Database replication tuning
QuestDB replication is tunable.
Replication can either:
- React to transaction events more quickly
- Lower latency with more network overhead
- Package more transactions together
- Higher latency with less network overhead
Before we dig into it, consider:
- How to enable and setup replication
- Learn replication concepts
- Full replication configuration options
Overview
In large part, tuning comes down to 3 key configuration options.
These options are set in your QuestDB server.conf:
| Property | Default Value |
|---|---|
| cairo.wal.segment.rollover.size | 2097152 (2MiB) |
| replication.primary.throttle.window.duration | 10000 (10s) |
| replication.primary.sequencer.part.txn.count | 5000 (transactions) |
Default settings
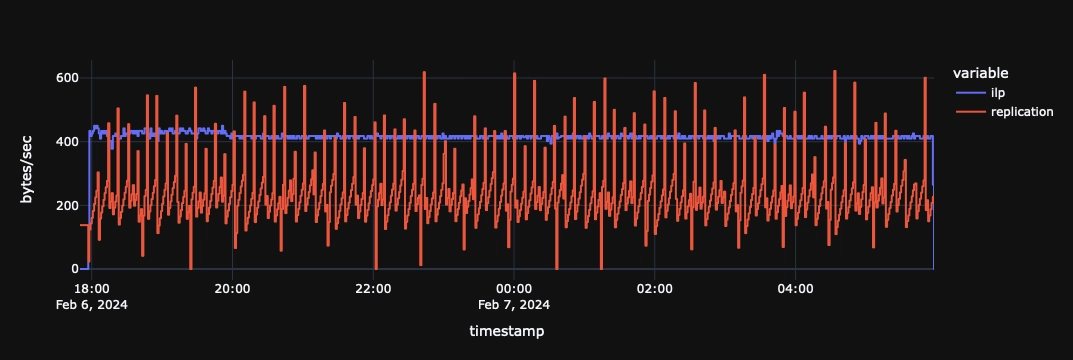
By default, replication increases network utilization by around 9x compared to the baseline seen ingesting via the InfluxDB Line Protocol. This default optimizes for lower latency and higher activity, where responsiveness is most desirable.
cairo.wal.segment.rollover.size=2097152
replication.primary.throttle.window.duration=10000
replication.primary.sequencer.part.txn.count=5000
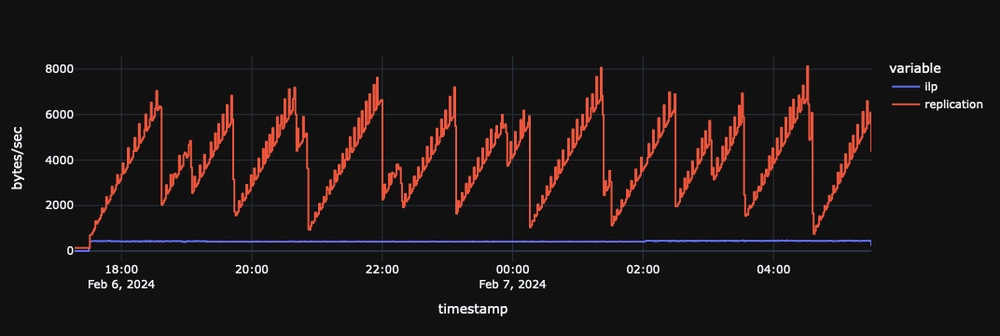
We'll go through an example tuning scenario and explain each option.
The following represents 12 hours of replication activity.
To demonstrate, we will trace network usage for a single table receiving one row with 31 columns per second.
Breakdown of key settings
Tuning is a balance between 3 main options.
cairo.wal.segment.rollover.sizereplication.primary.throttle.window.durationreplication.primary.sequencer.part.txn.count
What do these options do?
cairo.wal.segment.rollover.size
In QuestDB each table replicates in a cycle independently of other tables. Thus each of the database's network client connections writes its data to its own segment in the Write-Ahead Log (WAL).
Once a WAL segment reaches a certain size, it's closed and a new one is opened. The smaller the size, the more often segments roll over. This results in less overall network overhead.
| Property | Default Value | Updated Value |
|---|---|---|
| cairo.wal.segment.rollover.size | 2097152 (2MiB) | 262144 (256KiB) |
However, small files may be inefficient or expensive to store in your object storage. For example, AWS S3 Intelligent Tiering, requires that a file must be over 128KiB.
Note that if you are replicating with a file system such as NFS, larger files will give better throughput for point-in-time recovery. As such, including 8x compresison, the default 2097152 (2MiB) is appropriate for many cases. But you can go smaller too, depending on your object store setup.
replication.primary.throttle.window.duration
Next, replication transfers WAL segment files to the object store. If a segment is allowed to close first then it will only be uploaded once, otherwise it will be re-uploaded multiple times, each time with more data. This causes write amplification.
To reduce it, set to a longer throttle value:
| Property | Default Value | Updated Value |
|---|---|---|
| replication.primary.throttle.window.duration | 10000 (10s) | 60000 (60s) |
This value represents your maximum replication latency tolerance. The default is
10 seconds (10000), but could be 60 seconds (60000), five minutes (300000)
or whatever best suits your operational requirements.
Note that even with a longer value, QuestDB still actively manages replication to prevent a backlog. Therefore, increasing this duration will not result in a pile-up of data needing replication, even when there's a burst of activity.
If minimizing network traffic is a priority for your production environment, opting for a longer duration reduces the frequency of replication operations, providing better network efficiency minor replication delay.
replication.primary.sequencer.part.txn.count
Data ingested into QuestDB is written to multiple WAL segments, one open segment per connection. However, for a given table transactions themselves are recorded in a central sequencer transaction log. The number of stored transactions is flexible and are packaged together as a "part".
We recommend that these "parts" remain as small as is reasonable for your object store, since the relevant parts are uploaded (or reuploaded) each and every replication cycle. By default, each part holds 5000 "txn" records.
| Property | Default Value | Updated Value |
|---|---|---|
| replication.primary.sequencer.part.txn.count | 5000 (transactions) | 1000 (transactions) |
Since each record is 28 bytes, once compressed - usually at ~6x - we expect parts to be around ~23KiB each. Customize the part size as is appropriate for your case, but note that you can only change this value when initially enabling replication.
The setting is fixed for a given table once set.
Impact of compression
Compression is Key! Although it can lead to fuzzy calculations if we're not clear on detail.
The tables below help inform calculations appropriate for your object store.
For our default scenario:
| WAL Part | Default Value | Expected Compression | Estimate Size in Object Store |
|---|---|---|---|
| WAL Segment | 2 MiB | 8x | ~256 KiB |
| Sequencer Part | 5000 txns (*28 = 136 KiB) | 6x | ~22.7 KiB |
For our compressed scenario:
| WAL Part | Updated Value | Expected Compression | Estimate Size in Object Store |
|---|---|---|---|
| WAL Segment | 256 KiB | 8x | ~32 KiB |
| Sequencer Part | 1000 txns (*28 = 136 KiB) | 6x | ~4.5 KiB |
Summary
In summary, to tune for network efficiency:
- Make the segments and sequencer parts as small as your specific object store can handle
- Make the replication window duration as long as you can tolerate for your requirements
For example, reducing the segment size to 256KiB, the sequencer parts to 1000 records, and increasing the replication window duration to one minute, the network traffic reduces to 57% of the ILP ingestion traffic.
All together, the tuned, network effective settings are:
cairo.wal.segment.rollover.size=262144
replication.primary.throttle.window.duration=60000
replication.primary.sequencer.part.txn.count=1000