Comparing InfluxDB, TimescaleDB, and QuestDB Time-Series Databases
InfluxDB, TimescaleDB and QuestDB offer the cutting edge of time-series database solutions. But what is at the root of the sudden interest in time-series databases? And how do these compelling offerings compare?
Among database types, none has grown more than time-series:
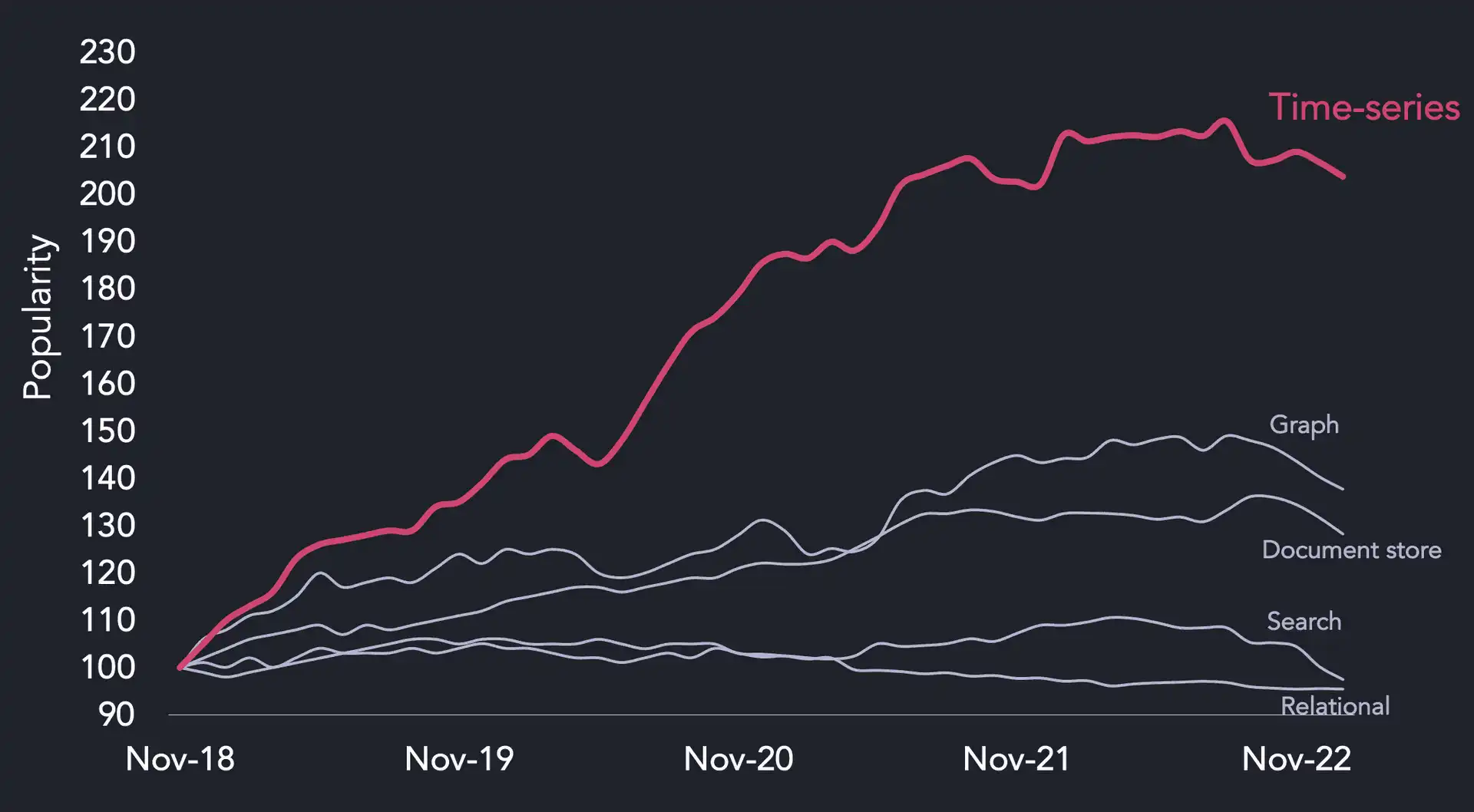
And now let's get to the comparison.
