In this blog post, QuestDB’s very own
Andrei Pechkurov presents how to ingest large
CSV files a lot more efficiently using the SQL
COPY statement, and takes us
through the journey of benchmarking. Andrei also shares insights about how the
new improvement is made possible by io_uring and compares QuestDB's import
versus several well-known OLAP and
time-series databases in Clickhouse's
ClickBench benchmark.
Introduction
As an open source time series database company, we understand that getting your existing data into the database in a fast and convenient manner is as important as being able to ingest and query your data efficiently later on. That's why we decided to dedicate our new release, QuestDB 6.5, to the new parallel CSV file import feature. In this blog post, we discuss what parallel import means for our users and how it's implemented internally. As a bonus, we also share how recent ClickHouse team's benchmark helped us to improve both QuestDB and its demonstrated results.
How ClickBench helped us improve
Recently ClickHouse conducted a benchmark for their own database and many others, including QuestDB. The benchmark included data import as the first step. Since we were in the process of building a faster import, this benchmark provided us with nice test data and baseline results. So, what have we achieved? Let's find out. The benchmark was using QuestDB's HTTP import endpoint to ingest the data into an existing non-partitioned table. You may wonder why it doesn't use a partitioned table, which stores the data sorted by the timestamp values and provides many benefits for time series analysis. Most likely, the reason is terrible import execution time. Both HTTP-based import and pre-6.5 COPY SQL command are simply not capable of importing a big CSV file with unsorted data. Thus, the benchmark opts for a non-partitioned table with no designated timestamp column. The test CSV file may be downloaded and uncompressed following the commands:
wget 'https://datasets.clickhouse.com/hits_compatible/hits.csv.gz'
gzip -d hits.csv.gz
The file is on the bigger side, 76GB when decompressed, and contains rows that are heavily out-of-order in terms of time. This makes it a nice import performance challenge for any time series database. Getting the data into a locally running QuestDB instance via HTTP is as simple as:
curl -F data=@hits.csv 'http://localhost:9000/imp?name=hits'
Such import took almost 28 minutes (1,668 seconds, to be precise) on a c6a.4xlarge EC2 instance with a 500GB gp2 volume in ClickBench. This yields around 47MB/s and leaves a lot to wish for. In contrast, it took ClickHouse database around 8 minutes (476 seconds) to import the file on the same hardware. But since we were already working on faster imports for partitioned tables, this benchmark provided us with nice test data and baseline results.
In addition to import speed, ClickBench measures query performance. Although
none of the queries it ran were related to
time series analysis, the results helped us
to improve QuestDB. We found and fixed a stability issue, as well as added
support for some SQL functions. Other than that, our SQL engine had a bug around
multi-threaded min()/max() SQL function optimization: it was case-sensitive
and simply ignored MIN()/MAX() used in ClickBench. After a trivial fix,
queries using these aggregate functions got their intended speed back. Finally,
a few queries marked with N/A result were using unsupported SQL syntax and it
was trivial to rewrite them to get proper results. With all of these
improvements, we have run ClickBench on QuestDB 6.5.2 and created a
pull request with the
updated results.
Long story short, although ClickBench has nothing to do with time series analysis, it provided us with a test CSV file and baseline import results, as well as helped us to improve query stability and performance.
