Since its initial release in 2013, InfluxDB has held a prominent position in time-series. As the number one ranked time-series database on DB-Engines, it has gained traction across observability, application monitoring, and Internet of Things use cases. But recent strategic choices and technical caveats have left its userbase seeking an alternative.
In this article, we will explore five compelling InfluxDB alternatives that your team might consider if they're eager to migrate off of InfluxDB.
InfluxDB, history in brief
Why are teams eager to leave InfluxDB? What sort of caveats do its users experience? In brief, volumes of time-series data have risen sharply and new use cases have since emerged. The InfluxDB team responded by creating new major versions to handle new requirements for performance and efficiency. And it did so more than once!
In fact, in the last ten years, InfluxDB has undergone several major architectural and technical rewrites. These iterations have seen changes to the underlying language from Golang to Rust, and also changes to the querying language, from SQL-like InfluxQL to Flux and back to InfluxQL, and now SQL. Not to mention changes are often spread across several cloud-specific offerings, including serverless, single-tenant, and multi-tenant solutions.
Unfortunately, all of this change has left many InfluxDB users without a strong solution for their ever-advancing use cases. Some are left in a legacy product (InfluxDB v1.x or v2.x) and others may need to choose whether to undergo a major technical overhaul to adopt the latest version, which is promised to be open source but is not yet.
It's a lot to follow. There's a constant stream of flux, with roadmap updates containing passages such as this one:

It's tough to pin down just what is heading where, which supports what, and what is still supported. It also seems to be headed towards cloud nativity for the full range of desirable features, which has major cost implications when you consider that cardinality and general usage are granular with various service quotas.
Broadening the range of offerings has also left InfluxDB vulnerable to the deepening state of the art. As such, they have fallen well behind the performance curve. High cardinality data in particular, a term used to describe unique values in a given column, is a major pain point for InfluxDB ingestion throughput. This is especially true for use cases like trading infrastructure, where high cardinality data is common. Similarily, wide tables with many columns also pose a major challenge, as seen in sophisticated sensor arrays.
Thankfully in 2024, the ecosystem for time-series data is now more robust and diverse, offering users powerful - and often much more simple - options depending on their use case. In this article, we’ll look at some InfluxDB alternatives to consider, whether you are just starting out or looking to migrate off InfluxDB.
Prometheus, the observability powerhouse
If your main use case is capturing observability data such as server metrics, then Prometheus is by far the most popular option in today's market. Originally developed by SoundCloud, Prometheus was one of the first projects to be accepted into the Cloud Native Computing Foundation (CNCF). It remains one of the most used and supported CNCF projects along with Kubernetes.
Prometheus is primarily a monitoring software that efficiently collects, stores, and analyzes metric data with native alerting capabilities built-in. It typically scrapes a HTTP endpoint that exposes Prometheus metrics and aggregates them for analysis. These metrics often include counters, gauges, histograms, and summaries. Prometheus' metric format has since then been absorbed into the OpenMetrics and OpenTelemetry projects to create a standard for collecting observability data.
Although Prometheus can be used as a standalone product, it is often deployed with other popular open-source observability tools such as Grafana for visualization and PagerDuty for alert notification and incident management. Over the years, Prometheus has built up a rich ecosystem of observability solutions and has solidified itself as the de facto database for observability use cases, especially in cloud-native environments.