Why use a time-series database?
Time-series databases (TSDB) are databases optimized to ingest, process, and store timestamped data. Such data may include metrics from servers and applications, readings from IoT sensors, user interactions on a website or an app, or trading activity on financial markets.
The following properties often characterize time-series workloads:
- Each data point includes a timestamp which is used to index, aggregate, and sample. The data can also be multi-dimensional and correlated.
- High write speed (ingestion) is preferred to better capture data at high frequencies.
- Summarized views of the data (e.g., downsampled or aggregated view, trend lines) may provide more insight than a single data point. For example, given network unreliability or outliers in sensor readings, we may set alerts when an average value over time exceeds a threshold.
- Analyzing the data usually requires accessing it over some window of time (e.g., give me the click rate data over the past week).
While conventional databases can also handle time-series data to a certain extent, TSDBs are designed with the above properties to handle data ingestion, storage, and aggregation over time more efficiently. So as the demand for time-series data continues to explode on the heels of cloud computing, IoT, financial market data, and machine learning, how should architects go about choosing a time-series database? Which offers the most promise?
InfluxDB
Released in 2013, InfluxDB is the market leader in the TSDB space, supplanting Graphite and OpenTSDB which came before it. As with many OSS database companies, InfluxDB is licensed with the MIT License for a single node, with paid-plans available for InfluxDB Cloud and InfluxDB enterprise that provide clustering and other production-ready features.
Previously, the InfluxDB Platform consisted of the TICK stack: Telegraf (agent for collecting and reporting metrics), InfluxDB (the database engine), Chronograf (web interface to InfluxDB), and Kapacitor (background processing).
Since version 2.x, InfluxDB is now installed as a single binary that bundles the database, the UI, and the background processor. If you want to use Telegraf, it is still supported as a separate binary.
This article was updated in March 2023 from its 2021 publish date to acknowledge that InfluxDB now offers additional versions with updated query engines and capabilities. The following refers to Open Source InfluxDB 2.6.
To understand how InfluxDB works, we need to grasp the following key concepts:
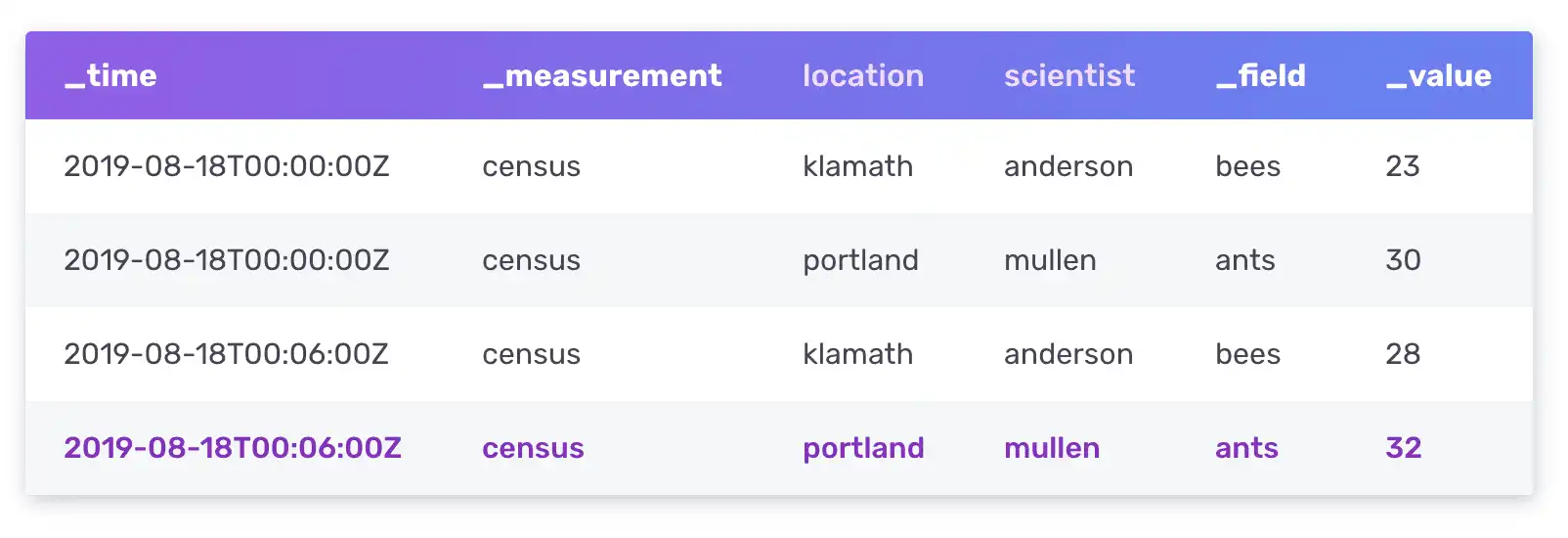
- Data model (tagset model): Besides the timestamp field, each data element
consists of various tags (optional, indexed metadata fields), fields (key and
value), and measurements (container for tags, fields, and timestamps). The
example below takes census data from bees and ants, collected in Klamath and
Portland by scientists Anderson and Mullen. Here
locationandscientistare tags, falling under the census measurement with field/value pair forbeesandants.
-
