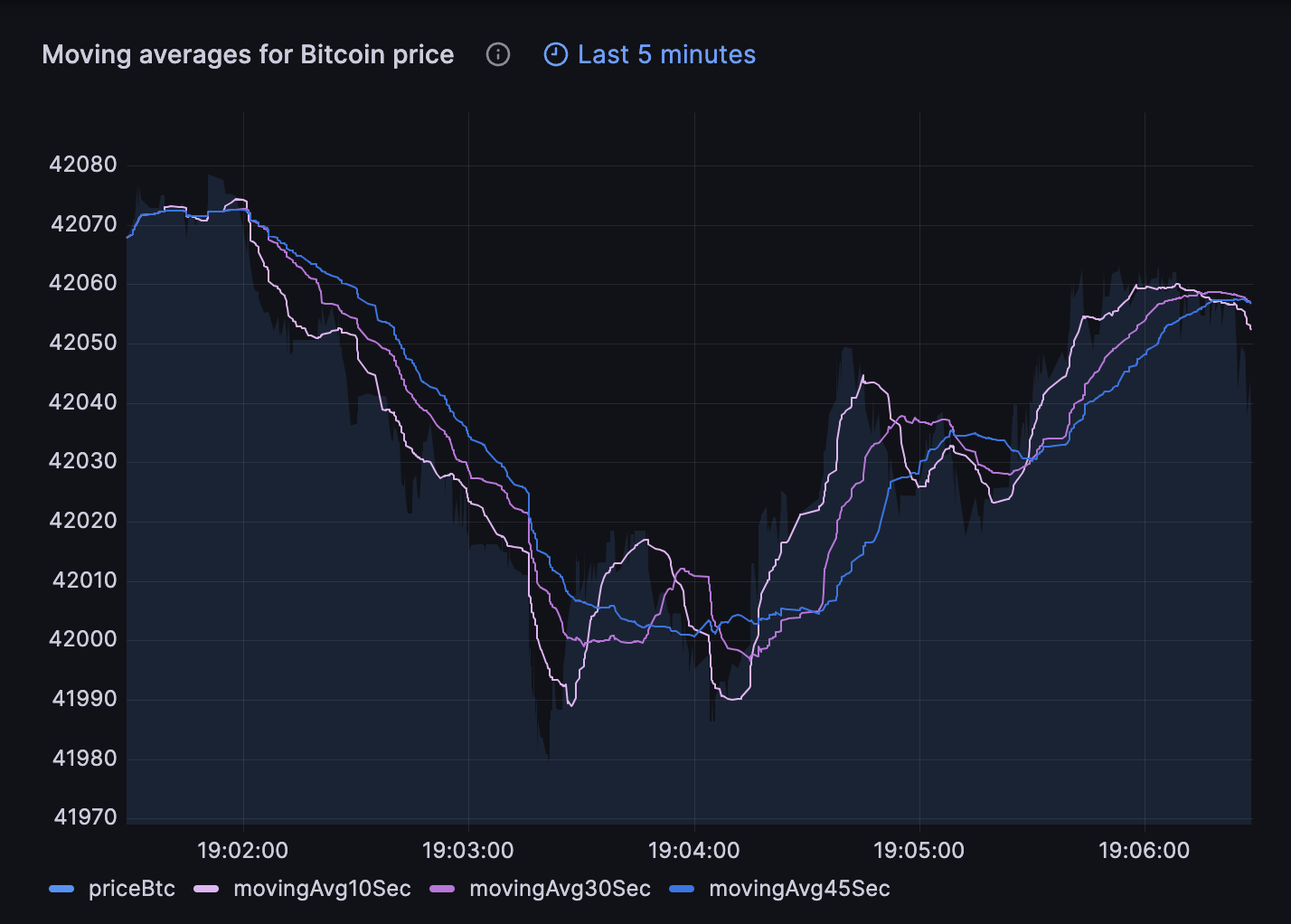
What makes time-series data different?
Time-series data is different from other types of data due to its temporal nature.
It is marked by the following characteristics:
-
The order of the data is important. It captures temporal information such as seasonality and cyclicity
-
The volume of data is very large
-
The flow of data is often uninterrupted within a time window
-
The amount of data may vary widely depending on the time interval
-
The relevance of each data point diminishes over time
-
The data is often down-sampled or aggregated over different time intervals Analyzing time-series data involves identifying trends over time to create forecasting models or detect anomalies. An example query might look at a weekly average sensor reading over the last six months or track the maximum price of a stock per hour over a week. Traditional databases often struggle with these kinds of queries.