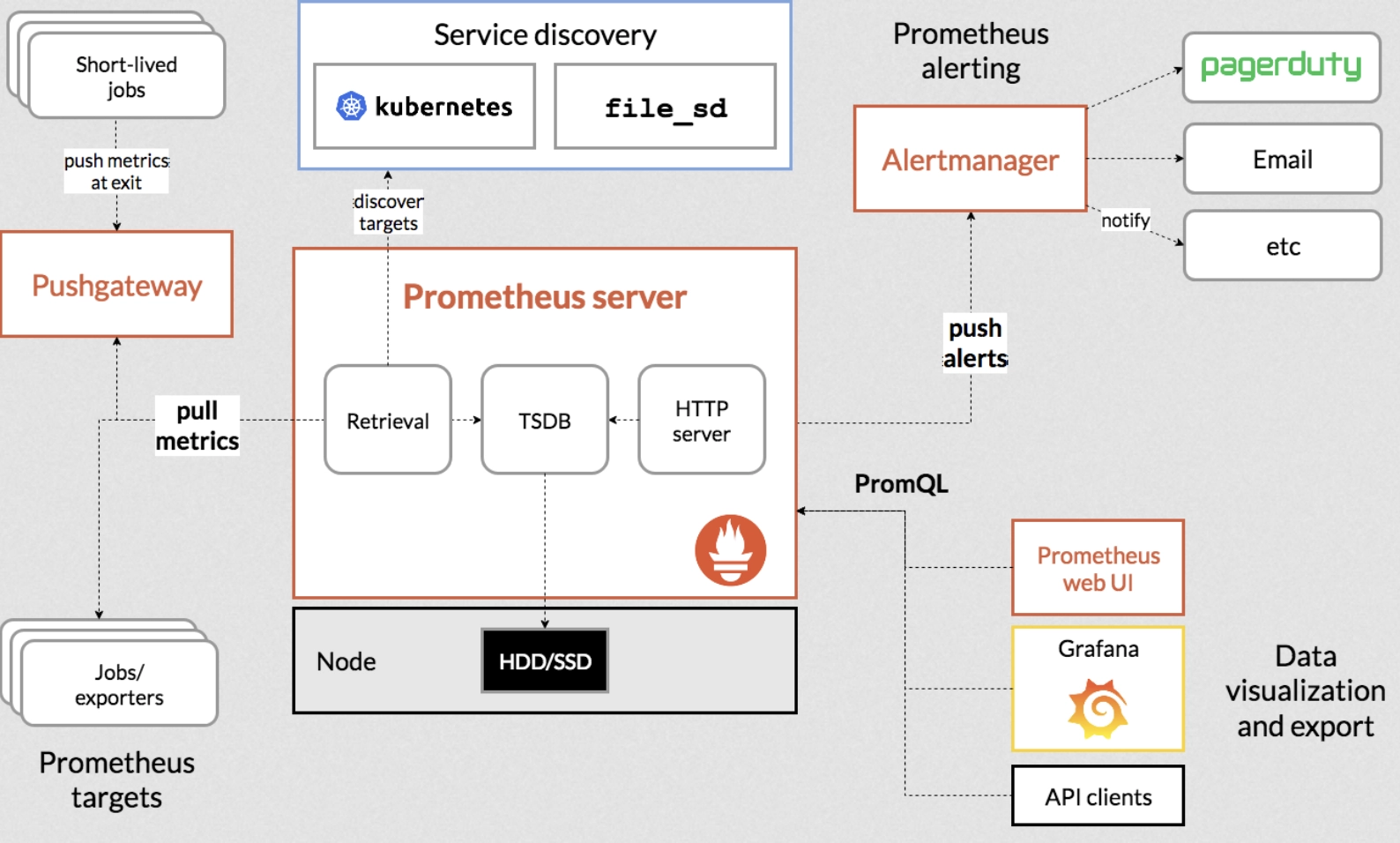
While Prometheus is a strong fit for a real-time monitoring or as part of a wider observability stack, it’s important to note that Prometheus is not a true time-series database like others in this article. It contains a time-series database under-the-hood, supported by components specifically designed for observability. With that said, there are trade offs:
-
Prometheus has a specific data model to ingest metrics in a standard format
-
Prometheus needs to be paired with another solution to handle long-term storage like Thanos or Grafana Mimir
-
It uses its own query language PromQL instead of standard SQL
To go a little deeper, as written in the blog Prometheus Is Not a TSDB, author Ivan Velichko explains:
Aiming for results that would be reasonable for a pure TSDB apparently may be way too expensive in a monitoring context. Prometheus, as a metric collection system, is tailored for monitoring purposes from day one. It does provide good collection, storage, and query performance. But it may sacrifice the data precision (scraping metrics every 10-30 seconds), or completeness (tolerating missing scrapes with a 5m long lookback delta), or extrapolate your latency distribution instead of keeping the actual measurements (that's how histogram_quantile() actually works).