Schemaless Design: InfluxDB does not enforce a schema before ingesting data. Instead, the schema is inferred automatically from the tags and fields sent over the line protocol. This grants more flexibility when writing applications. In any case, it is possible to enforce schemas for specific buckets if needed.
-
Data storage (TSM & TSI): data points are stored in time-structured merge tree (TSM) and time series index (TSI) files. TSM can be thought of as an LSM tree with a Write-Ahead Log (WAL) and read-only files, similar to SSTables that are sorted and compressed.
The caveat within this model is that high cardinality data has decreased performance. As evidence, in InfluxDB OSS 2.6, the schema design documentation offers guidance to prevent high series cardinality.
-
Query languages: Earlier in its lifecycle, InfluxDB supported only SQL-like query language InfluxQL. In 2018, InfluxDB announced Flux, a domain-specific functional language which was to become the new recommended query language.
InfluxDB's decision to create its own custom functional data scripting language (Flux) presents another layer of complexity to mastering the ecosystem. Implementing Flux requires effort, especially if you're only looking for simple SQL queries or not interested in learning another new language.
Overall, InfluxDB is a solid choice when time-series data fits nicely within a preferred cardinality-limited schema. Thus their main use cases gear towards infrastructure/application monitoring. However, as the market leader in this space, InfluxDB also integrates with popular data sources.
- Pros: schemaless ingestion, huge community, integrations with popular tools
- Cons: low performance with high-cardinality datasets, multiple versions with differing database engines, supported languages, and features. Need to learn Flux.
TimescaleDB
Whereas InfluxDB opted to build a new database and custom language from scratch, on the other end of the spectrum is TimescaleDB. It is a time-series focused PostgreSQL extension with cloud-managed and self-managed options.
PostgreSQL compatibility is both TimescaleDB's biggest selling point and its biggest drawback. It supports SQL features (e.g., joins, secondary and partial indexes) as well as popular extensions like PostGIS. But while it improves upon the performance of standard PostreSQL for time-series use cases, its claims are relative to that of PostgreSQL's native performance and not a purpose built time-series database.
TimescaleDB is built upon the traditional row-based architecture of PostgreSQL, as opposed to the modernized column-based architecture seen in DuckDB, InfluxDB Cloud and QuestDB. Row-based architecture performs well within Online Transaction Processing (OLTP) where use cases see a large number of transactional inserts, updates and deletes by many users.
By comparison, columnar models excel within Online Analytical Processing (OLAP) cases, which require much higher ingestion speeds and more complex queries, exemplified by the analysis of market or systems data.
