
Looking for the top time-series database? This article compares QuestDB with InfluxDB to compare performance and help understand the key differences. After reading, you will have more information to choose the right time-series database that for your use case.
Post edited in March 2024 to reflect and describe the latest benchmarks
Introduction to InfluxDB and QuestDB
Released in 2013, InfluxDB is an open-source time-series database subject to the MIT license. Both open-source versions of InfluxDB (v1 and v2) are implemented in Go.
QuestDB is an open-source time-series database licensed under Apache License 2.0. It is designed for high throughput ingestion and fast SQL queries. It supports schema-agnostic ingestion using the InfluxDB line protocol, PostgreSQL wire protocol, and a REST API for bulk imports and exports.
A brief comparison based on DB-Engines:
| Name | InfluxDB | QuestDB |
|---|---|---|
| Primary database model | Time Series DBMS | Time Series DBMS |
| Implementation language | Go | Java (low latency, zero-GC), C++ |
| SQL | SQL-like query languages (InfluxQL, Flux) | SQL |
| APIs and other access methods | HTTP API (including InfluxDB Line Protocol), JSON over UDP | InfluxDB Line Protocol, Postgres Wire Protocol, HTTP, JDBC |
Performance benchmarks
Before we get into internals, let's compare how QuestDB and InfluxDB handle both ingestion and querying. As usual, we use the industry standard Time Series Benchmark Suite (TSBS) as the benchmark tool. Unfortunately, TSBS upstream does not support InfluxDB v2. Hence, we use our own TSBS fork.
The hardware we use for the benchmark is the following:
- c6a.12xlarge EC2 instance with 48 vCPU and 96 GB RAM
- 500GB gp3 volume configured for the maximum settings (16,000 IOPS and 1,000 MB/s throughput)
The software side of the benchmark is the following:
- Ubuntu 22.04
- InfluxDB 2.7.4 with the default configuration
- QuestDB 7.3.10 with the default configuration
Ingestion benchmark
To benchmark ingestion, we will test a cpu-only scenario with two days of CPU