So if observability is what you're after, consider Prometheus.
kdb+, the sticky finance classic
kdb+ is a proprietary time-series database developed by KX that is popular in the financial sector, especially at high-frequency trading firms. As a columnar database with in-memory capabilities, it is optimized for handling large volumes of financial data with low latency requirements. For large banks or hedge funds with sophisticated trading infrastructure, kdb+ is often used to store tick market data. Its query language q is also great at aggregating and analyzing streaming data.
If your use case involves financial data, there is a high chance that kdb+ is shortlisted as the database of choice. Outside of the financial sector, kdb+ is often used for use cases where there is demand for fast in-memory processing or vectorized operations, such as network monitoring or radar processing.
However, just because you are working with financial data does not mean kdb+ is always the right choice. First of all, kdb+ is a proprietary database compared to open-source solutions like InfluxDB and other choices on this list.
This may lead to higher initial costs and the eventual need for consultants to maintain the software and get support as needed. By contrast, open source ecosystems often see developers get much further "on their own" before needing to summon an expert. Furthermore, these deployments are notorious for their complexity and for their rigid lock-in.
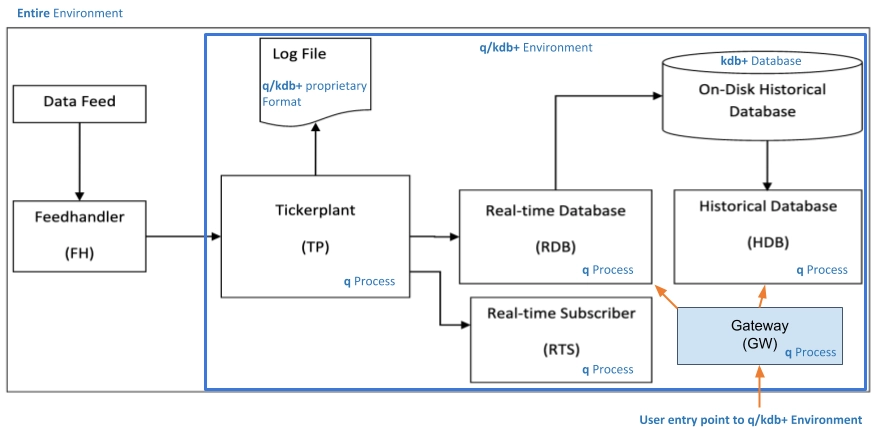
The overall architecture diagram highlights the heavy reliance on the proprietary language q and the proprietary log format. This leads to vendor lock-in and a higher, context specific learning curve. Compared to a choice which leverages a more common query language like SQL and uses open data formats, both initial time-to-value and overall cost of ownership can be significant.
Keep these in mind as kdb+ might be more difficult to implement or migrate to from InfluxDB compared to other alternatives.
TimescaleDB and KairosDB, the "built atop" databases
Next we will look at two more general time-series databases: TimescaleDB and KairosDB. While general, both are time-series databases that are built on top of other databases, with TimescaleDB built atop PostgreSQL and KairosDB built atop Apache Cassandra. This brings about interesting advantages and limitations as each of these databases are inevitably tied to the underlying infrastructure and architecture of their hosts.
TimescaleDB & PostgreSQL
As the most popular database, PostgreSQL already has a lot of client libraries, monitoring tools, and expertise built into its ecosystem. TimescaleDB is an open-source PostgreSQL extension with additional time-series related SQL functions and time-series specific "hypertable" table architecture. This is an advantage, as both users interacting with the database and the maintainers running the database don’t have to learn everything from scratch.