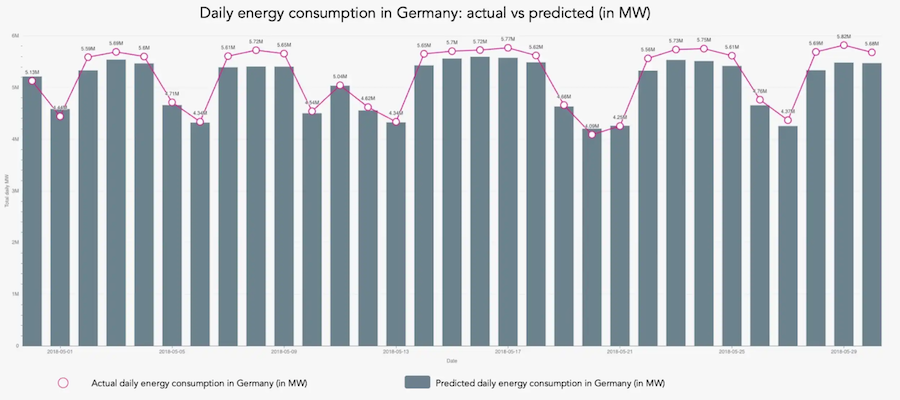
Example of a chart that plots time-series data: Daily energy usage and forecast in Germany, in May 2018.
What's the difference between a time-series database and a relational database?
Time-series databases represent a new wave of data management. Relational databases are the older paradigm, arriving to the public in the 1970s.
In short, the needs at the time were much different. When a row was in a database, it was relatively constant and changes were transactional. For example, the name of the dog and its breed are fairly constant. Whether they are a good or bad dog?
Highly fluid! The state will change.
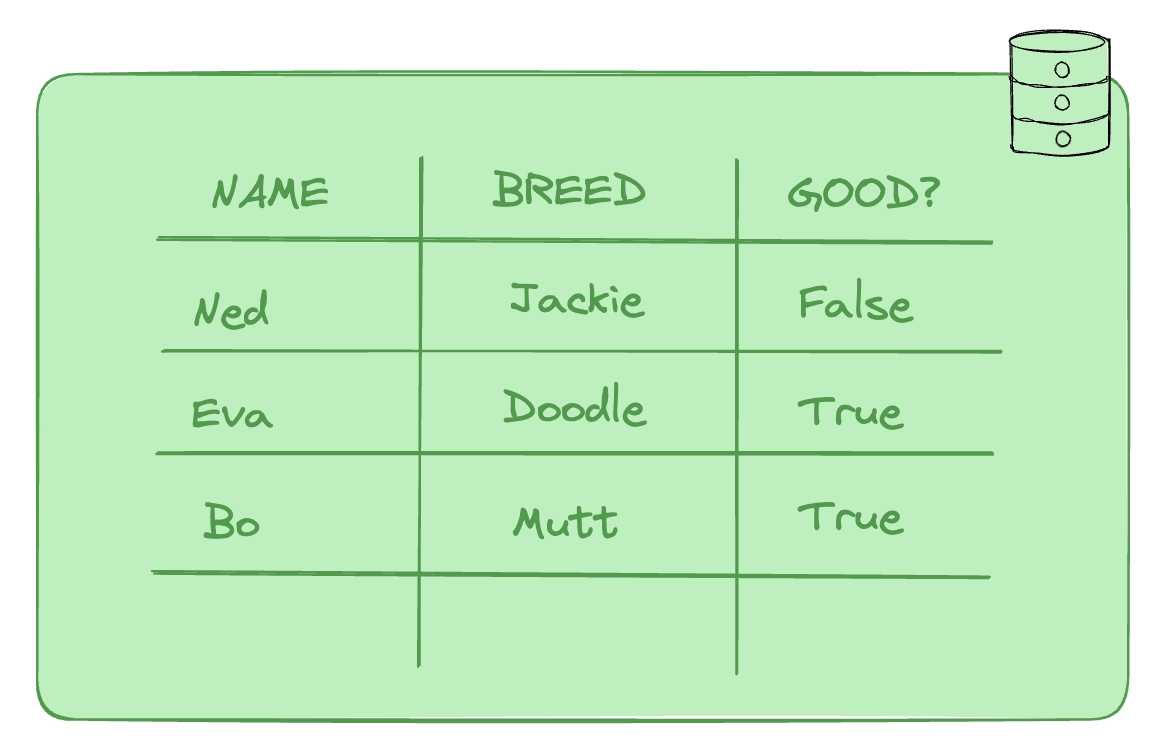
The basis for the relational paradigm was all about improving the integrity of these transactions, so that the "current state" remained accurate and truthful. However, as applications changed, it became more important to track events over a period of time. Enter the time-series database.
Relational Database (RDBMS)
Examples include: MySQL, PostgreSQL, Oracle, SQL Server, and SQLite.
- Stores data in tables.
- Each table has rows and columns, with each row representing a record and each column representing a field.
- Data is often normalized to reduce redundancy and improve data integrity through a set of rules and constraints.
- Supports complex joins, foreign keys, and indexes to efficiently execute queries across multiple tables.
In short: They're ideal for transactional systems where atomicity, consistency, isolation, and durability (ACID) are required to ensure data accuracy and reliability.
Time-Series Database (TSDB)
Examples include: QuestDB, InfluxDB, TimescaleDB (built on PostgreSQL), Prometheus, and KDB+.
- Optimized for storing and querying sequences of data points indexed in time order. Examples are: logs, sensor data, market data and so on.
- Typically, time-series data is stored in time-stamped records within a series, and each series is a sequence of data points belonging to the same metric but recorded over time.
- The databases themselves are designed to handle high write volumes and data retention policies efficiently, often by compressing data and reducing I/O for time-based queries.
In a nutshell: TSDBs are great for analyzing trends over time, forecasting, and detecting anomalies in time-stamped data.
Is a time-series database good at real-time data or data streaming?
Time-series data pulses in real-time. Real-time data capture, real-time data streaming - when time is involved, it quickly accumulates. Real-time processing is crucial for applications that need immediate feedback. Sensors and the data generated in medical equipment or vehicles have life-and-death implications.
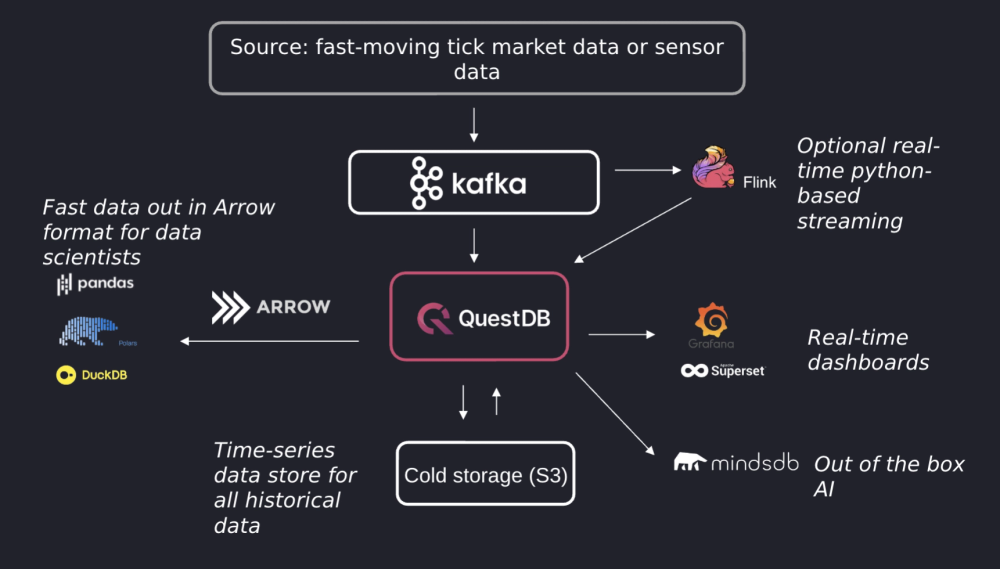
To handle real-time data streaming, technologies like Apache Kafka and Red Panda facilitate streaming data processing, managing high throughput with minimal delay. When processed, the data then needs somehwere to go.
Time-series databases (TSDBs) like InfluxDB and QuestDB are specially optimized to accommodate the intensive write operations and quick retrieval necessary for real-time analysis.
What do you do with time-series data?
There are many things to do once you have collected your time-series data. The first and most common is data visualization. Dashboards can provide tremendous value at-a-glance. They can inform traders as to their portfolio health and rocket engineers determine the safety and quality of their sensors. Or, where all the taxis are clustered in a place like New York:
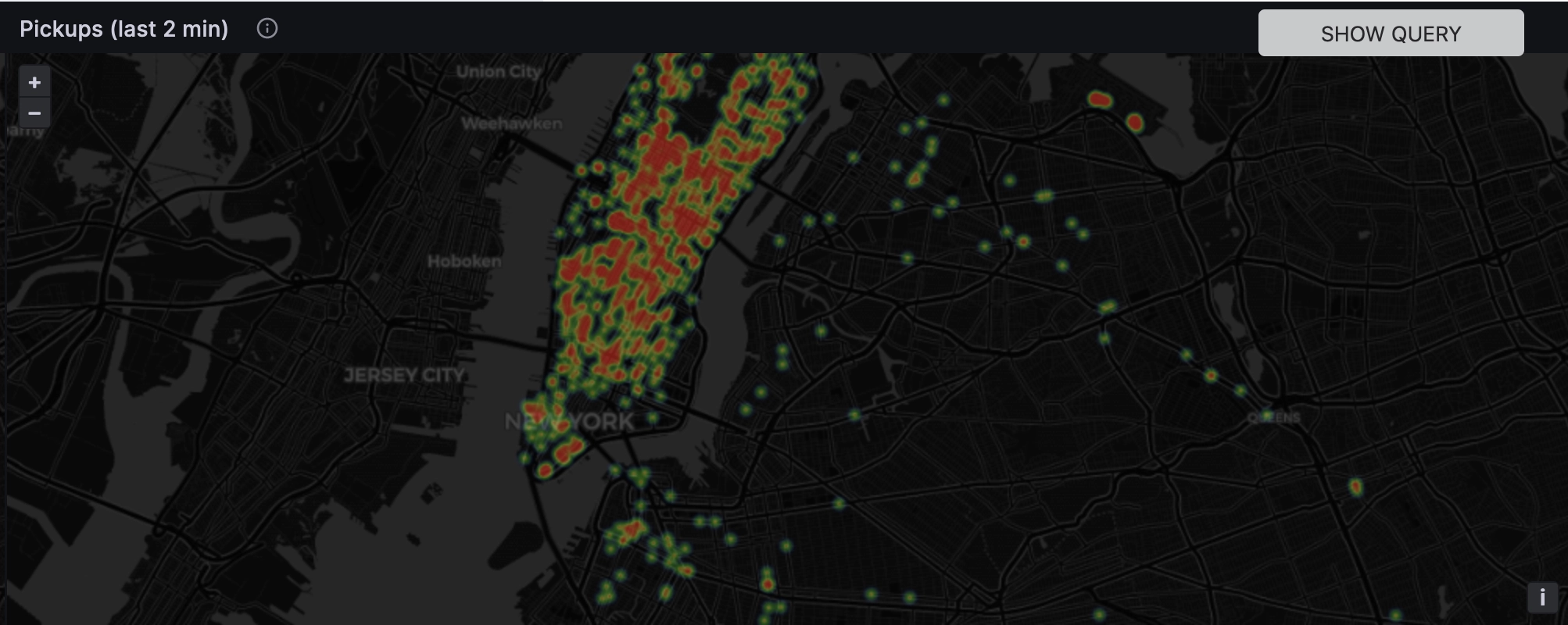
For an example, check out two of our public dashboards:
Beyond data visualization, data may be "downsampled" and refined before heading elsewhere. Maybe it's cleaned and organized prior to being fed into a machine learning model, or into another application pipeline to inform the business logic of upstream applications.
Time-series databases thus support functions like time window analysis and real-time alerts, enabling businesses to monitor operations continuously and respond to anomalies as they occur, enhancing operational efficiency and decision-making processes.
When you can handle the vast flood of data, there is no limit to the time-series data analysis that can be performed upon it.
How do time-series databases deal with time-series data?
Time-series databases make different design choices to optimize for time-series data. First, to capture a large amount of data and respond to them in near real-time, they focus on data ingestion speed over transactional guarantees that SQL databases provide.
Data is usually written in an append-only manner instead of updating or deleting individual records. This allows time-series databases to ingest data fast and expose the most recent data for analysis such as anomaly detection.
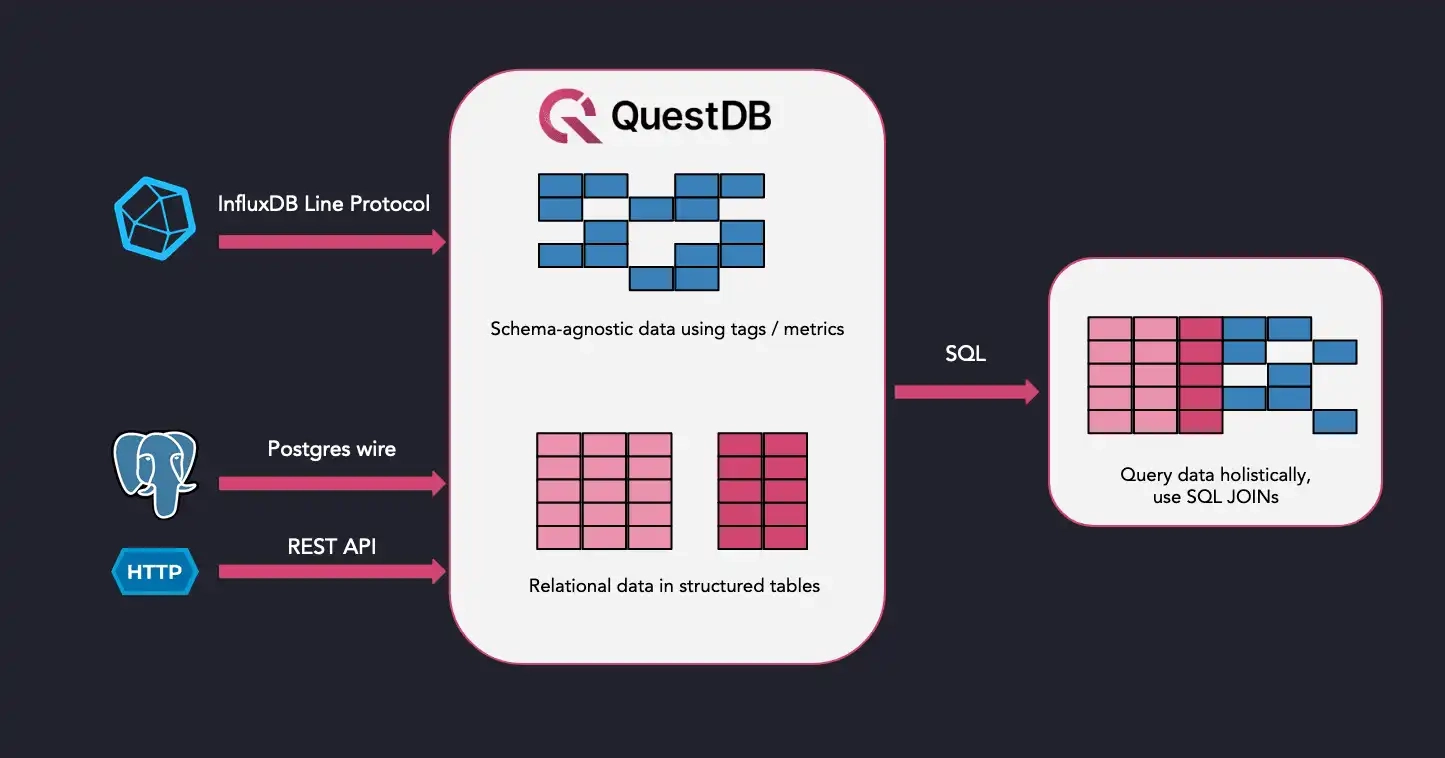
Even though time-series database might use similar protocols for data ingestion, such as the InfluxDB Line Protocol, how time-series data is stored on the database will differ from database-to-database.
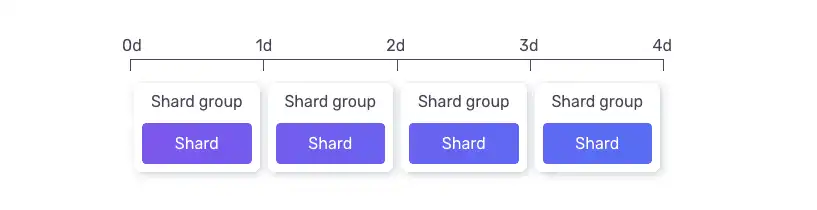
For instance, InfluxDB utilizes shard groups:
QuestDB on the other-hand applies a column-based data storage model:
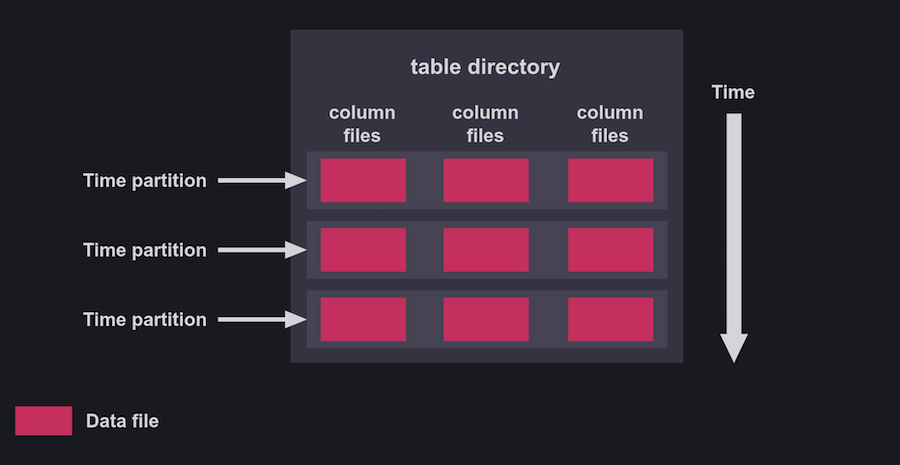
In this case, once ingested, data is then automatically indexed and partitioned by time for fast retrieval of time-based queries. Indexing by time is what time-series database all have in common, despite underlying differences in how this is accomplished.
To support the analysis of time-series data, they also come with built-in functions for downsampling, interpolating, and aggregating time-series data. This is part of data aggregation, an effective way of cleaning data before passing it onwards or performing data analysis. These functions enable efficient temporal analysis, trend analysis and provide general insights from the data.
Data retrieval is accomplished in many cases by SQL. As far as data retrieval methods go, the SQL query syntax is among the most widely used of all programmatic methods.
-- QuestDB offers the IN extension for time-intervalsSELECT * FROM trades WHERE timestamp in '2023'; -- whole yearSELECT * FROM trades WHERE timestamp in '2023-12'; -- whole monthSELECT * FROM trades WHERE timestamp in '2023-12-20'; -- whole day-- The whole day, extending 15s into the next daySELECT * FROM trades WHERE timestamp in '2023-12-20;15s';-- For the past 7 days, 2 seconds before and after midnightSELECT * from trades WHERE timestamp in '2023-09-20T23:59:58;4s;-1d;7'
-- PostgreSQL and Timescale can use the EXTRACT function-- and then filter by parts of a date-- whole yearSELECT * FROM trades WHERE EXTRACT(YEAR FROM timestamp) = 2023;-- whole monthSELECT * FROM trades WHERE EXTRACT(YEAR FROM timestamp) = 2023 ANDEXTRACT(MONTH FROM timestamp) = 12;-- whole daySELECT * FROM trades WHERE EXTRACT(YEAR FROM timestamp) = 2023 ANDEXTRACT(MONTH FROM timestamp) = 12 ANDEXTRACT(DAY FROM timestamp) = 20;-- The whole day, extending 15s into the next daySELECT * FROM tradesWHERE timestamp between '2023-12-20' AND '2023-12-21T00:00:15';-- For the past 7 days, 2 seconds before and after midnightSELECT * FROM tradesWHERE timestamp between '2023-12-14' AND '2023-12-21T00:00:02' AND((EXTRACT(HOUR FROM timestamp)=23 ANDEXTRACT(MINUTE FROM timestamp)=59 ANDEXTRACT(SECOND FROM timestamp)>=58) OR(EXTRACT(HOUR FROM timestamp)=0 ANDEXTRACT(MINUTE FROM timestamp)=0 ANDEXTRACT(SECOND FROM timestamp)<2));
Finally, time-series databases also use data compression and retention techniques to efficiently store and archive older data.
Why are time-series databases popular?
The amount of data being collected is continually growing. And a lot of that data is marked with a timestamp. As a result, time-series data is among the fastest growing data types:
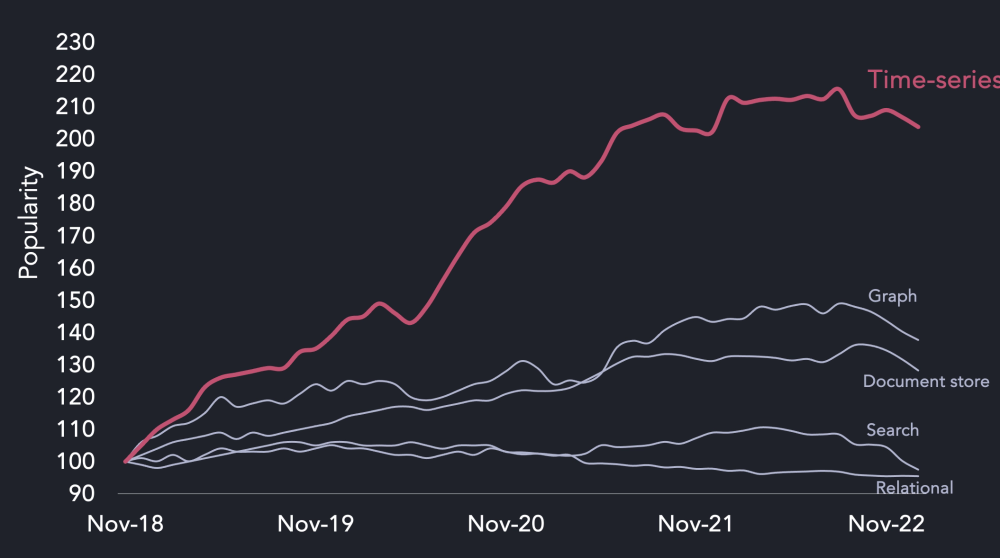
In financial markets, we have pricing information on stocks, commodities, and cryptocurrencies being used by trading desks, fintechs, and traditional firms such as banks more than ever. With the rise of the Internet of Things (IoT), we are now collecting more sensor data for asset tracking, remote monitoring, and personalized health platforms.
Finally, cloud computing has enabled more companies to easily run VMs in the cloud, leading to an explosion of application and operational metrics. While traditional relational or NoSQL databases can also store and process this information, it does not perform well at scale compared to time-series databases.
For a deeper breakdown of the increase, see our blog What is time-series data?
Coupled with the nice built-in functions to analyze this data, it is no secret why time-series databases are growing in popularity in more sectors. Within these sectors, different time-series databases have their own strengths.
Time-series use-cases
Time-series databases cover many time-series data use-cases, many of which are emerging rapidly or expanding in scope and scale. As production is digitized in many aspects, the creation of actionable data bound to time has nearly limitless growth potential.
So much so that a time-series database alone cannot do the work itself. Many tools working together, from queues and event brokers and analytics engines, can contribute alongside a time-series database for effective data management.
IoT and Industrial use cases
A time-series database like QuestDB may excel within:
- asset tracking
- electric batteries monitoring
- smart grids
- supply chain optimization
- production line monitoring
- predictive maintenance
Finance use cases
A time-series database like QuestDB may also excel within:
- financial tick data
- financial metrics
- transaction logs
- blockchain data
Time-series database interoperability across use cases
Within the time-series eco-system and its use cases, interoperability is essential. A time-series database may excel within one category for data ingestion, while a complimentary utility excels within another.
For example, QuestDB is very proficient with IoT and Finance data. However, for infrastructure and application monitoring use cases, Prometheus embeds well into most infrastructure for data collection. As a result, QuestDB integrates with Prometheus instead of trying to directly solve the infrastructure monitoring case.
Application metrics use cases
A tool like Prometheus, in conjunction with a time-series database, will excel at the following.
- user behavior
- e-commerce order tracking
- API monitoring
Infrastructure monitoring use cases
A tool like Prometheus, in conjunction with a time-series database, will also excel at the following.
- server metrics
- network data
- log management
Are there any open source time-series databases?
Yes! There are several open source time-series databases.
Why make an open source time-series databases?
An engineering team may decide to make their database open source so that they can grow a community alongside their tool. Crowdsourcing from a talented community around the world helps keep software quality high and more secure. Public code tends to be written more accessibly, and security issues are in plain sight for all to report and hopefully help address.