TimescaleDB has improved upon the OLTP foundation of PostreSQL with the following features:
-
Hypertables: Hypertables sit alongside standard PostgreSQL tables to better handle time-series data. They require data to be partitioned into configurable chunks based on a time column. Chunks need to be tuned for optimal performance.
-
Continuous Aggregation: TimescaleDB also supports continuous aggregation of data to make computing key metrics like hourly average, minimum, and maximum values fast. Behind the scenes, the data is stored using PostgreSQL materialized views; additional storage is needed as a trade-off for faster queries.
-
Data Retention: Large deletes are a costly operation in traditional relational databases. However, since TimescaleDB stores data in chunks, it provides a
drop_chunksfeature to quickly drop old data without the same overhead. Since the relevance of old data diminishes over time, TimescaleDB can be used to move older data to save disk space.
Overall, TimescaleDB is a good fit for teams looking for a performance boost over PostgreSQL for time-series data without heavy refactoring to migrate off their existing SQL databases. Even though TimescaleDB is still relatively new (first released in 2017), the decision to build on top of PostgreSQL has boosted its adoption numbers to reach the top 5 TSDBs.
However, besides performance, another drawback is the lack of a streaming ingestion protocol like the InfluxDB Line Protocol. This makes ingestion less flexible and less focused on performance as a result.
- Pros: PostgreSQL-compatibility, scales better than InfluxDB with data cardinality, various deployment models available.
- Cons: enforced schema that requires configuration, ingest rate capabilities limited by PostgreSQL, extra storage needed for continuous aggregations, lack of streaming ingestion protocol. Parts of the code licensed under a proprietary License ("TSL").
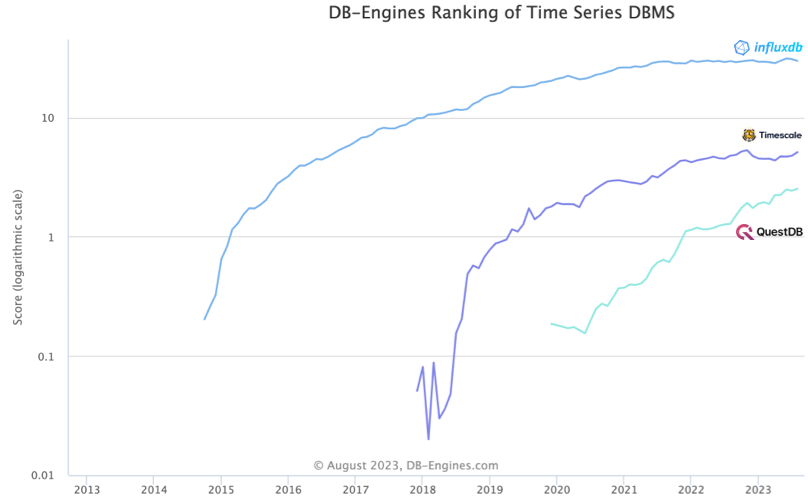
QuestDB
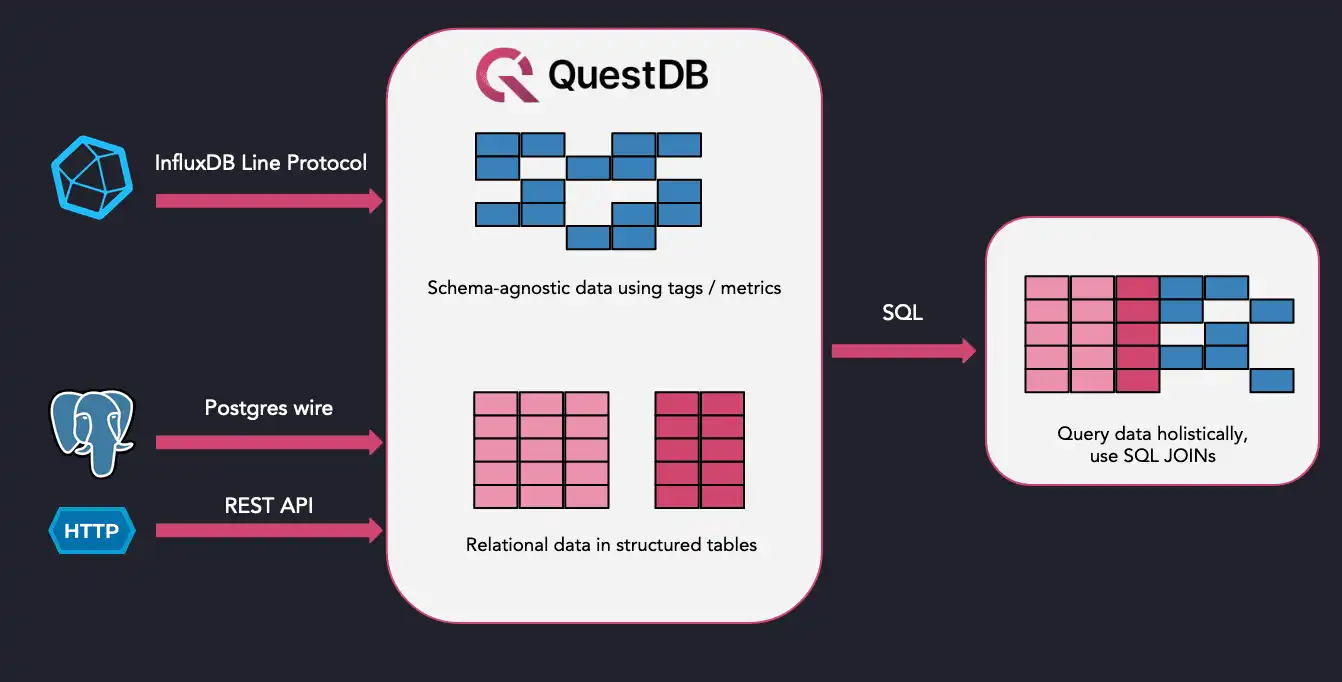