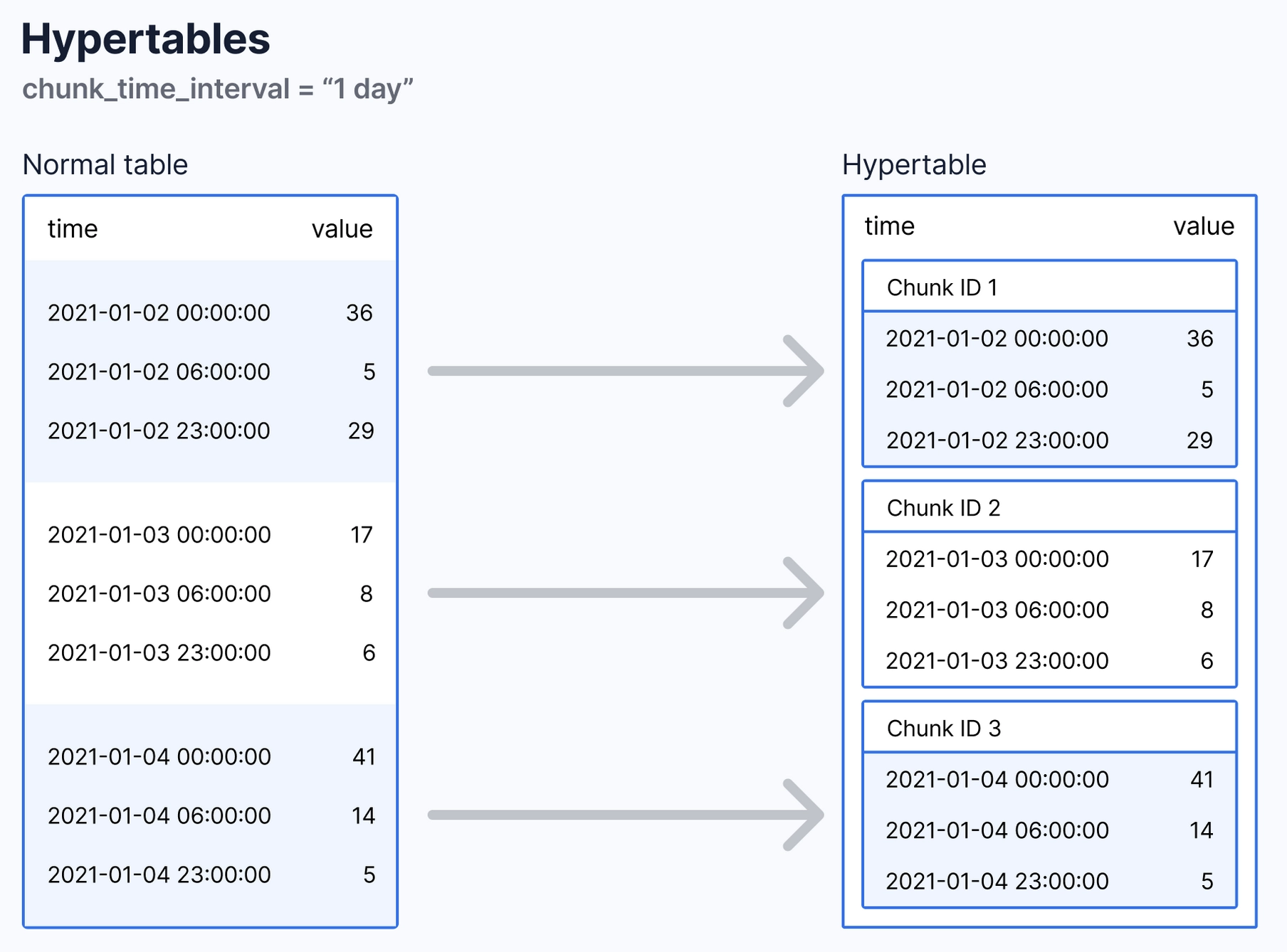
Compared to native PostgreSQL, TimescaleDB performs much better in terms of query performance and storage efficiency for time-series data. However, this is compared to PostgreSQL which is not known for its throughput. Though capable of performing better than InfluxDB in many real-world scenarios, TimescaleDB performance is nowhere near that of specialized time-series databases that are built from the ground-up to handle torrents of time-series data.
That said, TimescaleDB has innovated on an already excellent database via partitioning through chunked hypertables. Though on the other hand, TimescaleDB's scaling solutions are tied to complex, distributed PostgreSQL setups and may not be as efficient and production-reliable as other databases built specifically for time-series data.