The import speed-up
Our new optimized import is based on the SQL COPY statement:
COPY hits FROM 'hits.csv' WITH TIMESTAMP 'EventTime' FORMAT 'yyyy-MM-dd HH:mm:ss';
The above command uses the new COPY syntax to import the hits.csv file from
ClickBench to the hits table. For the command to work, the file should be made
available in the import root directory configured on the server:
cairo.sql.copy.root=\home\my-user\my-qdb-import
Since we care about time series data analysis, in our experiments, we partitioned it by day while the original benchmark used a non-partitioned table. Let's start with the most powerful AWS EC2 instance from the original benchmark:
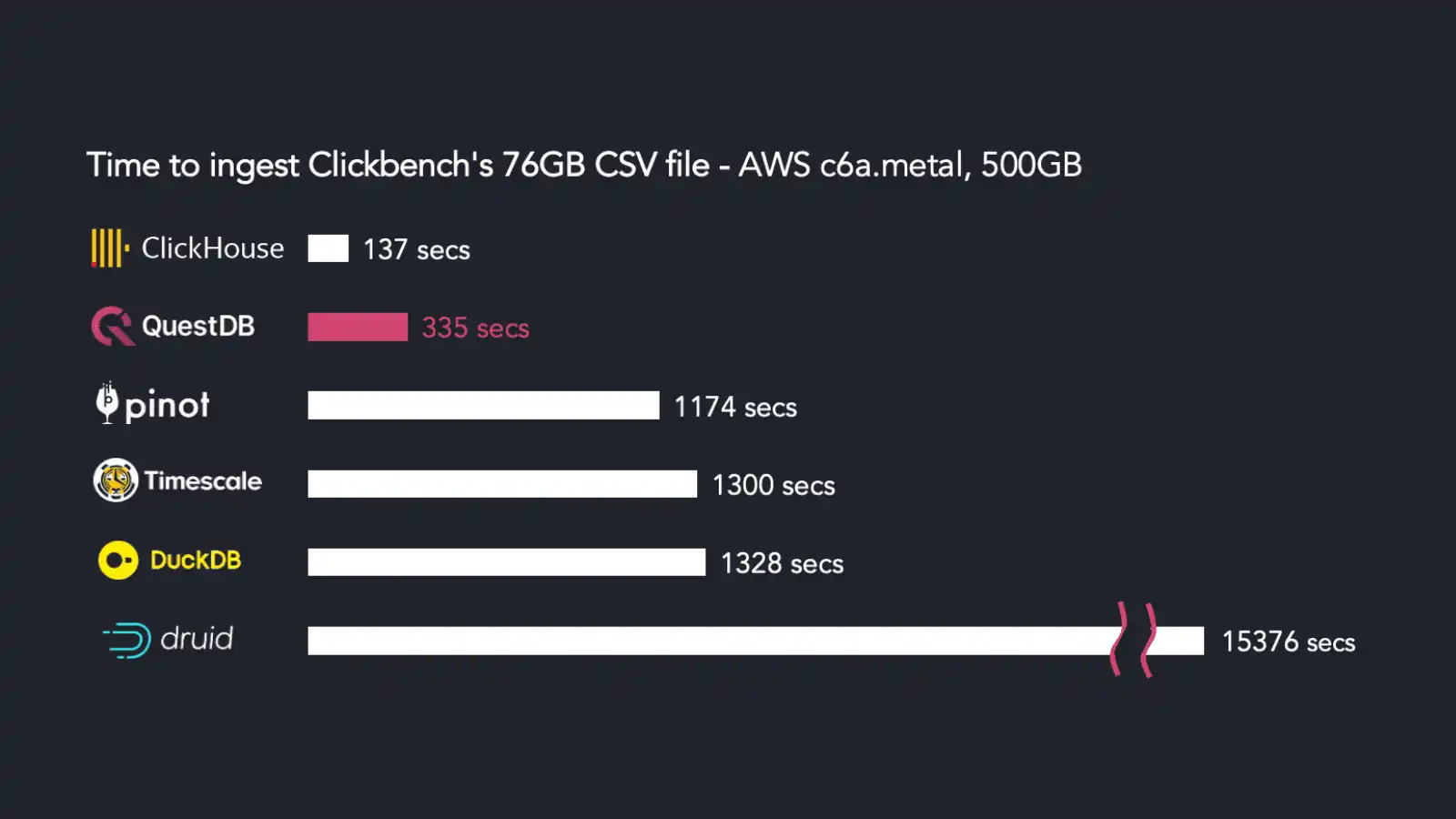
The above benchmark compares the import speed of several well-known OLAP and
time-series databases: Apache Pinot, Apache
Druid, ClickHouse, DuckDB, TimescaleDB, and QuestDB. Here, our new optimized
COPY imports almost 100M rows from the hits.csv file in 335 seconds, leaving
a higher place in the competition only to ClickHouse.
We also did a run on the c6a.4xlarge instance (16 vCPU and 32GB RAM) from the original benchmark which is noticeably less powerful than the c6a.metal instance (192 vCPU and 384GB RAM). Yet, both instances had a rather slow gp2 500GB EBS volume, the result was 17,401 seconds for the less powerful c6a.4xlarge instance. So, in spite of a very slow disk, c6a.metal is 52x faster than c6a.4xlarge. Why is that?
The answer is simple. The metal instance has a huge amount of memory, so once the CSV file gets decompressed, it fits fully into the OS page cache. Hence, the import doesn't do any physical reads from the input file and instead reads the pages from the memory (note: the machine has a NUMA architecture, but non-local memory access is still way faster than the disk reads). That's why we observe such huge difference here for QuestDB and, also, you may notice a 2.5x difference for ClickHouse in the original benchmark.