QuestDB is an open-source TSDB written in low-latency Java, C++, and Rust. It is the fastest growing database within DB-Engine's Time Series DBMS rankings. Alongside the Apache 2.0 licensed open-source project, it also offers a fully managed Cloud offering and a commercial Enterprise version. For those looking to take advantage of the flexibility of the InfluxDB line protocol and the familiarity of PostgreSQL, QuestDB may satisfy both requirements without sacrificing performance.
At the heart of QuestDB is a highly optimized column-based storage model. Data are sorted by time natively and stored in time partitions, which are append-only and versioned. QuestDB only lifts the latest version of the partition in memory for any given time-based query. As such, queries do not slow down as more data is being ingested.
By building the database engine from scratch, the QuestDB team focused on three things:
-
Performance: Solving the ingestion bottleneck with high throughput ingestion, for datasets of all sizes. QuestDB addresses one of the pain points of InfluxDB, with its ability to handle high cardinality datasets. To speed up queries, QuestDB leverages modern hardware with SIMD instructions, aggregating multiple rows simultaneously. The engineering team built a JIT compiler designed to parallelize query filters during execution. QuestDB stores data in time partitions; this reduces the volume of data which has to fit in memory for reads. Finally, the database is column based and can handle a high degree of parallelism, slicing and processing columns in parallel by all available threads.
-
Compatibility: QuestDB supports InfluxDB line protocol, PostgreSQL wire, REST API and CSV upload to ingest data. Users accustomed to other time-series databases can easily port over their existing applications without a significant rewrite, and users can choose amongst a set of ingestion protocols depending on their use cases. There are client libraries in multiple languages for the InfluxDB Line Protocol.
-
Querying via SQL: Despite supporting multiple ingestion mechanisms, QuestDB uses SQL as the query language, so there's no need to learn a domain-specific language like Flux. Additionally, there are time-series-specific SQL extensions to handle time-series data with ease.
The other interesting component of QuestDB is support for both InfluxDB Line Protocol and PostgreSQL wire for ingestion. For existing InfluxDB users, you can configure Telegraf to point to QuestDB's address and port. PostgreSQL users can leverage their client libraries or JDBC to write data into QuestDB. Regardless of the ingestion method, data can be queried using standard SQL with notable exceptions listed on the API reference page.
When it comes to third party integrations, QuestDB integrates with some of the most popular tools (e.g., PostgreSQL, Grafana, Pandas, Apache Kafka, Apache Flink, MindsDB, Telegraf, Kubernetes...). There are more integrations underway, such as more dashboards / BI tools.
QuestDB is the newest time-series database and still lacks a degree of expressiveness for queries. However, the team recently released Window functions to fill the biggest gap. Integrations remain on the team's roadmap.
- Pros: fast ingestion, better performance using fewer resources, support for both InfluxDB protocol and PostgreSQL wire, querying via standard SQL, optimized queries with SIMD, open source and fully managed QuestDB versions available.
- Cons: smaller community, reduced number of available integrations
Performance benchmarks between InfluxDB, TimescaleDB and QuestDB
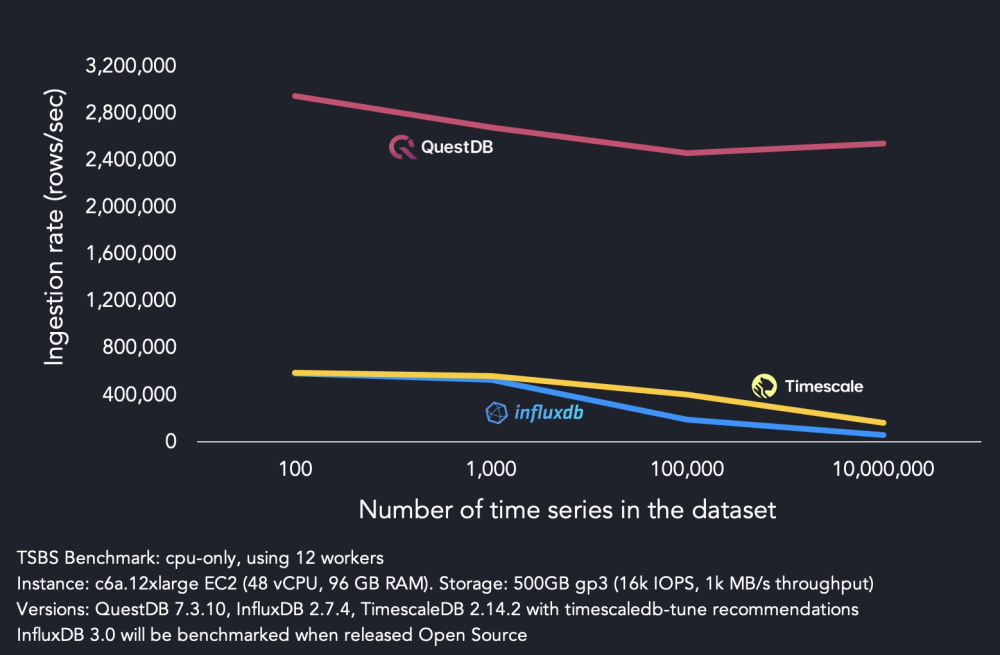
In terms of performance, QuestDB
recently posted some benchmark results
with an ingestion rate reaching 4.3 million rows per second. This was computed
through the TSBS benchmark, currently
maintained by TimescaleDB, selecting the cpu-only use case.
The chosen instance had 48 CPUs and 96GB of RAM, with a fast SSD disk (NVMe). Fast disks allow to better cope with writes that are I/O bound - in this case when a lot of out of order data is being ingested concurrently. For most use cases, slower disks such as AWS EBS volumes are enough to extract sufficient performance:
Queries are multi-threaded and vectorized with SIMD, which shows in the query execution time. Although time-series databases are optimized for time-based queries, established benchmarks cast a net wider. They include a range of "OLAP" queries and several time-based queries. This holds true for the Clickbench benchmark where both QuestDB and TimescaleDB feature well, unlike InfluxDB.