data for various numbers of simulated time-series. The number of time-series are
set to 100, 1K, 100K, and 10M to demonstrate the effects of
high data cardinality on ingestion performance.
Cardinality typically refers to the number of unique elements in a set's size. In the context of a time-series database, high cardinality boils down to many indexed columns in a table, each of which contains many unique values.
To benchmark ingestion, we run:
$ ./tsbs_generate_data --use-case="cpu-only" --seed=123 --scale=1000 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --log-interval="10s" --format="influx" > /tmp/influx_data
$ ./tsbs_load_influx --db-name=benchmark --file=/tmp/influx_data --urls=http://localhost:8086 --auth-token="<auth_token>" --workers=10
The results appear as such:
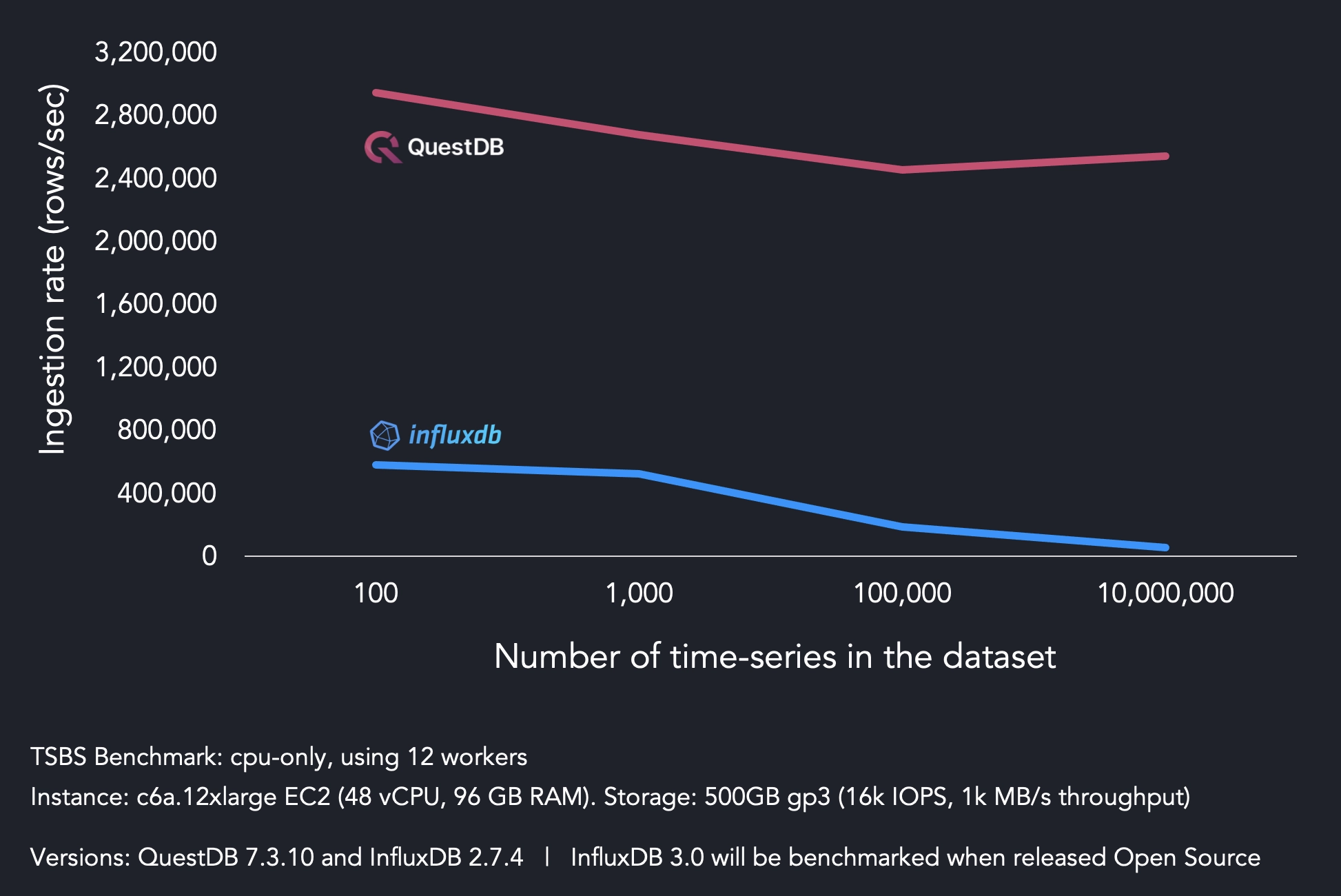
Within this test, QuestDB hits maximum ingestion throughput of 2.94M rows/sec versus 581K rows/sec for InfluxDB. For 10M unique series, QuestDB sustains 2.3M rows/sec, versus 55K rows/sec for InfluxDB. The latter illustrates the effects of high cardinality on InfluxDB's ingestion performance.
Explaining ingestion performance
High cardinality is a known problem area for InfluxDB, and this is likely because of the system architecture and storage engine. InfluxDB stores each time series in its own Time-Structured Merge tree, a log-structured merge (LSM) tree-like persistent data structure, so reading and writing the data becomes more expensive when the total number of time series becomes high.
In QuestDB, the storage model is completely different from LSM trees or B-trees and instead uses data stored in densely ordered vectors on disk. As such, QuestDB provides improved handling of with high cardinality datasets.
Query performance
While QuestDB outperforms InfluxDB for ingestion, query performance is equally essential for time-series data analysis. We'll first test using 1 worker and then 10 workers, as there is nuance.
As part of the standard TSBS benchmark, we test several types of popular time series queries:

All queries target two weeks of 4K emulated host data.
To run the benchmark, we apply TSDB like so:
$ ./tsbs_generate_queries --use-case="cpu-only" --seed=123 --scale=4000 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --queries=1000 --query-type="single-groupby-1-1-1" --format="influx" /tmp/influx_query_single-groupby-1-1-1
$ ./tsbs_run_queries_influx --file=/tmp/influx_query_single-groupby-1-1-1 --auth-token="<auth_token>" --workers=1
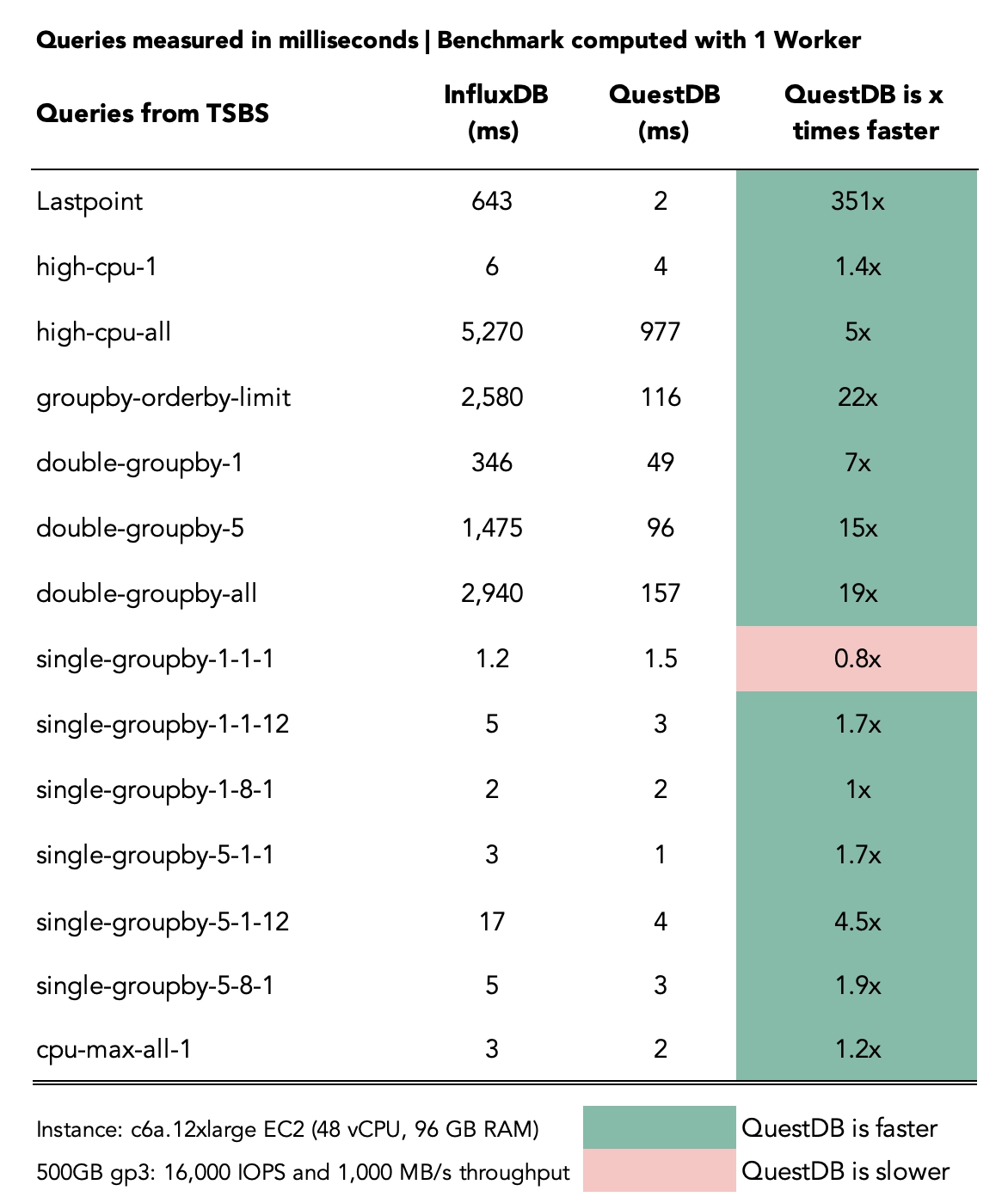
Results arrive in milliseconds measurements:
Next, let's test using 10 workers:
$ ./tsbs_generate_queries --use-case="cpu-only" --seed=123 --scale=4000 --timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-15T00:00:00Z" --queries=1000 --query-type="single-groupby-1-1-1" --format="influx" > /tmp/influx_query_single-groupby-1-1-1
$ ./tsbs_run_queries_influx --file=/tmp/influx_query_single-groupby-1-1-1 --auth-token="<auth_token>" --workers=10
And the result?
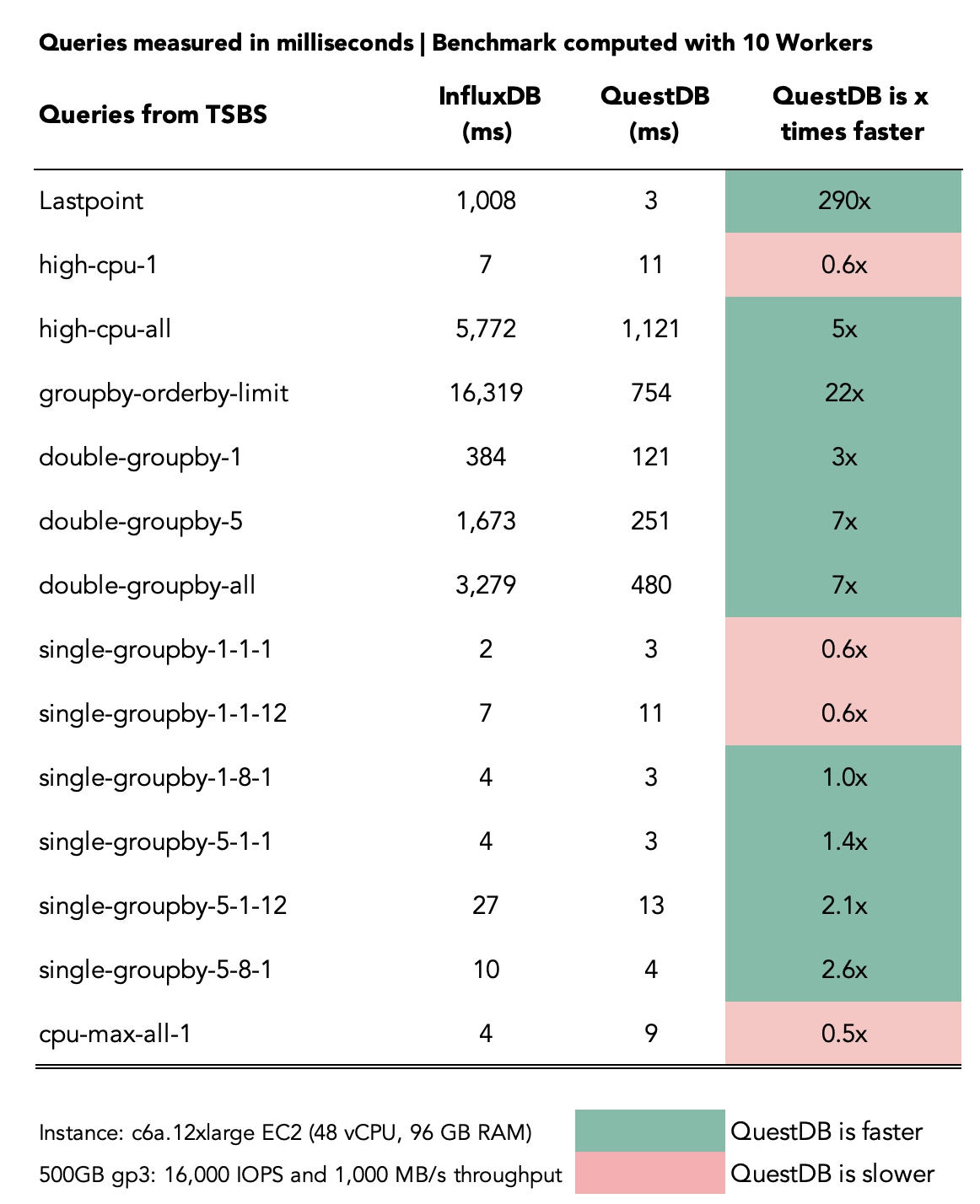
Explaining query performance
Overall, QuestDB excels in most query types. In some cases, InfluxDB's storage format makes data fetching on a single host somewhat more efficient. But even in these cases, QuestDB reaches similar performance, in large part due to parallelized filters and GROUP BY queries.
The caveat of the InfluxDB model becomes clear when querying across multiple time series, where QuestDB can provide many multiples of improvement.
Let's pick a few queries and unpack the results.
Lastpoint
The last reading for each host.
QuestDB is 351x faster with 1 worker and 290x faster with 10.
QuestDB stores data chronologically and is append-only. Retrieving the latest data point is very efficient as a result. Sorting starts from the bottom of the table, which has the most recent data point.
Double group by queries
Aggregate across both time and host.
With 1 worker, QuestDB is 7x, 15x, and 19x faster, for double-groupby-n: 1, 5,
and all respectively. With 10 workers, QuestDB is 3x, 7x and 7x.
The reason for QuestDB's strength is that the engine will scan all rows within the interval, and then aggregate them. This occurs on multiple threads and does not involve filtering. All told, QuestDB leverages multi-threading, parallel execution, and SIMD instructions from the CPUs.
Single group by 1-1-1 / 1-1-12 / 1-8-1 / 5-1-1 queries
Simple aggregation on one metric for 8 hosts, for 1 hour or 12 hours.
Results vary from 1 worker to 10, with QuestDB outperforming by ~2x on some queries, up to ~4x, with InfluxDB being ~.6x faster in some queries.
QuestDB keeps all time series in a single dense table. When a query accesses a single time series - like measurements for a host - it filters the rows on access.In contrast, InfluxDB stores the deltas between time series indvidually, so it has the advantage of being able to access the data sequentially.
Thus, QuestDB filters out 1,000 rows - from 1,000 hosts in total - to find the queried row one. InfluxDB just reads the host's files. But due to optimizations within QuestDB such as parallelizaiton and SIMD usage it still provides improved performance in most cases.
Difference between 1 worker and 10 workers
What's with the difference in 1 worker and 10 worker performance?
For each query, the benchmark runs them 1,000 times. We then take the average execution time and report the number.
With 1 worker, QuestDB uses all available resources from the machine and then applies it one query, in sequence. Therefore, each query gets all the power of the cores that apply instructions in parallel.
With 10 workers, multiple queries are run in parallel rather than one at the time. As a result, fewer resources are available for each of the 1,000 query runs. But this balances out. The time for which the 1,000 queries will be completed - known as wall clock time - is much faster.
The benchmark does not report wall clock time in these benchmarks. They are only concerned about the individual query time, which is the average of the 1,000 runs.
Query benchmark summary
QuestDB's underperformance for queries on a single or a few nodes can be explained with index-based data access. Since there are many node measurements (think, time series) stored in the table, fetching values that belong to a concrete node assumes a random disk access pattern.
Of course, this stands true only for so-called cold query execution. This is a situation when the data is not in the OS page cache. Once the data is in the cache, disk I/O doesn't matter anymore.
The plan for QuestDB is to improve cold execution for such queries significantly with the sub-partitioning feature. This way, multiple symbol column values (think, nodes) will be stored in smaller column files, leading to a sequential access pattern and, hence, better performance for queries accessing only a single or a few symbols.
For more complicated queries, QuestDB's better performance lies in its query engine: it takes advantage of a columnar data layout, SIMD instructions, and multi-threaded processing.
Want to see QuestDB vs TimescaleDB? Checkout the article.
What are the data models used in InfluxDB and QuestDB?
Now that we've presented the contrast in performance, what is it under-the-hood that makes it so? We'll get deeper.
One of the first places to compare QuestDB and InfluxDB is how data is handled and stored in each database. InfluxDB has a dedicated line protocol message format for ingesting measurements. Each measurement has a timestamp, a set of tags (a tagset), and a set of fields (a fieldset):
measurementName,tagKey=tagValue fieldKey="fieldValue" 1465839830100399000
--------------- --------------- --------------------- -------------------
| | | |
Measurement Tags Fields Timestamp
In InfluxDB, tagset values are indexed strings, while fieldset values are not indexed. The data types that fields may use are limited to floats, integers, strings, and booleans. The following snippet is an example message in the InfluxDB line protocol:
sensors,location=london,version=REV-2.1 temperature=22,humidity=50 1465839830100399000\n
QuestDB supports the InfluxDB line protocol (ILP) for compatibility purposes, so inserts using the ILP supports the same data types. QuestDB supports additional numeric types, such as BYTE for 8-bit integers, FLOAT for 32-bit floats, LONG256 for larger integers, UUID for identifiers, and GEOHASH for geospatial data. Additional types can be used while ingesting InfluxDB line protocol by creating a table with a desired schema before writing data.
QuestDB also exposes PostgreSQL wire protocol and a REST API for inserts, allowing for more control over the data types that the system can handle, including additional types such as date, char, and binary. In QuestDB, it's also possible to add indexes to existing columns in tables, which can be done directly through SQL:
ALTER TABLE sensors ALTER COLUMN firmware ADD INDEX;
QuestDB has full support for relational queries, whereas InfluxDB is a NoSQL, non-relational database with a custom data model. QuestDB supports both schema-agnostic ingestions over InfluxDB line protocol and a relational data model. Users can leverage both paradigms and perform SQL JOINs to correlate "schemaless" data with relational data by timestamp.
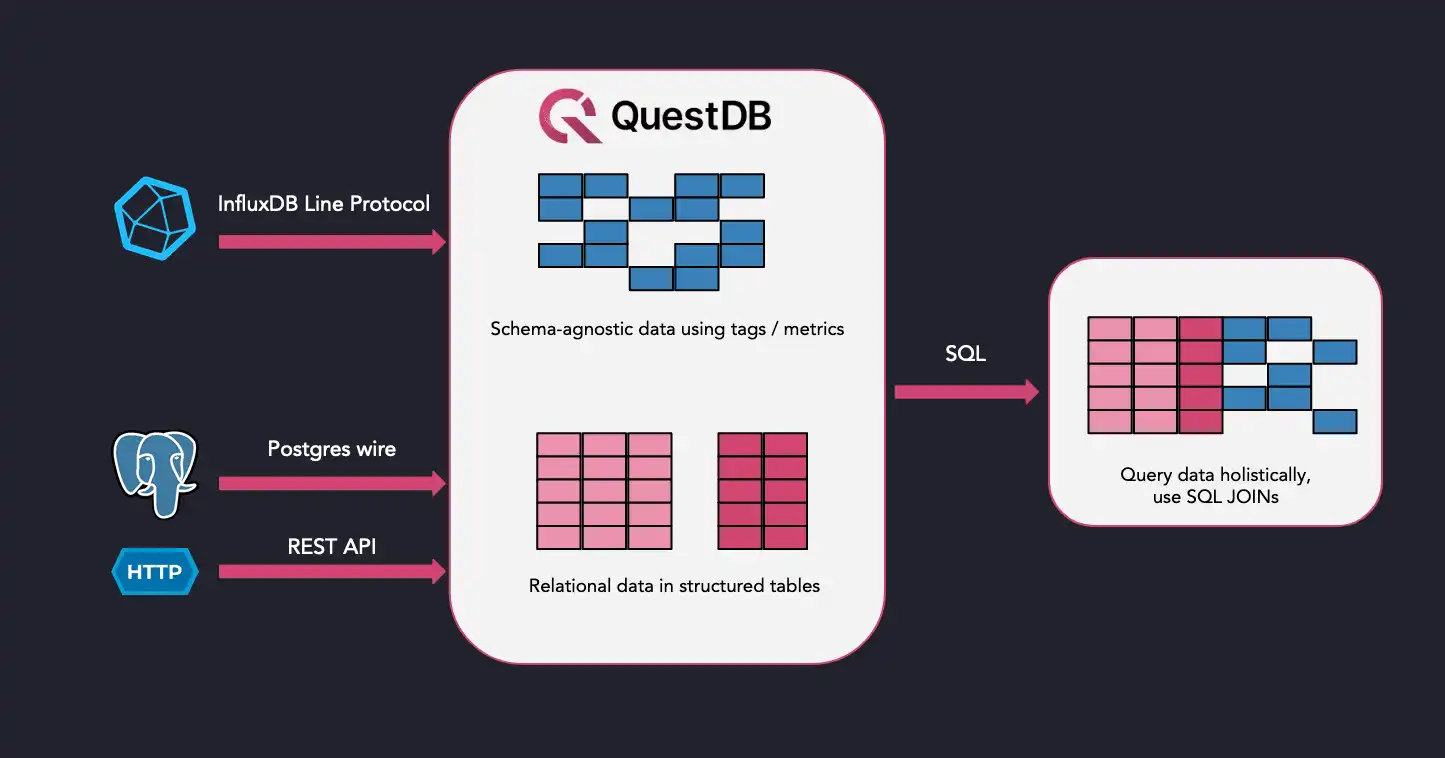
Comparing database storage models
For storage, InfluxDB uses Time-Structured Merge (TSM) Trees, where data is stored in a columnar format, and the storage engine stores differences (or deltas) between values in a series. InfluxDB uses a time-series index for indexing to keep queries fast as cardinality grows. Still, the efficiency of this index has its limitations, explored in more detail below.
QuestDB uses columnar data structures but indexes data in vector-based append-only column files. Sorting of out-of-order data occurs in a staging area in memory, while sorted and persisted data is merged later using an append model. The main motivation for merging with persisted data in this way is to keep the storage engine performant on both read and write operations.
InfluxDB has a shard group concept as a partitioning strategy, allowing for grouping data by time. Users can provide a shard group duration which defines how large a shard will be and can enable common operations such as retention periods for data (deleting data older than X days, for example):
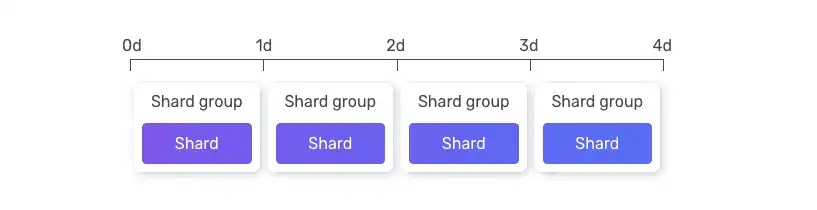
QuestDB has similar functionality to partition tables by time, and users may specify a partition size. When tables are partitioned by time, table metadata is defined once per table, and column files are partitioned at the filesystem level into directories per partition:
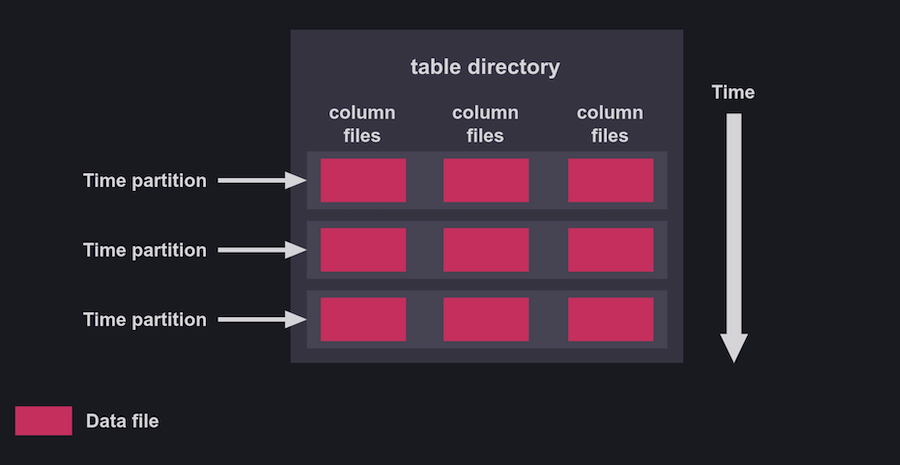
Both QuestDB and InfluxDB have ways to partition data by time and employ a retention strategy. The difference in partitioning for each system is the broader terminology and the fact that QuestDB does not need to create separate TSM files on disk per partition.
Ease of use of SQL compared to custom query languages
The emergence of NoSQL as a popular paradigm has effectively split databases into two categories: SQL and NoSQL.
InfluxDB originally started with a language similar to SQL called InfluxQL, which balanced some aspects of SQL with custom syntax. InfluxDB eventually adopted Flux as a query language to interact with data.
QuestDB embraces SQL as the primary query language so that there is no need for learning custom query languages. SQL is a good choice for time-series databases; it's easy to understand, most developers are familiar with it already, and SQL skills are simple to apply across different systems. As reported by the Stack Overflow developer survey of 2022, it's the third most popular language developers use. It proves to be a long-standing choice for quickly asking questions about the characteristics of your data.
Flux enables you to work with InfluxDB more efficiently, but it's difficult to read, and it's harder to learn and onboard new users. From users' perspective, learning a new custom query language is inconvenient for accessibility regardless of their engineering background.
from(bucket:"example-bucket")
|> range(start:-1h)
|> filter(fn:(r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total"
)
|> aggregateWindow(every: 1m, fn: mean)
Consider that the Flux query above can be written in SQL as follows:
SELECT avg(cpu),
avg(cpu-total)
FROM 'example-bucket'
WHERE timestamp > dateadd('h', -1, now())
SAMPLE BY 1m;
Ecosystem and support
QuestDB is a younger database. However, QuestDB builds on the immensely popular SQL language and is compatible with the Postgres wire protocol. It also borrows from InfluxDB by implementing InfluxDB line protocol over TCP, a convenient option for fast data ingestion. In addition, QuestDB has a vibrant and supportive community: users get to interact with the engineering team building QuestDB.
InfluxDB has an impressive ecosystem and has been around for a long time. As an older product, InfluxDB is the most popular time-series database.
Conclusion
We have compared InfluxDB and QuestDB, assessing performance and user experience. QuestDB ingests data 3-10 times faster, and many benchmarked queries perform much better.
We believe in the simplicity of SQL to unlock insights from time-series data. Some of the SQL extensions that QuestDB offers, such as SAMPLE BY, can significantly reduce the complexity of queries and improve developer user experience.