Introduction
QuestDB is an open source columnar database that specializes in time series. It offers category-leading ingestion throughput and fast SQL queries with operational simplicity. QuestDB helps reduce operational costs and overcome ingestion bottlenecks, and can greatly simplify overall ingress infrastructure. With a broad array of official support for ingestion protocols like InfluxDB Line Protocol & PostgreSQL Wire Protocol, third-party tools and language clients, it is quick to start.
This introduction provides a brief overview on:
Just want to build? Jump to the quick start guide.
Top QuestDB features
QuestDB is applied within cutting edge use cases around the world.
Developers are most enthusiastic about the following key features:
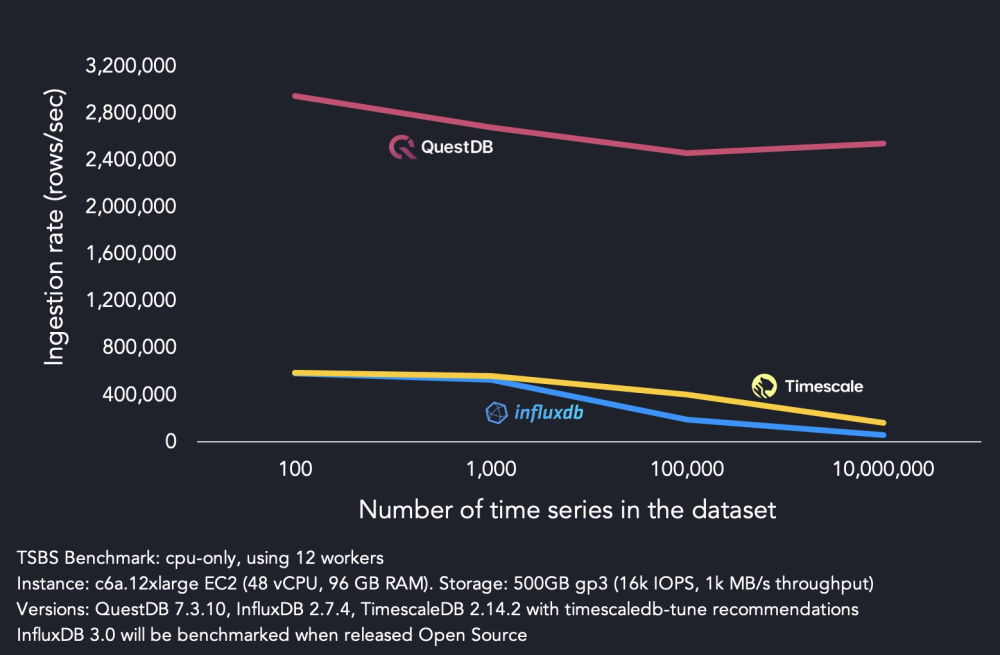
- Massive ingestion handling: With only 4 threads, QuestDB clocks at just under 1M rows per second. If you are running into ingestion speed and throughput bottlenecks using an existing storage engine or time series database, QuestDB can help. For perspective, we've even seen tremendous throughput on a Raspberry Pi.
- Familiar SQL analytics: No obscure domain-specific languages required. Use SQL and query your data using your favourite PostgreSQL-compatible library.
- High performance deduplication & out-of-order indexing with near limitless cardinality: Essential when handling massive, bursting data streams. Official support means that time series and event use cases lose significant complexity. Lots of unique values? High cardinality will not lead to performance degradation.
- Time series SQL extensions: Fast, SIMD-optimized SQL extensions to cruise
through querying and analysis. Greatest hits include:
SAMPLE BYsummarizes data into chunks based on a specified time interval, from a year to a microsecondWHERE INto compress time ranges into concise intervalsLATEST ONfor latest values within multiple series within a tableASOF JOINto associate timestamps between a series based on proximity; no extra indices required
Benefits of QuestDB
Time series data is seen increasingly in use cases across finance, internet of things, e-commerce, security, blockchain, and many emerging industries. As more and more time bound data is generated by an increasing number of clients, having high performance storage at the receiving end of your servers, devices or queues prevents ingestion bottlenecks, simplifies code and reduces costly infrastructure sprawl.
With a specialized time-series database, you don't need to worry about out-of-order data, duplicates, exactly one semantics, frequency of ingestion, or the many other details you will find in real-time streaming scenarios. It's simplified, hyper-fast data ingestion with tremendous efficiency and value.
Queries fuel your dashboards, exchanges, sensors, rockets, applications, and so on. Writing query syntax and building Grafana dashboards should not require the additional complexity of a domain-specific language or cumbersome additional steps for connecting to third party tools.
For QuestDB, apply SQL:
SELECT timestamp, sensorName, tempC
FROM sensors LATEST ON timestamp
PARTITION BY sensorName;
The best way to see whether QuestDB is right for you is to try it out.
Three flavours of QuestDB
QuestDB is built to run where you need it.
The right one depends on your team and use case.
Open source
QuestDB is open source under the Apache 2.0 license. The open source version contains the core product, and for many it is ideal for either a quick proof of concept or a production asset. If you are looking for a strong general purpose columnar database, experiencing an ingestion speed bottle neck or runaway infrastructure costs and want to improve your event or time series data handling, then the open source version is a great place to start.
Enterprise
QuestDB Enterprise offers everything from open source, plus additional features for running QuestDB at larger scale or greater significance. Features within Enterprise include high availability, role based access control, TLS on all protocols, data compression, cold storage and priority support.
Typically, when growing to multiple instances or to mission critical deployments, Enterprise provides an additional layer of official operational tooling with the added benefit of world-class QuestDB support. Enterprise increases the reliability of the already solid open source deployments, while providing better value for compute spend vs. existing engines and methods.
For a breakdown of Enterprise features, see the QuestDB Enterprise page.
Cloud
QuestDB Cloud is the most efficient way to get started with QuestDB. The expert QuestDB team takes care of database operation for you. All QuestDB Cloud deployments run QuestDB Enterprise, meaning that features like compression and high availability are tuned and provided for you.
While many customers, especially those running in highly sensitive contexts such as finance, medicine, rocketry and so on, do prefer to operate storage engines in-house, QuestDB Cloud remains an effective option for those who want a managed storage solution for their high throughput use cases.
Where to next?
You'll be inserting data and generating valuable queries in little time.
First, the quick start guide will get you running.
Choose from one of our premium ingest-only language clients:
From there, you can learn more about what's to offer.
- Ingestion overview want to see all available ingestion options? Checkout the overview.
- Query & SQL Overview learn how to query QuestDB
- Web Console for quick SQL queries, charting and CSV upload/export functionality
- Grafana guide to visualize your data as beautiful and functional charts.
Support
We are happy to help with any question you may have.
The team loves a good performance optimization challenge!
Feel free to reach out using the following channels: