We are excited to announce the release of QuestDB 6.6.1, which brings dynamic commits to optimize ingestion throughput and data freshness for reads. In this blog post, our CTO, Vlad, shares the story driving the creation of the dynamic commits.
QuestDB's data structure and out-of-order data ingestion
Many storage systems adopt a Log-Structured Merge tree at their core. QuestDB differs from them, and the ingested data will always be ordered by timestamp once it is committed to disk. QuestDB 6.0 enabled out-of-order ingestion, for which we introduced a commit lag to optimize ingestion throughput for unordered data. The commit lag includes a time-based buffer and delays the data commit. This way, out-of-order data can be re-ordered on the fly in memory. QuestDB's in-memory reordering is particularly efficient, and avoids heavy copy-on-merge operations, which would be needed otherwise.
As such, we have an implicit trade-off between the ingestion throughput of unordered data and the availability of data for reads. A higher buffer implies a longer time delay for the data to be available for reads, while a short buffer might affect disk write throughput, as we need to reshuffle already committed out-of-order data.
To recap, when treating the incoming data, the commit lag ensures:
- Data is sorted chronologically.
- New data is merged with the existing one.
- A consistent view of the existing data is maintained for concurrent reads.
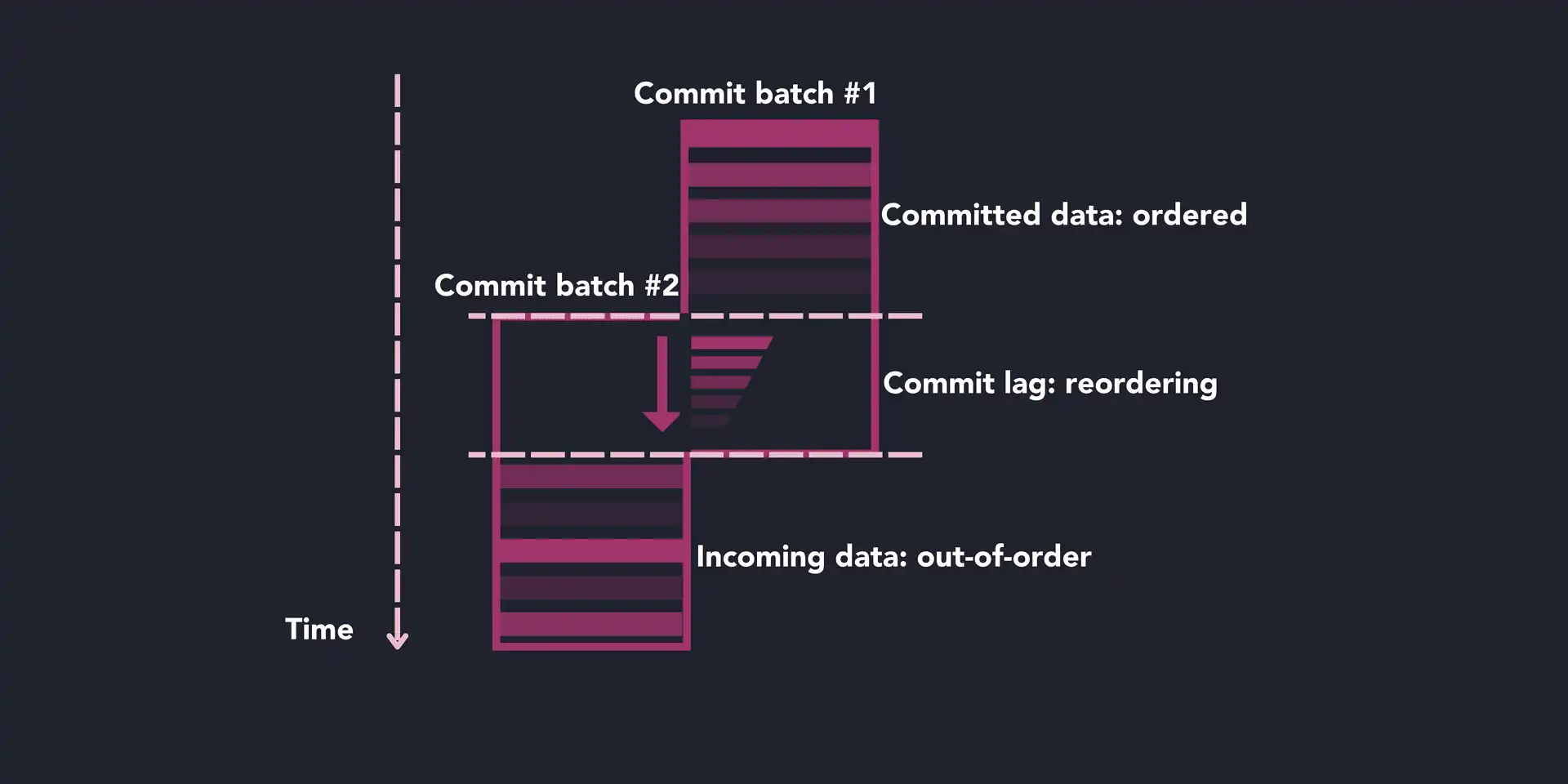
For QuestDB 6.5.5 and earlier versions, users needed to understand the "shape" of their data to adjust the commit lag value, either through server configuration or query settings.
A misconfigured commit lag would lead to user pain and frustration: some of our users would expect data to be available for reads immediately, but the default configuration was out of whack. For heavy out-of-order ingestion patterns, the default commit lag would lead to too many copy-on-merge operations and significantly slow down the database. And this was where the story started.
Community-driven development
A couple of weeks ago, I was working on a massive WAL (Write Ahead Log) PR, when Nic, our CEO, sent me a thread of messages:
Nic: FYI I asked Javier and Imre to connect and look at this commit lag together. Our default settings are not good enough…Someone in the community just asked me if the best we can do is ingestion with a 5-minute delay. These default settings give the wrong impression that we cannot process data in real time. Let's brainstorm.
Me: They can reduce the commit lag, why would not they do that? They can set it to 0?
Nic: They don't know that the commit lag is configurable, and this leaves a bad impression on new users.
This feedback was too important to ignore, so I caught up with our Core Engineer, Imre Aranyosi, and DevRel, Javier Ramirez. It turned out that Javier had produced a demo project in Go, sending data to QuestDB Cloud in small batches - approximately 10k rows every 50 ms. When querying data from this project, Javier could not see new data immediately. Similarly, data visibility is one of the most frequently asked questions on QuestDB Slack as well as on Stackoverflow. To our users, it wasn't clear which configuration parameters to set and where to show this data, either. We had to investigate this problem further.
Imre and I began exploring and we soon realized that it was due to the commit lag setting that data were not readily available. To increase data freshness, we had to commit more often and decouple the commit frequency from the commit lag value. We wanted to improve our user experience, without complicating the database configuration. So we went back to the whiteboard and considered the commit lag anew. Its optimal size depended on the shape of the incoming data, which was not static. This meant that the commit lag size had to be dynamic! We needed to predict the commit lag size and resize the value dynamically.
Dynamic commits
This is what we eventually implemented for QuestDB 6.6.1: to predict the correct commit lag value, QuestDB takes the maximum of the latest 4 overlap values with a multiplication factor - a bigger commit lag is better than a smaller one. This prediction is updated every second. The commit lag value shrinks down to 0 when data stops overlapping (no out-of-order data) and inflates rapidly in response to out-of-order demands, depending on the data shape prediction.
Javier has upgraded his demo project to QuestDB 6.6.1 and now data is visible instantly. Our DevRel is happy, and so are our users: it does not matter the data ingestion method and the scope of the data, QuestDB automatically adjusts settings and delivers the optimal data immediacy.
In short, users do not need to do anything to benefit from the optimal ingestion rate and data availability for read operations. Check us out on GitHub for more details.