As these projects generate more and more success, investors see it as a viable option. As a result, we see data such as the following as sourced by Bessemer Venture Partners:
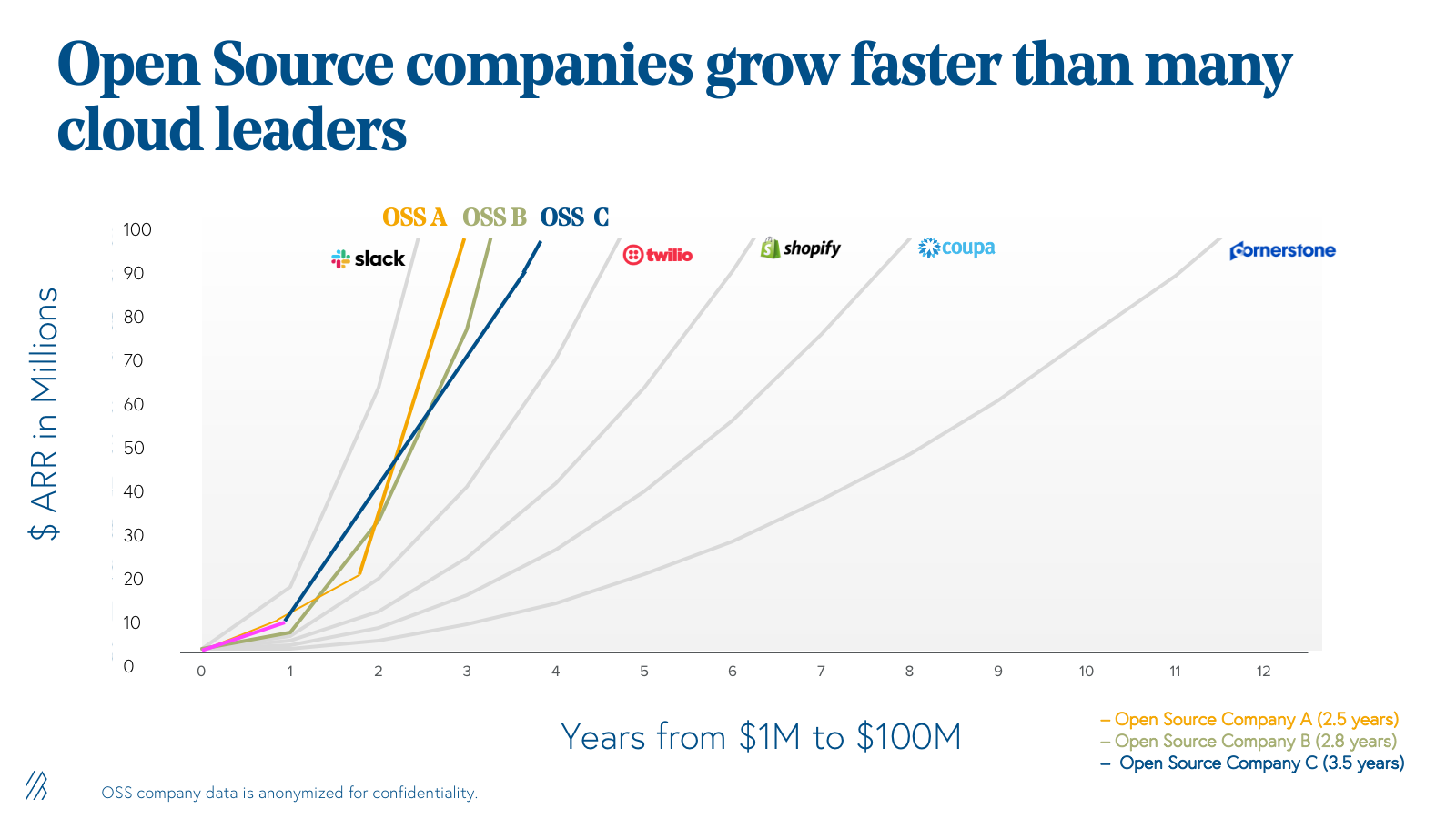
What are some examples of open source time-series databases?
Popular examples include QuestDB, OpenTSDB, Timescale and InfluxDB. Driven by the financial success of popular open source databases like Elasticsearch and MongoDB, we can expect to see more and more engineering teams build their databases and businesses through the open source model.
They are among the growing number of successfull open source companies, also from Bessemer Venture Partners:

Are open source time-series databases free?
Largely yes, but to a point. While many companies do provide their databases as open source, time-series or otherwise, the code may be prohibited by a limited license, such as the Elastic License or the Timescale License, instead of a more flexible license like MIT or Apache 2.0.
Why use a restrictive license?
This prevents other companies from providing their open source software as a service to others by placing a limitation on the usage of the code. This means that monetization of the database is often then in the hands of the builders. Do note that there is a lot of nuance in open source database licenses.
As a result, it's also common for open source databases to have a more restricted version of their software which can differ in features from its open source model. This then allows them to provide a fully open source base version of their product along with a paid version. Before choosing an open source time series database, be sure to check out their licenses and product offerings!