KairosDB & Apache Cassandra
On the NoSQL side, we have KairosDB, which is built on top of Apache Cassandra. Originally developed at Facebook, Cassandra is a mainstay in distributed computing and big data. The advantages to using KairosDB is largely similar to the rationale given for TimescaleDB. The large community and infrastructure for Cassandra is a huge plus for existing users of Cassandra.
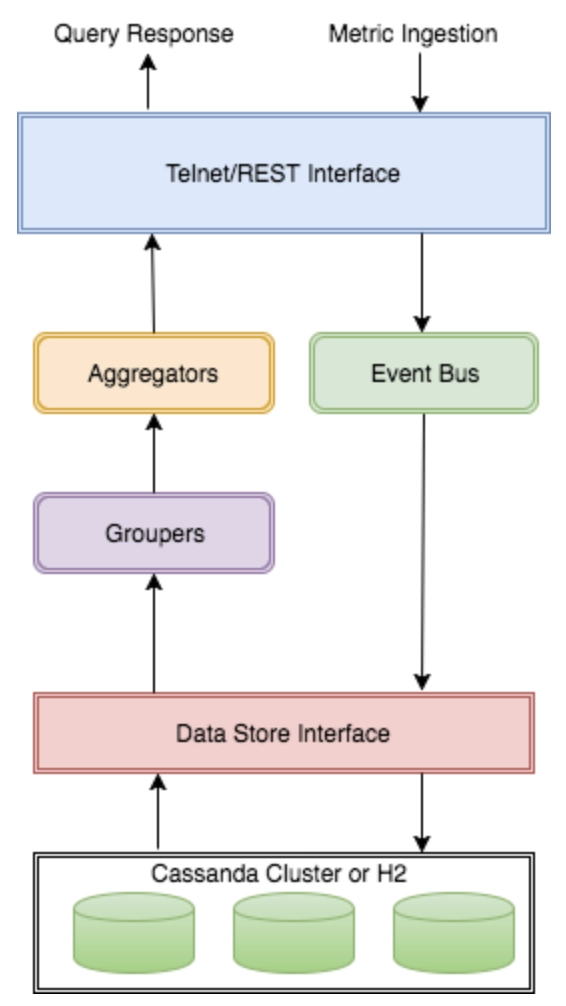
While powerful, Cassandra is notorious for its maintenance and management overhead, especially regarding performance tuning and repair operations. This rolls into KairosDB, and can present a huge challenge for teams who are not so familiar with the operational aspect of running a Cassandra cluster.
Use cases
Overall, both of these databases are solid for generic time-series use cases that have a similar performance profile to that of InfluxDB. The main rationale for choosing one of these would be familiarity with the underlying database. The main reason to look elsewhere would be if you have greater performance and reliability requirements than what these extensions can offer.
Recently TimescaleDB has branched out from just time-series data to dealing with vector workloads, integrating with pgai and pgvectorscale. If building AI applications with time-series data is a requirement, TimescaleDB may be worth checking out.
QuestDB, pure time-series performance
So far, we’ve seen examples of databases specializing in a certain use case, such as Prometheus for monitoring and kdb+ for financial markets. We've also looked at databases which leverage existing database ecosystems for compatibility and ease-of-use, TimescaleDB with PostgreSQL and KairosDB with Apache Cassandra. Each came with a different set of tradeoffs.
Next, we'll look at a custom-tailored time-series database. QuestDB is a highly-performant time-series database designed to handle the highest data volumes while leveraging open protocols and familiar SQL.
Let’s break down each of its characteristics.
Fast ingestion and query speed
While benchmark results can be skewed based on dataset and infrastructure setup, they still provide a useful measure for relative performance. Check out the benchmark numbers against InfluxDB v2.x and TimescaleDB to see how QuestDB handles large cardinality and workloads:
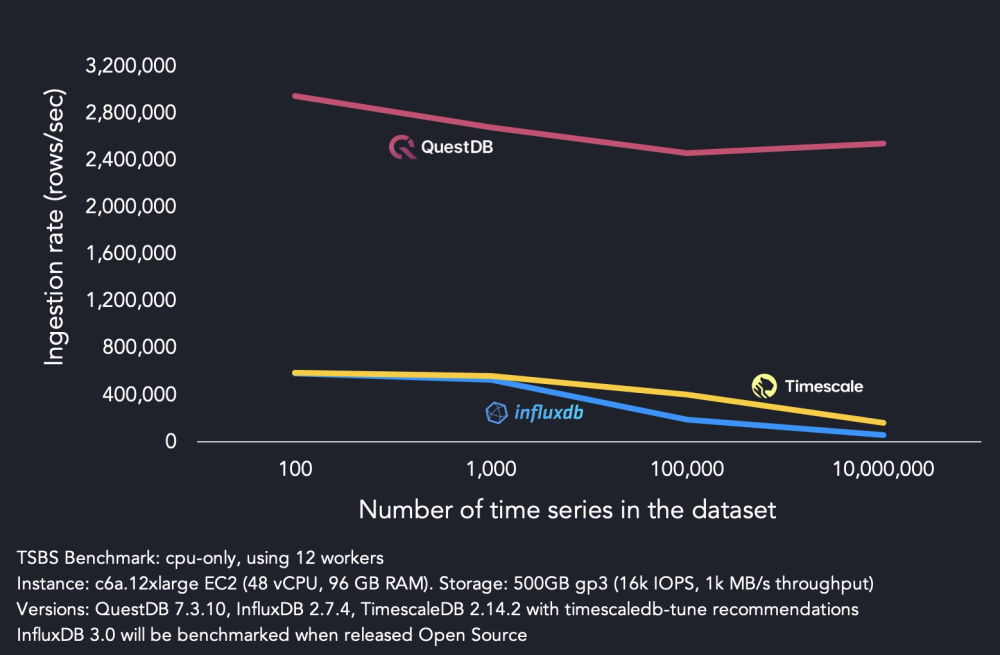
Flexible ingestion
Another beneficial feature of QuestDB is its flexible ingestion protocol support. Users can leverage InfluxDB Line Protocol, PostgreSQL wire, or REST API to load the data in whatever way that works best. If you are looking for a fast way to migrate from InfluxDB, simply use the InfluxDB Line Protocol to ingest data into QuestDB.
Full Grafana support
QuestDB offers a first-party Grafana plugin. Fluid dashboards are as functional as they are alluring. Yet that fluidity puts a lot of strain on the underlying database. If you're after silky-smooth Grafana dashboards capable of going well faster than the default Grafana refresh rate, QuestDB is a strong choice.
Extended SQL
Unlike InfluxDB and kdb+ that enforce its own set of domain-specific language (i.e., InfluxQL, Flux, q), QuestDB works with SQL out of the box. This reduces the learning curve to get started significantly.
Clear roadmap
The next stage of QuestDB uses a popular open-source, column-oriented data file format called Parquet to store its partitions. This will allow users to decouple storage and compute, so that they can load and unload data in native Parquet format on S3 directly if needed for better performance or ease of integration:
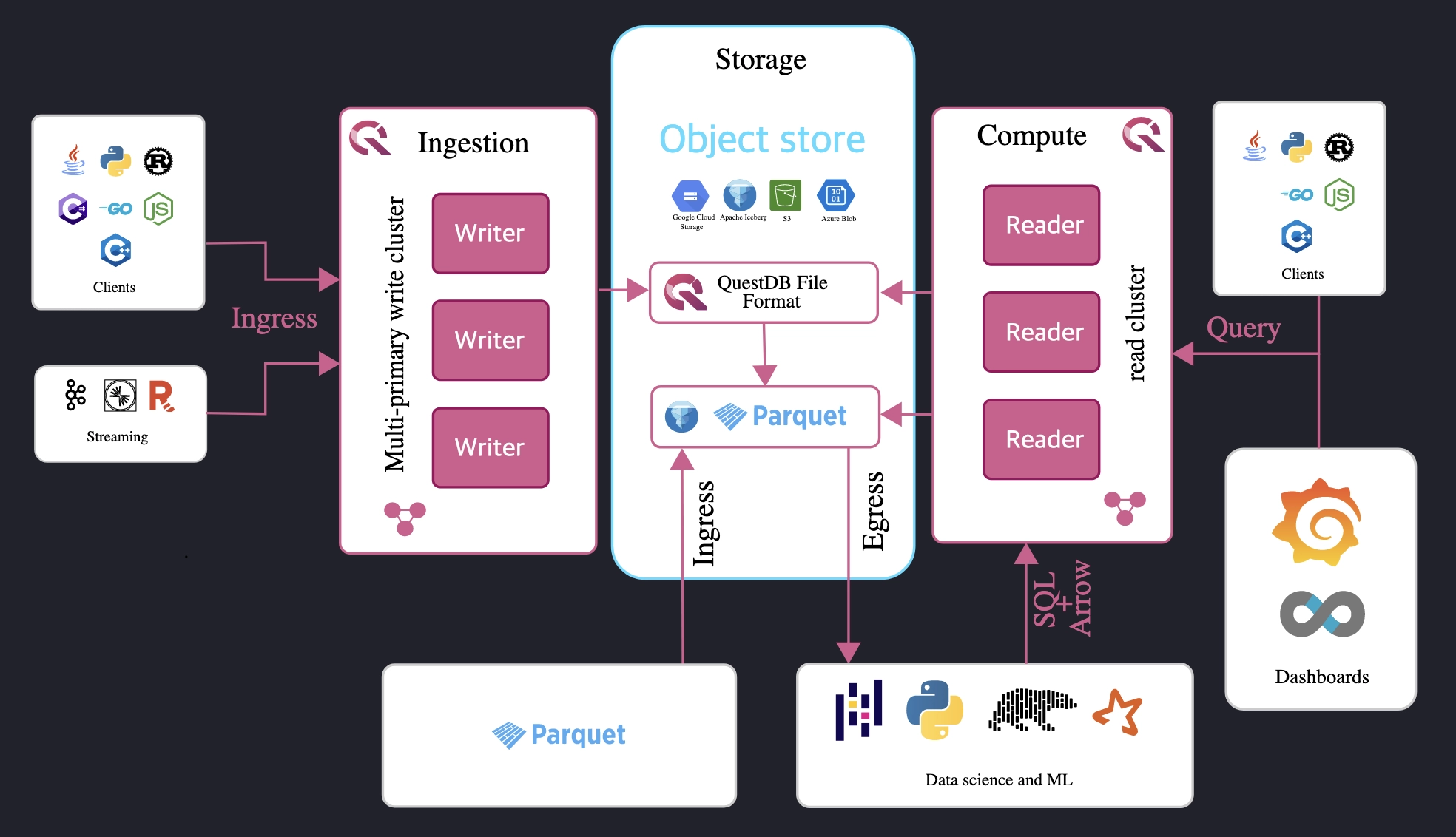