You may wonder why, by removing the need to read the data from the slow disk, QuestDB makes a very noticeable improvement, while it's only 2.5x for ClickHouse and even less for other databases? We're going to explain it soon, but for now, let's continue the benchmarking fun.
Honestly speaking, we find the choice of the metal instance in the ClickBench results rather synthetic, as it makes little sense to use a very powerful (and expensive) machine in combination with a very slow (and cheap) disk. So, we did a benchmark run on a different test stand:
- c5d.4xlarge EC2 instance (16 vCPU and 32GB RAM), Amazon Linux 2 with 5.15.50 kernel
- 400GB NVMe drive
- 250GB gp3, 16K IOPS and 1GB/s throughput, or gp2 of the same size
What we got is the following:
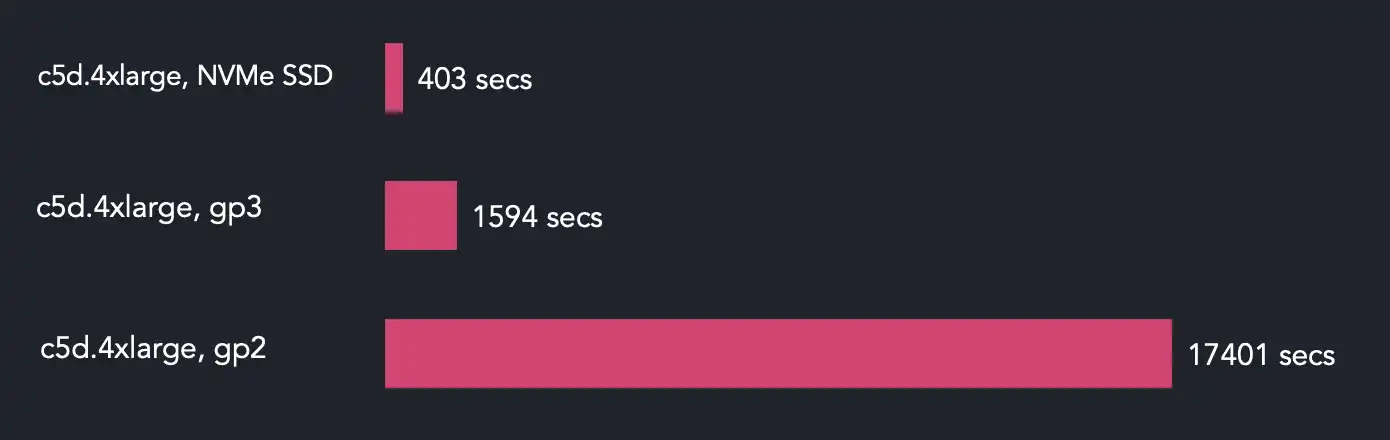
The very last result on the above chart stands for the scenario of c5d.4xlarge instance with a slow gp2 volume. We are including it to show the importance of the disk speed to the performance.
In the middle of the chart, the-gp3-volume-only result doesn't use the local SSD, but manages to ingest the data into a partitioned table a lot faster than the gp2 run, thanks to the faster EBS volume. Finally, in the NVMe SSD run, the import takes less than 7 minutes - an impressive ingestion rate of 248,000 row/s (or 193MB/s) without having the whole input file in the OS page cache. Here, the SSD is used as a read-only storage for the CSV file, while the database files are placed on the EBS volume. This is a convenient approach for a single-time import of high volume of data. As soon as the import is done, the SSD is no longer needed, so the EBS volume may be attached to a more affordable instance where the database would run.
As shown by the top result in the chart above, the optimized import makes a terrific difference for anyone who wants to import their time series data to QuestDB, but also takes us close to the ClickHouse's results from the practical perspective. Another nice property of QuestDB's import is that, as soon as the import ends, the data is laid out on disk optimally, i.e. the column files are organized in partitions and no background merging is required.
Now, as we promised, we're going to explain why huge amount of RAM or a locally-attached SSD makes such a difference for QuestDB's import performance. To learn that, we're taking a leap into an engineering story full of trial and error.
Optimizing the import
Our HTTP endpoint, as well as the old COPY implementation, is handling the
incoming data serially (think, as a single-time stream) and uses a single thread
for that. For out-of-order (O3) data, this means lots of O3 writes and, hence,
partition re-writes. Both single-threaded handling and O3 writes become the
limiting factor for these types of import.
However, the COPY statement operates on a file, so there is nothing preventing
us from going over it as many times as needed.
QuestDB's storage format doesn't involve complicated layout like the one in LSM trees or in other similar persistent data structures. The column files are partitioned by time and versioned to handle concurrent reads and writes. The advantages of this approach is that as soon as the rows are committed, the on-disk data is optimal from the read operation perspective - there is no need to go through multiple files with potentially overlapping data when reading from a single partition. The downside is that such storage format may be problematic to cope with, when it comes to data import.
But no worries, that's something we have optimized.
The big ideas we had when working on our shiny new COPY are really simple.
First, we should organize the import in multiple phases in order to enable
in-order data ingestion. Second, we go parallel, i.e. multi-threaded, in each of
those phases, where it is possible.
Broadly speaking, the phases are:
- Check input file boundaries. Here we try to split the file into N chunks, so that N worker threads may work on their own chunk in isolation.
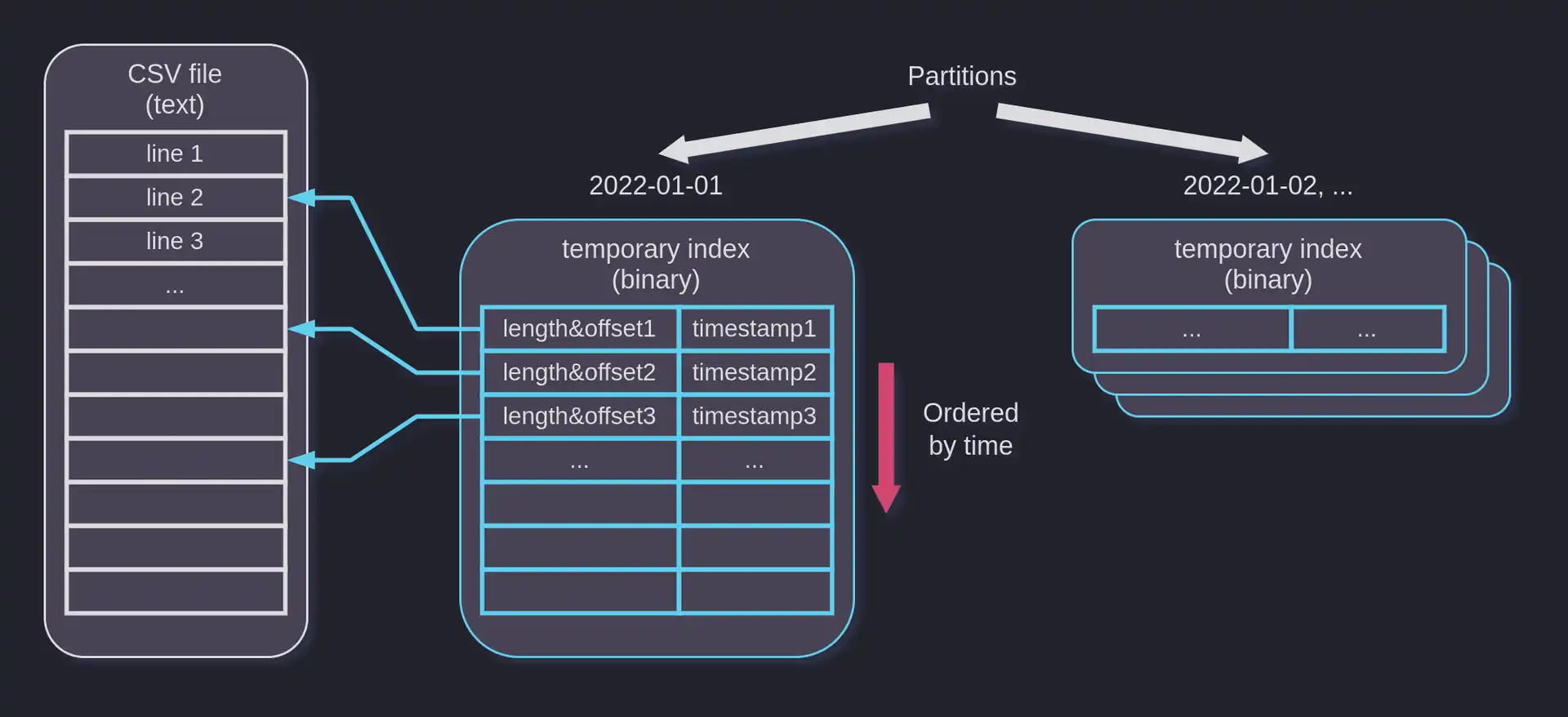
- Index the input file. Each thread scans its chunk, reads designated timestamp column values, and creates temporary index files. The index files are organized in partitions and contain sorted timestamps, as well as offsets pointing to the source file.
- Scan the input file and import data into temporary tables. Here, the threads use the newly built indexes to go through the input file and write their own temporary tables. The scanning and subsequent writes are guaranteed to be in-order thanks to the index files containing timestamps and offsets tuples sorted by time. The parallelism in this phase comes from multiple partitions being available to the threads to work independently.
- Perform additional metadata manipulations (say, merge symbol tables) and, finally, move the partitions from temporary tables to the final one. This is completed in multiple smaller phases that we summarize as one, for the sake of simplicity.
The indexes we build at phase 2 may be illustrated in the following way:
The above description is an overview of what we've done for the new COPY. Yet,
a careful reader might spot a potential bottleneck. Yes, the third phase
involves lots of random disk reads in case of an unordered input file. That's
exactly what we observed as a noticeable bottleneck when experimenting with the
initial implementation. But does it mean that there is nothing we can do with
this? Not really. Modern HW & SW to the rescue!
io_uring everything!
Modern SSDs, especially NVMe ones, have evolved quite far from their spinning
magnetic ancestors. They're able to cope with much higher concurrency levels for
disk operations, including random read ones. But utilizing these hardware
capabilities with traditional blocking interfaces, like
pread(), would involve
many threads and, hence, some overhead here and there (like increased memory
footprint or context switching). Moreover, QuestDB's threading model operates on
a fixed-size thread pool and doesn't assume running more threads than the
available CPU cores.
Luckily, newer Linux kernel versions support
io_uring, a new asynchronous I/O interface.
But would it help in our case? Learning the answer is simple and, in fact,
doesn't even require a single line of code, thanks to
fio, a very flexible I/O tester utility.
Let's check how blocking random reads of 4KB chunks would perform on a laptop with a decent NVMe SSD:
$ fio --name=read_sync_4k \
--filename=./hits.csv \
--rw=randread \
--bs=4K \
--numjobs=8 \
--ioengine=sync \
--group_reporting \
--runtime=60 \
/
...
Run status group 0 (all jobs):
READ: bw=223MiB/s (234MB/s), 223MiB/s-223MiB/s (234MB/s-234MB/s), io=13.1GiB (14.0GB), run=60001-60001msec
Disk stats (read/write):
nvme0n1: ios=3166224/361, merge=0/318, ticks=217837/455, in_queue=218357, util=50.72%
Here we're using 8 threads to make blocking read calls to the same CSV file and observe 223MB/s read rate which is not bad at all.
Now, we use io_uring to do the same job:
$ fio --name=read_io_uring_4k \
--filename=./hits.csv \
--rw=randread \
--bs=4K \
--numjobs=8 \
--ioengine=io_uring \
--iodepth=64 \
--group_reporting \
--runtime=60 \
/
...
Run status group 0 (all jobs):
READ: bw=2232MiB/s (2340MB/s), 2232MiB/s-2232MiB/s (2340MB/s-2340MB/s), io=131GiB (140GB), run=60003-60003msec
Disk stats (read/write):
nvme0n1: ios=25482866/16240, merge=6262/571137, ticks=27625314/25206, in_queue=27650786, util=98.86%
We get an impressive 2,232MB/s this time. Also, it is worth noting that disk utilization has increased to 98.86% against 50.72% in the previous fio run, all of that with the same number of threads.
This simple experiment proved to us that io_uring may be a great fit in our
parallel COPY implementation, so we added an experimental API and continued
our experiments. As a result, QuestDB checks the kernel version and, if it's new
enough, uses io_uring to speed up the import. Our code is also smart enough to
detect in-order adjacent lines and read these lines in one I/O operation. Thanks
to such behavior, parallel COPY is faster than the serial counterpart even on
ordered files.
We have explained why presence of a NVMe SSD made such a change in our introductory benchmarks. EBS volumes are very convenient, but they show an order of magnitude less IOPS and throughput rates than a physically attached drive. Thus, using such drive for the purposes of initial data import makes a lot of sense, especially when we consider a few terabytes to be imported.
What's next?
Prior to QuestDB 6.5, importing large amounts of unsorted data into a partitioned table was practically impossible. We hope that our users will appreciate this feature, as well as other improvements we've made recently. As a logical next step, we want to take our data import one step further by making it available and convenient to use in QuestDB Cloud. Finally, needless to say, we'll be thinking of more use cases for io_uring in our database.
As usual, we encourage you to try out the latest QuestDB 6.5.2 release and share your feedback with our Slack Community. You can also play with our live demo to see how fast it executes your queries. And, of course, contributions to our open source project on GitHub are more than welcome.