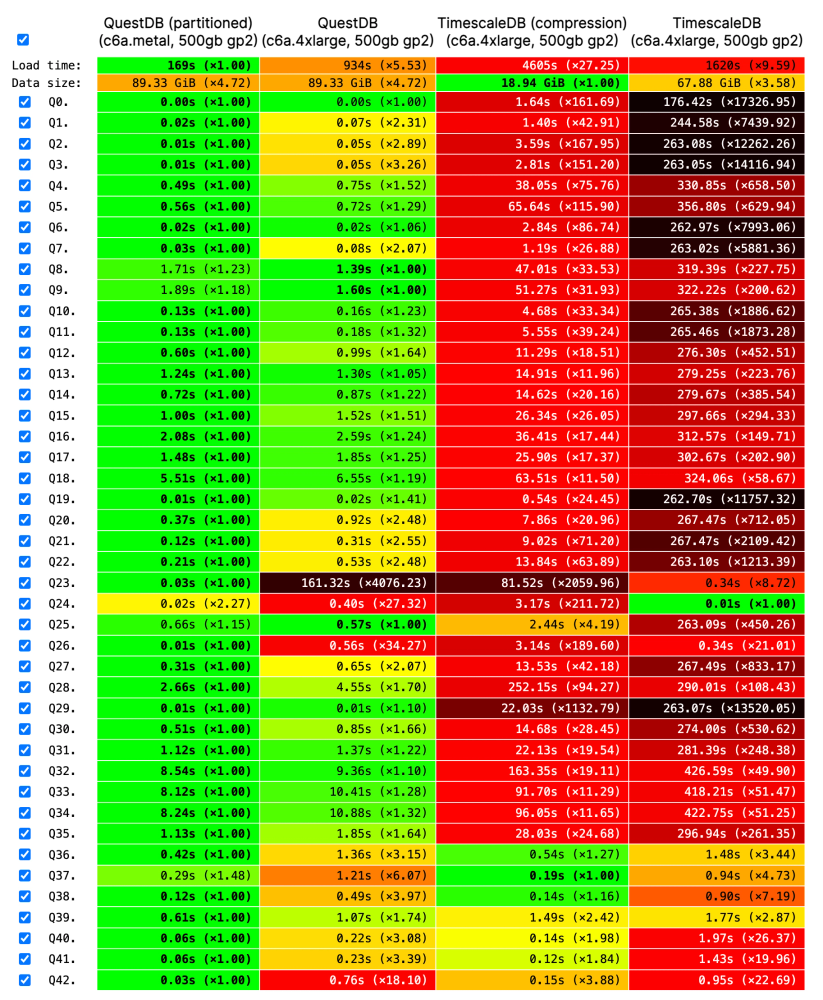
The most recent benchmark includes both QuestDB partitioned and non-partitioned.
Time-based partitions are necessary for performant time-based queries such as
query n.24 and n.26, ordered by EventTime. Regarding Timescale, there is the
open-source implementation without compression and the version with compression
under the Timescale License.
Across most queries, QuestDB outperforms Timescale by a factor of 10x up to 150x:
Conclusion
As the demand for time-series data continues to grow, time-series specialized databases will see massive adoption and fierce competition. Besides the three open-source TSDBs covered in this article, there are also public cloud offerings from AWS (AWS Timestream) and Azure (Azure Series Insights).
As with all databases, choosing the "perfect" time-series database depends primarily on your business requirements, data model, and use case. InfluxDB works well if your data fits the Tagset model with a rich ecosystem of integrations readily available.
However, performance degrades with high cardinality data, and Flux is a new language to be learned. TimescaleDB is a natural fit for existing PostgreSQL users, but it is a row-oriented database, thus less optimized for time-series and analytical workloads and is crushed in many performance metrics.
Finally, if performance is the primary concern, QuestDB is a popular and developer-friendly database that is growing rapidly. On the flip side, it's less mature than InfluxDB and TimescaleDB.