Many of QuestDB's largest customers are big players in finance, from hedge funds and traditional exchanges, to emerging crypto exchanges. These organizations found an alternative solution to InfluxDB's performance bottlenecks, avoided the vendor lock-in from kdb+, and liked the long-term, public roadmap better than OLAP or other analytics and time-series competitors.
If you're moving from InfluxDB, the first-party InfluxDB Line Protocol support means you can leverage your existing clients to start ingesting data into QuestDB. To compare InfluxDB and QuestDB more deeply and directly, checkout the comparison and benchmark blog.
Wrapping Up
In this article, we’ve looked at five alternatives to InfluxDB, starting from Prometheus and ending with QuestDB. Even though InfluxDB remains popular, the ecosystem for time-series databases has become more robust, offering users more options. Some databases are specialized for a certain use case like Prometheus. Others like kdb+ have a strong foothold in a specific market. On the other end, we have time-series databases that can handle more generic workloads built on top of familiar databases like PostgreSQL and Cassandra.
Last but not least, we have QuestDB that combines the best of these alternatives. It provides high ingest and query performance like kdb+, while maintaining openness and compatibility with other protocols such as InfluxDB Line Protocol and SQL that developers use and love. While QuestDB is younger and smaller in terms of community so far, give QuestDB a try if you are looking for a new project or migrating off InfluxDB.